 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-DVAE: Improving Zero-Shot Skeleton-Based Action Recognition by Disentangled Variational Autoencoders
Jul 18, 2024



Existing zero-shot skeleton-based action recognition methods utilize projection networks to learn a shared latent space of skeleton features and semantic embeddings. The inherent imbalance in action recognition datasets, characterized by variable skeleton sequences yet constant class labels, presents significant challenges for alignment. To address the imbalance, we propose SA-DVAE -- Semantic Alignment via Disentangled Variational Autoencoders, a method that first adopts feature disentanglement to separate skeleton features into two independent parts -- one is semantic-related and another is irrelevant -- to better align skeleton and semantic features. We implement this idea via a pair of modality-specific variational autoencoders coupled with a total correction penalty. We conduct experiments on three benchmark datasets: NTU RGB+D, NTU RGB+D 120 and PKU-MMD, and our experimental results show that SA-DAVE produces improved performance over existing methods. The code is available at https://github.com/pha123661/SA-DVAE.
CalliGAN: Style and Structure-aware Chinese Calligraphy Character Generator
May 26, 2020Chinese calligraphy is the writing of Chinese characters as an art form performed with brushes so Chinese characters are rich of shapes and details. Recent studies show that Chinese characters can be generated through image-to-image translation for multiple styles using a single model. We propose a novel method of this approach by incorporating Chinese characters' component information into its model. We also propose an improved network to convert characters to their embedding space. Experiments show that the proposed method generates high-quality Chinese calligraphy characters over state-of-the-art methods measured through numerical evaluations and human subject studies.
Towards a Resilient Machine Learning Classifier -- a Case Study of Ransomware Detection
Mar 13, 2020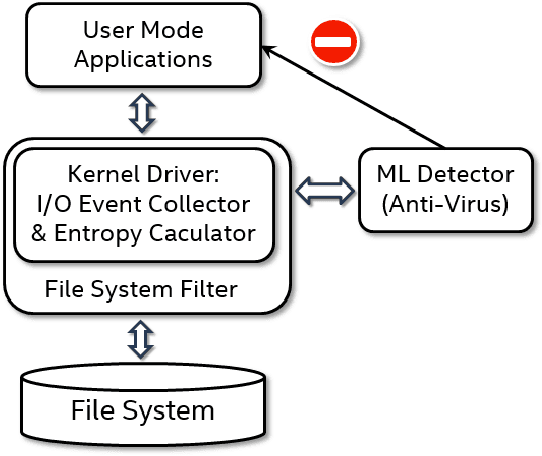
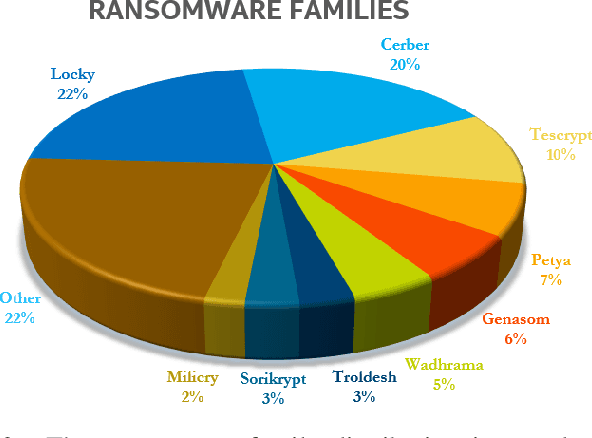
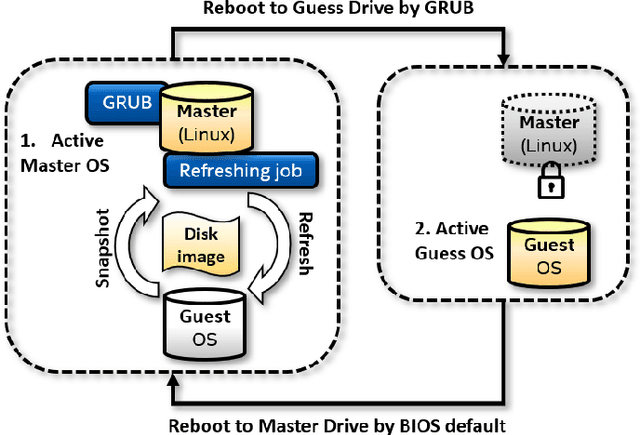
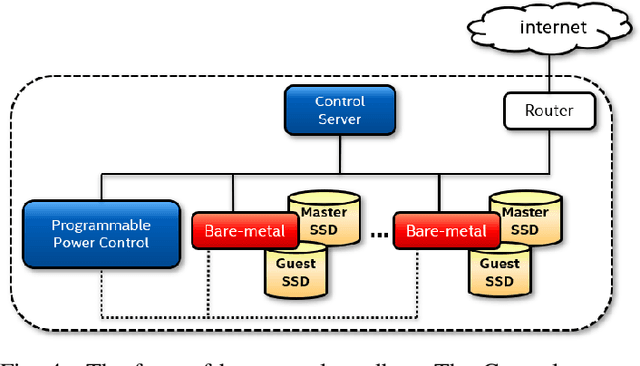
The damage caused by crypto-ransomware, due to encryption, is difficult to revert and cause data losses. In this paper, a machine learning (ML) classifier was built to early detect ransomware (called crypto-ransomware) that uses cryptography by program behavior. If a signature-based detection was missed, a behavior-based detector can be the last line of defense to detect and contain the damages. We find that input/output activities of ransomware and the file-content entropy are unique traits to detect crypto-ransomware. A deep-learning (DL) classifier can detect ransomware with a high accuracy and a low false positive rate. We conduct an adversarial research against the models generated. We use simulated ransomware programs to launch a gray-box analysis to probe the weakness of ML classifiers and to improve model robustness. In addition to accuracy and resiliency, trustworthiness is the other key criteria for a quality detector. Making sure that the correct information was used for inference is important for a security application. The Integrated Gradient method was used to explain the deep learning model and also to reveal why false negatives evade the detection. The approaches to build and to evaluate a real-world detector were demonstrated and discussed.
Video Summarization through Human Detection on a Social Robot
Jan 30, 2019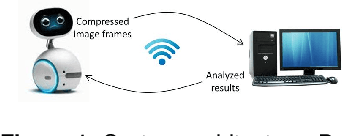


In this paper, we propose a novel video summarization system which captures images via a social robot's camera but processes images on a server. The system helps remote family members easily be aware of their seniors' daily activities via summaries. The system utilizes two vision-based algorithms, one for pose estimation and the other for human detection, to locate people in frames to guide the robot through people tracking and filter out improper frames including the ones without a person or blurred, or with a person but too small or not at the center of the frame. The system utilizes a video summarization method to select keyframes by balancing the representativeness and diversity. We conduct experiments of the system through three in-the-wild studies and evaluate the performance through human subject studies. Experimental results show that the users of the system think the system is promising and useful for their needs.
Towards resilient machine learning for ransomware detection
Dec 21, 2018

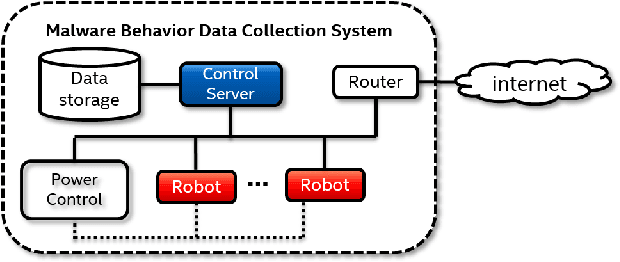
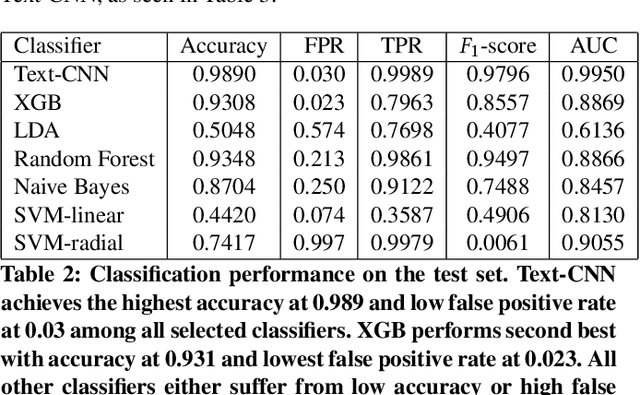
There has been a surge of interest in using machine learning (ML) to automatically detect malware through their dynamic behaviors. These approaches have achieved significant improvement in detection rates and lower false positive rates at large scale compared with traditional malware analysis methods. ML in threat detection has demonstrated to be a good cop to guard platform security. However it is imperative to evaluate - is ML-powered security resilient enough? In this paper, we juxtapose the resiliency and trustworthiness of ML algorithms for security, via a case study of evaluating the resiliency of ransomware detection via the generative adversarial network (GAN). In this case study, we propose to use GAN to automatically produce dynamic features that exhibit generalized malicious behaviors that can reduce the efficacy of black-box ransomware classifiers. We examine the quality of the GAN-generated samples by comparing the statistical similarity of these samples to real ransomware and benign software. Further we investigate the latent subspace where the GAN-generated samples lie and explore reasons why such samples cause a certain class of ransomware classifiers to degrade in performance. Our focus is to emphasize necessary defense improvement in ML-based approaches for ransomware detection before deployment in the wild. Our results and discoveries should pose relevant questions for defenders such as how ML models can be made more resilient for robust enforcement of security objectives.
A Hybrid Word-Character Approach to Abstractive Summarization
Sep 08, 2018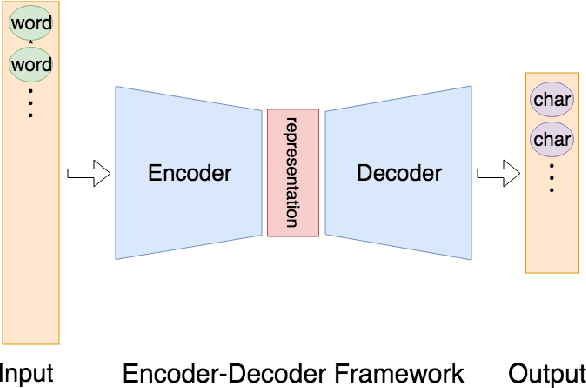
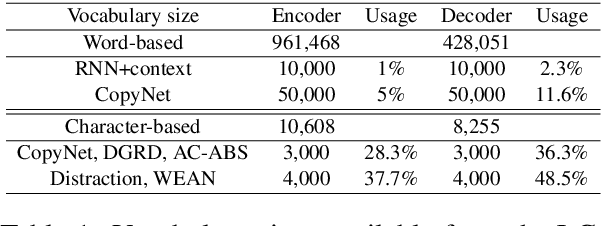
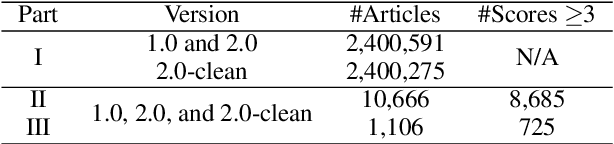
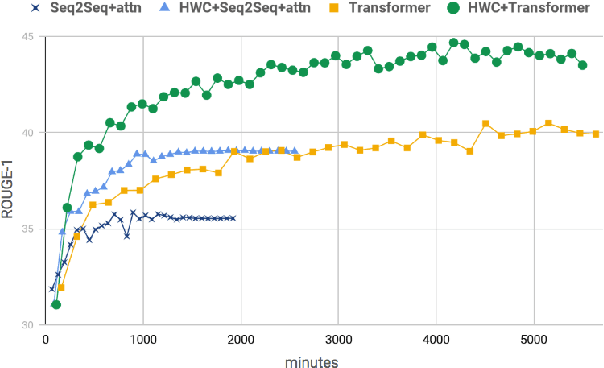
Automatic abstractive text summarization is an important and challenging research topic of natural language processing. Among many widely used languages, the Chinese language has a special property that a Chinese character contains rich information comparable to a word. Existing Chinese text summarization methods, either adopt totally character-based or word-based representations, fail to fully exploit the information carried by both representations. To accurately capture the essence of articles, we propose a hybrid word-character approach (HWC) which preserves the advantages of both word-based and character-based representations. We evaluate the advantage of the proposed HWC approach by applying it to two existing methods, and discover that it generates state-of-the-art performance with a margin of 24 ROUGE points on a widely used dataset LCSTS. In addition, we find an issue contained in the LCSTS dataset and offer a script to remove overlapping pairs (a summary and a short text) to create a clean dataset for the community. The proposed HWC approach also generates the best performance on the new, clean LCSTS dataset.
Semi-supervised classification for dynamic Android malware detection
Apr 19, 2017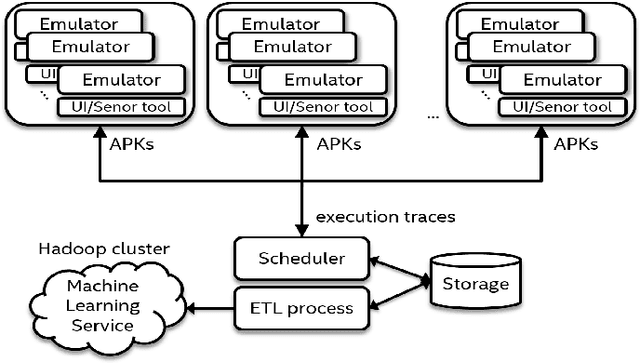

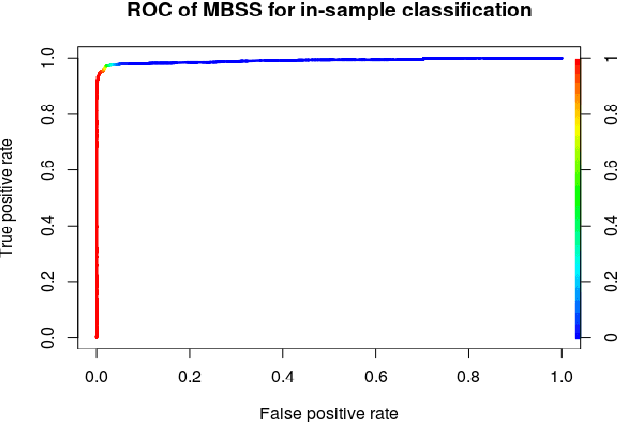
A growing number of threats to Android phones creates challenges for malware detection. Manually labeling the samples into benign or different malicious families requires tremendous human efforts, while it is comparably easy and cheap to obtain a large amount of unlabeled APKs from various sources. Moreover, the fast-paced evolution of Android malware continuously generates derivative malware families. These families often contain new signatures, which can escape detection when using static analysis. These practical challenges can also cause traditional supervised machine learning algorithms to degrade in performance. In this paper, we propose a framework that uses model-based semi-supervised (MBSS) classification scheme on the dynamic Android API call logs. The semi-supervised approach efficiently uses the labeled and unlabeled APKs to estimate a finite mixture model of Gaussian distributions via conditional expectation-maximization and efficiently detects malwares during out-of-sample testing. We compare MBSS with the popular malware detection classifiers such as support vector machine (SVM), $k$-nearest neighbor (kNN) and linear discriminant analysis (LDA). Under the ideal classification setting, MBSS has competitive performance with 98\% accuracy and very low false positive rate for in-sample classification. For out-of-sample testing, the out-of-sample test data exhibit similar behavior of retrieving phone information and sending to the network, compared with in-sample training set. When this similarity is strong, MBSS and SVM with linear kernel maintain 90\% detection rate while $k$NN and LDA suffer great performance degradation. When this similarity is slightly weaker, all classifiers degrade in performance, but MBSS still performs significantly better than other classifiers.
Learning a No-Reference Quality Metric for Single-Image Super-Resolution
Dec 18, 2016



Numerous single-image super-resolution algorithms have been proposed in the literature, but few studies address the problem of performance evaluation based on visual perception. While most super-resolution images are evaluated by fullreference metrics, the effectiveness is not clear and the required ground-truth images are not always available in practice. To address these problems, we conduct human subject studies using a large set of super-resolution images and propose a no-reference metric learned from visual perceptual scores. Specifically, we design three types of low-level statistical features in both spatial and frequency domains to quantify super-resolved artifacts, and learn a two-stage regression model to predict the quality scores of super-resolution images without referring to ground-truth images. Extensive experimental results show that the proposed metric is effective and efficient to assess the quality of super-resolution images based on human perception.