 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSA-DVAE: Improving Zero-Shot Skeleton-Based Action Recognition by Disentangled Variational Autoencoders
Jul 18, 2024



Existing zero-shot skeleton-based action recognition methods utilize projection networks to learn a shared latent space of skeleton features and semantic embeddings. The inherent imbalance in action recognition datasets, characterized by variable skeleton sequences yet constant class labels, presents significant challenges for alignment. To address the imbalance, we propose SA-DVAE -- Semantic Alignment via Disentangled Variational Autoencoders, a method that first adopts feature disentanglement to separate skeleton features into two independent parts -- one is semantic-related and another is irrelevant -- to better align skeleton and semantic features. We implement this idea via a pair of modality-specific variational autoencoders coupled with a total correction penalty. We conduct experiments on three benchmark datasets: NTU RGB+D, NTU RGB+D 120 and PKU-MMD, and our experimental results show that SA-DAVE produces improved performance over existing methods. The code is available at https://github.com/pha123661/SA-DVAE.
Context-Dependent Semantic Parsing for Temporal Relation Extraction
Dec 02, 2021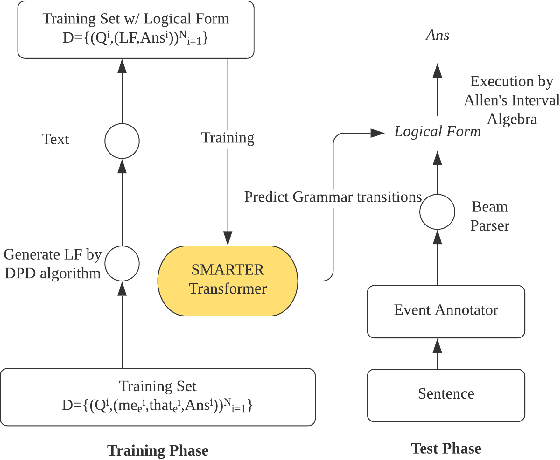

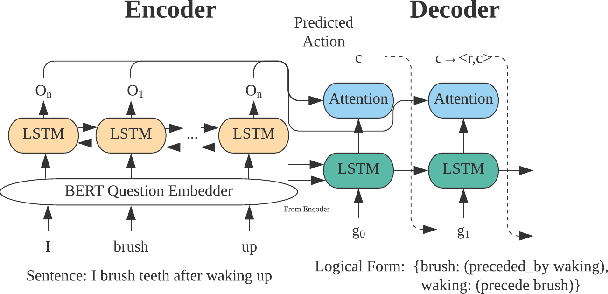
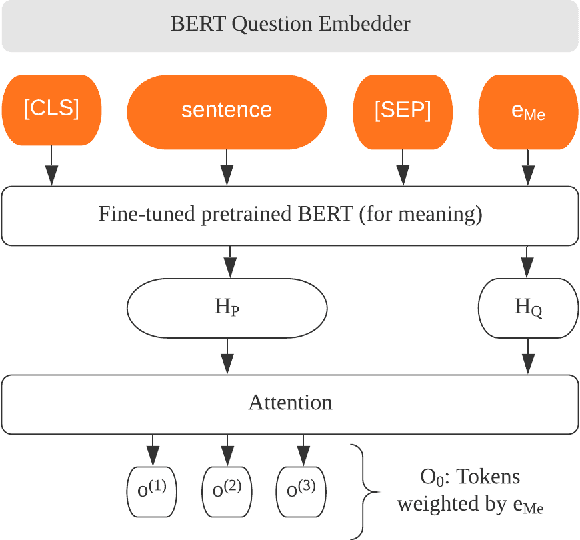
Extracting temporal relations among events from unstructured text has extensive applications, such as temporal reasoning and question answering. While it is difficult, recent development of Neural-symbolic methods has shown promising results on solving similar tasks. Current temporal relation extraction methods usually suffer from limited expressivity and inconsistent relation inference. For example, in TimeML annotations, the concept of intersection is absent. Additionally, current methods do not guarantee the consistency among the predicted annotations. In this work, we propose SMARTER, a neural semantic parser, to extract temporal information in text effectively. SMARTER parses natural language to an executable logical form representation, based on a custom typed lambda calculus. In the training phase, dynamic programming on denotations (DPD) technique is used to provide weak supervision on logical forms. In the inference phase, SMARTER generates a temporal relation graph by executing the logical form. As a result, our neural semantic parser produces logical forms capturing the temporal information of text precisely. The accurate logical form representations of an event given the context ensure the correctness of the extracted relations.
CalliGAN: Style and Structure-aware Chinese Calligraphy Character Generator
May 26, 2020Chinese calligraphy is the writing of Chinese characters as an art form performed with brushes so Chinese characters are rich of shapes and details. Recent studies show that Chinese characters can be generated through image-to-image translation for multiple styles using a single model. We propose a novel method of this approach by incorporating Chinese characters' component information into its model. We also propose an improved network to convert characters to their embedding space. Experiments show that the proposed method generates high-quality Chinese calligraphy characters over state-of-the-art methods measured through numerical evaluations and human subject studies.
Human-AI Co-Learning for Data-Driven AI
Oct 28, 2019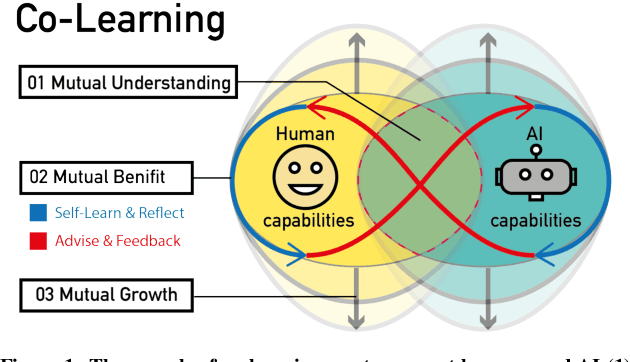
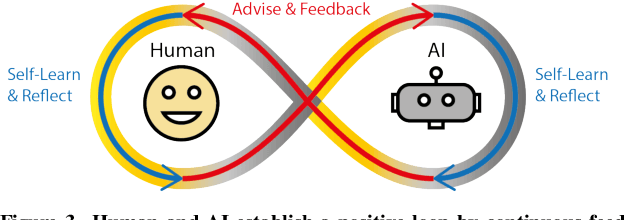
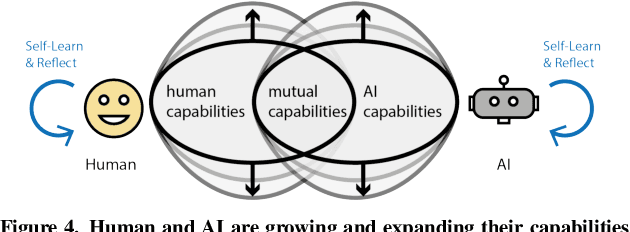
Human and AI are increasingly interacting and collaborating to accomplish various complex tasks in the context of diverse application domains (e.g., healthcare, transportation, and creative design). Two dynamic, learning entities (AI and human) have distinct mental model, expertise, and ability; such fundamental difference/mismatch offers opportunities for bringing new perspectives to achieve better results. However, this mismatch can cause unexpected failure and result in serious consequences. While recent research has paid much attention to enhancing interpretability or explainability to allow machine to explain how it makes a decision for supporting humans, this research argues that there is urging the need for both human and AI should develop specific, corresponding ability to interact and collaborate with each other to form a human-AI team to accomplish superior results. This research introduces a conceptual framework called "Co-Learning," in which people can learn with/from and grow with AI partners over time. We characterize three key concepts of co-learning: "mutual understanding," "mutual benefits," and "mutual growth" for facilitating human-AI collaboration on complex problem solving. We will present proof-of-concepts to investigate whether and how our approach can help human-AI team to understand and benefit each other, and ultimately improve productivity and creativity on creative problem domains. The insights will contribute to the design of Human-AI collaboration.
Video Summarization through Human Detection on a Social Robot
Jan 30, 2019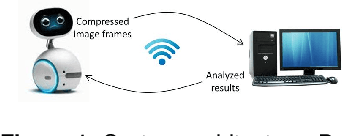
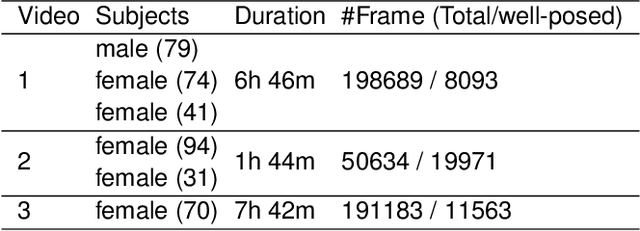


In this paper, we propose a novel video summarization system which captures images via a social robot's camera but processes images on a server. The system helps remote family members easily be aware of their seniors' daily activities via summaries. The system utilizes two vision-based algorithms, one for pose estimation and the other for human detection, to locate people in frames to guide the robot through people tracking and filter out improper frames including the ones without a person or blurred, or with a person but too small or not at the center of the frame. The system utilizes a video summarization method to select keyframes by balancing the representativeness and diversity. We conduct experiments of the system through three in-the-wild studies and evaluate the performance through human subject studies. Experimental results show that the users of the system think the system is promising and useful for their needs.