 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Approach to Localizing Multi-level Airway Collapse Based on Snoring Sounds
Aug 28, 2024This study investigates the application of machine/deep learning to classify snoring sounds excited at different levels of the upper airway in patients with obstructive sleep apnea (OSA) using data from drug-induced sleep endoscopy (DISE). The snoring sounds of 39 subjects were analyzed and labeled according to the Velum, Oropharynx, Tongue Base, and Epiglottis (VOTE) classification system. The dataset, comprising 5,173 one-second segments, was used to train and test models, including Support Vector Machine (SVM), Bidirectional Long Short-Term Memory (BiLSTM), and ResNet-50. The ResNet-50, a convolutional neural network (CNN), showed the best overall performance in classifying snoring acoustics, particularly in identifying multi-level obstructions. The study emphasizes the potential of integrating snoring acoustics with deep learning to improve the diagnosis and treatment of OSA. However, challenges such as limited sample size, data imbalance, and differences between pharmacologically induced and natural snoring sounds were noted, suggesting further research to enhance model accuracy and generalizability.
A Hybrid Word-Character Approach to Abstractive Summarization
Sep 08, 2018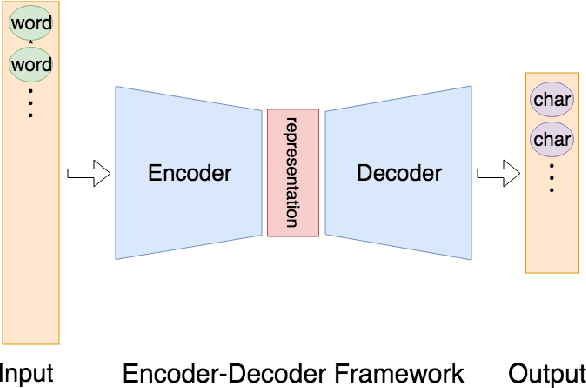
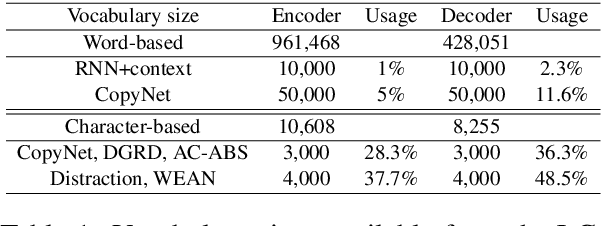
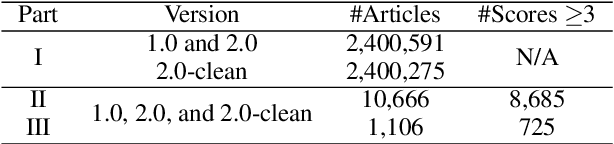
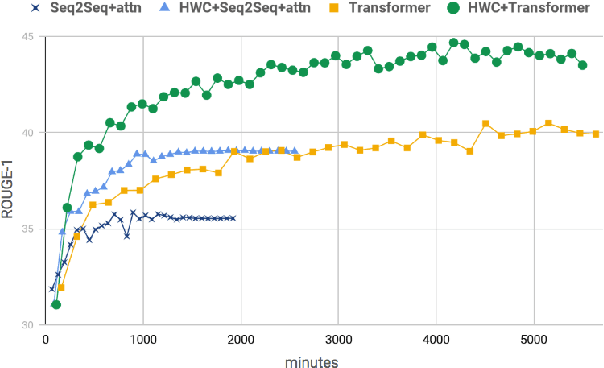
Automatic abstractive text summarization is an important and challenging research topic of natural language processing. Among many widely used languages, the Chinese language has a special property that a Chinese character contains rich information comparable to a word. Existing Chinese text summarization methods, either adopt totally character-based or word-based representations, fail to fully exploit the information carried by both representations. To accurately capture the essence of articles, we propose a hybrid word-character approach (HWC) which preserves the advantages of both word-based and character-based representations. We evaluate the advantage of the proposed HWC approach by applying it to two existing methods, and discover that it generates state-of-the-art performance with a margin of 24 ROUGE points on a widely used dataset LCSTS. In addition, we find an issue contained in the LCSTS dataset and offer a script to remove overlapping pairs (a summary and a short text) to create a clean dataset for the community. The proposed HWC approach also generates the best performance on the new, clean LCSTS dataset.