 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLORTSAR: Low-Rank Transformer for Skeleton-based Action Recognition
Jul 19, 2024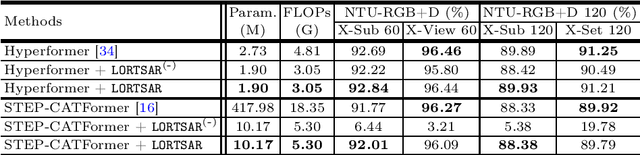
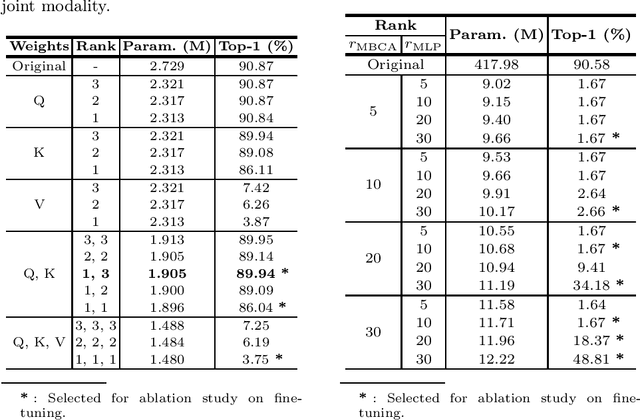
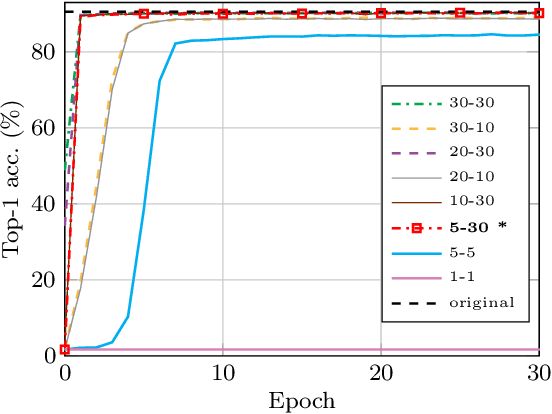
The complexity of state-of-the-art Transformer-based models for skeleton-based action recognition poses significant challenges in terms of computational efficiency and resource utilization. In this paper, we explore the application of Singular Value Decomposition (SVD) to effectively reduce the model sizes of these pre-trained models, aiming to minimize their resource consumption while preserving accuracy. Our method, LORTSAR (LOw-Rank Transformer for Skeleton-based Action Recognition), also includes a fine-tuning step to compensate for any potential accuracy degradation caused by model compression, and is applied to two leading Transformer-based models, "Hyperformer" and "STEP-CATFormer". Experimental results on the "NTU RGB+D" and "NTU RGB+D 120" datasets show that our method can reduce the number of model parameters substantially with negligible degradation or even performance increase in recognition accuracy. This confirms that SVD combined with post-compression fine-tuning can boost model efficiency, paving the way for more sustainable, lightweight, and high-performance technologies in human action recognition.