 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyword Spotting
Keyword spotting (KWS) is an important technique for speech applications, which enables users to activate devices by speaking a keyword phrase.
Papers and Code
Chameleon: A MatMul-Free Temporal Convolutional Network Accelerator for End-to-End Few-Shot and Continual Learning from Sequential Data
May 30, 2025On-device learning at the edge enables low-latency, private personalization with improved long-term robustness and reduced maintenance costs. Yet, achieving scalable, low-power end-to-end on-chip learning, especially from real-world sequential data with a limited number of examples, is an open challenge. Indeed, accelerators supporting error backpropagation optimize for learning performance at the expense of inference efficiency, while simplified learning algorithms often fail to reach acceptable accuracy targets. In this work, we present Chameleon, leveraging three key contributions to solve these challenges. (i) A unified learning and inference architecture supports few-shot learning (FSL), continual learning (CL) and inference at only 0.5% area overhead to the inference logic. (ii) Long temporal dependencies are efficiently captured with temporal convolutional networks (TCNs), enabling the first demonstration of end-to-end on-chip FSL and CL on sequential data and inference on 16-kHz raw audio. (iii) A dual-mode, matrix-multiplication-free compute array allows either matching the power consumption of state-of-the-art inference-only keyword spotting (KWS) accelerators or enabling $4.3\times$ higher peak GOPS. Fabricated in 40-nm CMOS, Chameleon sets new accuracy records on Omniglot for end-to-end on-chip FSL (96.8%, 5-way 1-shot, 98.8%, 5-way 5-shot) and CL (82.2% final accuracy for learning 250 classes with 10 shots), while maintaining an inference accuracy of 93.3% on the 12-class Google Speech Commands dataset at an extreme-edge power budget of 3.1 $\mu$W.
Mass-Spring Models for Passive Keyword Spotting: A Springtronics Approach
Apr 08, 2025Mechanical systems played a foundational role in computing history, and have regained interest due to their unique properties, such as low damping and the ability to process mechanical signals without transduction. However, recent efforts have primarily focused on elementary computations, implemented in systems based on pre-defined reservoirs, or in periodic systems such as arrays of buckling beams. Here, we numerically demonstrate a passive mechanical system -- in the form of a nonlinear mass-spring model -- that tackles a real-world benchmark for keyword spotting in speech signals. The model is organized in a hierarchical architecture combining feature extraction and continuous-time convolution, with each individual stage tailored to the physics of the considered mass-spring systems. For each step in the computation, a subsystem is designed by combining a small set of low-order polynomial potentials. These potentials act as fundamental components that interconnect a network of masses. In analogy to electronic circuit design, where complex functional circuits are constructed by combining basic components into hierarchical designs, we refer to this framework as springtronics. We introduce springtronic systems with hundreds of degrees of freedom, achieving speech classification accuracy comparable to existing sub-mW electronic systems.
Hardware/Software Co-Design of RISC-V Extensions for Accelerating Sparse DNNs on FPGAs
Apr 28, 2025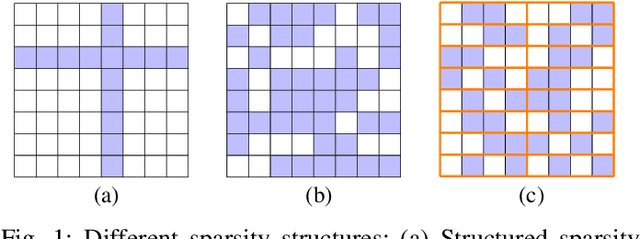
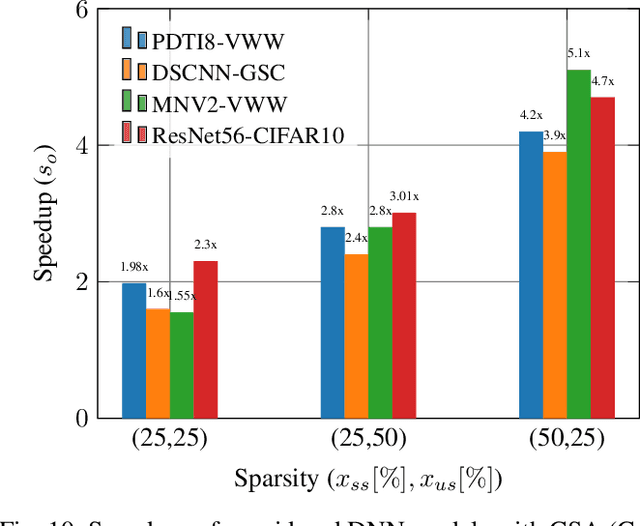
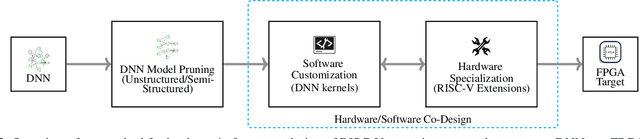
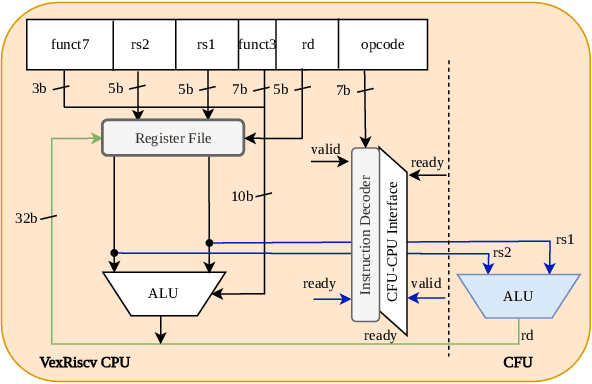
The customizability of RISC-V makes it an attractive choice for accelerating deep neural networks (DNNs). It can be achieved through instruction set extensions and corresponding custom functional units. Yet, efficiently exploiting these opportunities requires a hardware/software co-design approach in which the DNN model, software, and hardware are designed together. In this paper, we propose novel RISC-V extensions for accelerating DNN models containing semi-structured and unstructured sparsity. While the idea of accelerating structured and unstructured pruning is not new, our novel design offers various advantages over other designs. To exploit semi-structured sparsity, we take advantage of the fine-grained (bit-level) configurability of FPGAs and suggest reserving a few bits in a block of DNN weights to encode the information about sparsity in the succeeding blocks. The proposed custom functional unit utilizes this information to skip computations. To exploit unstructured sparsity, we propose a variable cycle sequential multiply-and-accumulate unit that performs only as many multiplications as the non-zero weights. Our implementation of unstructured and semi-structured pruning accelerators can provide speedups of up to a factor of 3 and 4, respectively. We then propose a combined design that can accelerate both types of sparsities, providing speedups of up to a factor of 5. Our designs consume a small amount of additional FPGA resources such that the resulting co-designs enable the acceleration of DNNs even on small FPGAs. We benchmark our designs on standard TinyML applications such as keyword spotting, image classification, and person detection.
Towards efficient keyword spotting using spike-based time difference encoders
Mar 19, 2025Keyword spotting in edge devices is becoming increasingly important as voice-activated assistants are widely used. However, its deployment is often limited by the extreme low-power constraints of the target embedded systems. Here, we explore the Temporal Difference Encoder (TDE) performance in keyword spotting. This recent neuron model encodes the time difference in instantaneous frequency and spike count to perform efficient keyword spotting with neuromorphic processors. We use the TIdigits dataset of spoken digits with a formant decomposition and rate-based encoding into spikes. We compare three Spiking Neural Networks (SNNs) architectures to learn and classify spatio-temporal signals. The proposed SNN architectures are made of three layers with variation in its hidden layer composed of either (1) feedforward TDE, (2) feedforward Current-Based Leaky Integrate-and-Fire (CuBa-LIF), or (3) recurrent CuBa-LIF neurons. We first show that the spike trains of the frequency-converted spoken digits have a large amount of information in the temporal domain, reinforcing the importance of better exploiting temporal encoding for such a task. We then train the three SNNs with the same number of synaptic weights to quantify and compare their performance based on the accuracy and synaptic operations. The resulting accuracy of the feedforward TDE network (89%) is higher than the feedforward CuBa-LIF network (71%) and close to the recurrent CuBa-LIF network (91%). However, the feedforward TDE-based network performs 92% fewer synaptic operations than the recurrent CuBa-LIF network with the same amount of synapses. In addition, the results of the TDE network are highly interpretable and correlated with the frequency and timescale features of the spoken keywords in the dataset. Our findings suggest that the TDE is a promising neuron model for scalable event-driven processing of spatio-temporal patterns.
Eventprop training for efficient neuromorphic applications
Mar 06, 2025Neuromorphic computing can reduce the energy requirements of neural networks and holds the promise to `repatriate' AI workloads back from the cloud to the edge. However, training neural networks on neuromorphic hardware has remained elusive. Here, we instead present a pipeline for training spiking neural networks on GPUs, using the efficient event-driven Eventprop algorithm implemented in mlGeNN, and deploying them on Intel's Loihi 2 neuromorphic chip. Our benchmarking on keyword spotting tasks indicates that there is almost no loss in accuracy between GPU and Loihi 2 implementations and that classifying a sample on Loihi 2 is up to 10X faster and uses 200X less energy than on an NVIDIA Jetson Orin Nano.
Vocal Tract Length Warped Features for Spoken Keyword Spotting
Jan 07, 2025In this paper, we propose several methods that incorporate vocal tract length (VTL) warped features for spoken keyword spotting (KWS). The first method, VTL-independent KWS, involves training a single deep neural network (DNN) that utilizes VTL features with various warping factors. During training, a specific VTL feature is randomly selected per epoch, allowing the exploration of VTL variations. During testing, the VTL features with different warping factors of a test utterance are scored against the DNN and combined with equal weight. In the second method scores the conventional features of a test utterance (without VTL warping) against the DNN. The third method, VTL-concatenation KWS, concatenates VTL warped features to form high-dimensional features for KWS. Evaluations carried out on the English Google Command dataset demonstrate that the proposed methods improve the accuracy of KWS.
Noise-Agnostic Multitask Whisper Training for Reducing False Alarm Errors in Call-for-Help Detection
Jan 20, 2025Keyword spotting is often implemented by keyword classifier to the encoder in acoustic models, enabling the classification of predefined or open vocabulary keywords. Although keyword spotting is a crucial task in various applications and can be extended to call-for-help detection in emergencies, however, the previous method often suffers from scalability limitations due to retraining required to introduce new keywords or adapt to changing contexts. We explore a simple yet effective approach that leverages off-the-shelf pretrained ASR models to address these challenges, especially in call-for-help detection scenarios. Furthermore, we observed a substantial increase in false alarms when deploying call-for-help detection system in real-world scenarios due to noise introduced by microphones or different environments. To address this, we propose a novel noise-agnostic multitask learning approach that integrates a noise classification head into the ASR encoder. Our method enhances the model's robustness to noisy environments, leading to a significant reduction in false alarms and improved overall call-for-help performance. Despite the added complexity of multitask learning, our approach is computationally efficient and provides a promising solution for call-for-help detection in real-world scenarios.
Phoneme-Level Contrastive Learning for User-Defined Keyword Spotting with Flexible Enrollment
Dec 30, 2024
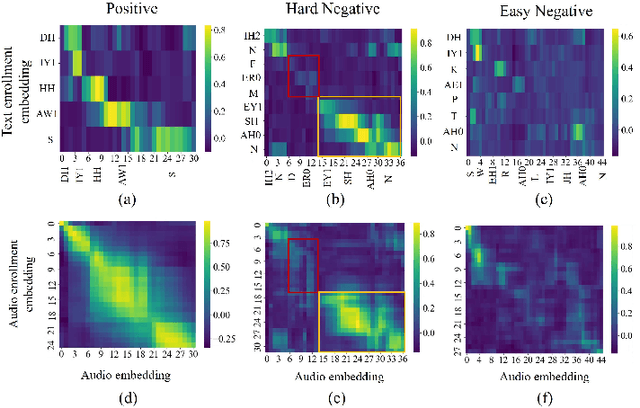


User-defined keyword spotting (KWS) enhances the user experience by allowing individuals to customize keywords. However, in open-vocabulary scenarios, most existing methods commonly suffer from high false alarm rates with confusable words and are limited to either audio-only or text-only enrollment. Therefore, in this paper, we first explore the model's robustness against confusable words. Specifically, we propose Phoneme-Level Contrastive Learning (PLCL), which refines and aligns query and source feature representations at the phoneme level. This method enhances the model's disambiguation capability through fine-grained positive and negative comparisons for more accurate alignment, and it is generalizable to jointly optimize both audio-text and audio-audio matching, adapting to various enrollment modes. Furthermore, we maintain a context-agnostic phoneme memory bank to construct confusable negatives for data augmentation. Based on this, a third-category discriminator is specifically designed to distinguish hard negatives. Overall, we develop a robust and flexible KWS system, supporting different modality enrollment methods within a unified framework. Verified on the LibriPhrase dataset, the proposed approach achieves state-of-the-art performance.
Text-Aware Adapter for Few-Shot Keyword Spotting
Dec 24, 2024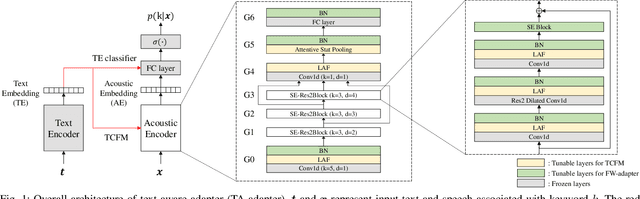
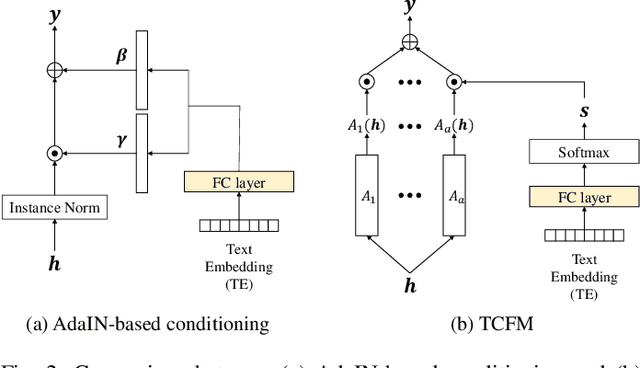
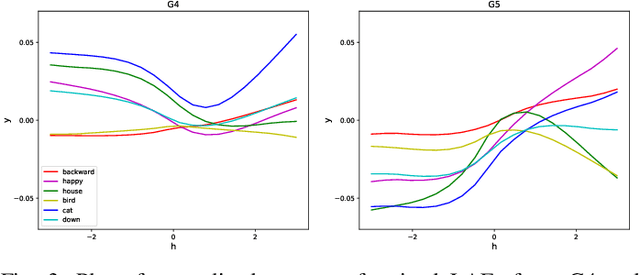
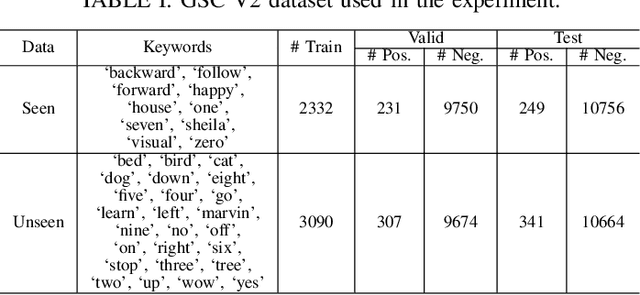
Recent advances in flexible keyword spotting (KWS) with text enrollment allow users to personalize keywords without uttering them during enrollment. However, there is still room for improvement in target keyword performance. In this work, we propose a novel few-shot transfer learning method, called text-aware adapter (TA-adapter), designed to enhance a pre-trained flexible KWS model for specific keywords with limited speech samples. To adapt the acoustic encoder, we leverage a jointly pre-trained text encoder to generate a text embedding that acts as a representative vector for the keyword. By fine-tuning only a small portion of the network while keeping the core components' weights intact, the TA-adapter proves highly efficient for few-shot KWS, enabling a seamless return to the original pre-trained model. In our experiments, the TA-adapter demonstrated significant performance improvements across 35 distinct keywords from the Google Speech Commands V2 dataset, with only a 0.14% increase in the total number of parameters.
Streaming Keyword Spotting Boosted by Cross-layer Discrimination Consistency
Dec 17, 2024



Connectionist Temporal Classification (CTC), a non-autoregressive training criterion, is widely used in online keyword spotting (KWS). However, existing CTC-based KWS decoding strategies either rely on Automatic Speech Recognition (ASR), which performs suboptimally due to its broad search over the acoustic space without keyword-specific optimization, or on KWS-specific decoding graphs, which are complex to implement and maintain. In this work, we propose a streaming decoding algorithm enhanced by Cross-layer Discrimination Consistency (CDC), tailored for CTC-based KWS. Specifically, we introduce a streamlined yet effective decoding algorithm capable of detecting the start of the keyword at any arbitrary position. Furthermore, we leverage discrimination consistency information across layers to better differentiate between positive and false alarm samples. Our experiments on both clean and noisy Hey Snips datasets show that the proposed streaming decoding strategy outperforms ASR-based and graph-based KWS baselines. The CDC-boosted decoding further improves performance, yielding an average absolute recall improvement of 6.8% and a 46.3% relative reduction in the miss rate compared to the graph-based KWS baseline, with a very low false alarm rate of 0.05 per hour.