 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Source Separation
Music source separation is the process of separating individual sound sources from a mixed audio signal.
Papers and Code
Classical Guitar Duet Separation using GuitarDuets -- a Dataset of Real and Synthesized Guitar Recordings
Jul 01, 2025Recent advancements in music source separation (MSS) have focused in the multi-timbral case, with existing architectures tailored for the separation of distinct instruments, overlooking thus the challenge of separating instruments with similar timbral characteristics. Addressing this gap, our work focuses on monotimbral MSS, specifically within the context of classical guitar duets. To this end, we introduce the GuitarDuets dataset, featuring a combined total of approximately three hours of real and synthesized classical guitar duet recordings, as well as note-level annotations of the synthesized duets. We perform an extensive cross-dataset evaluation by adapting Demucs, a state-of-the-art MSS architecture, to monotimbral source separation. Furthermore, we develop a joint permutation-invariant transcription and separation framework, to exploit note event predictions as auxiliary information. Our results indicate that utilizing both the real and synthesized subsets of GuitarDuets leads to improved separation performance in an independently recorded test set compared to utilizing solely one subset. We also find that while the availability of ground-truth note labels greatly helps the performance of the separation network, the predicted note estimates result only in marginal improvement. Finally, we discuss the behavior of commonly utilized metrics, such as SDR and SI-SDR, in the context of monotimbral MSS.
* In Proceedings of the 25th International Society for Music Information Retrieval Conference (ISMIR 2024), San Francisco, USA, November 2024. The dataset is available at: https://zenodo.org/records/12802440
Is MixIT Really Unsuitable for Correlated Sources? Exploring MixIT for Unsupervised Pre-training in Music Source Separation
May 12, 2025In music source separation (MSS), obtaining isolated sources or stems is highly costly, making pre-training on unlabeled data a promising approach. Although source-agnostic unsupervised learning like mixture-invariant training (MixIT) has been explored in general sound separation, they have been largely overlooked in MSS due to its implicit assumption of source independence. We hypothesize, however, that the difficulty of applying MixIT to MSS arises from the ill-posed nature of MSS itself, where stem definitions are application-dependent and models lack explicit knowledge of what should or should not be separated, rather than from high inter-source correlation. While MixIT does not assume any source model and struggles with such ambiguities, our preliminary experiments show that it can still separate instruments to some extent, suggesting its potential for unsupervised pre-training. Motivated by these insights, this study investigates MixIT-based pre-training for MSS. We first pre-train a model on in-the-wild, unlabeled data from the Free Music Archive using MixIT, and then fine-tune it on MUSDB18 with supervision. Using the band-split TF-Locoformer, one of the state-of-the-art MSS models, we demonstrate that MixIT-based pre-training improves the performance over training from scratch.
Music Source Restoration
May 27, 2025We introduce Music Source Restoration (MSR), a novel task addressing the gap between idealized source separation and real-world music production. Current Music Source Separation (MSS) approaches assume mixtures are simple sums of sources, ignoring signal degradations employed during music production like equalization, compression, and reverb. MSR models mixtures as degraded sums of individually degraded sources, with the goal of recovering original, undegraded signals. Due to the lack of data for MSR, we present RawStems, a dataset annotation of 578 songs with unprocessed source signals organized into 8 primary and 17 secondary instrument groups, totaling 354.13 hours. To the best of our knowledge, RawStems is the first dataset that contains unprocessed music stems with hierarchical categories. We consider spectral filtering, dynamic range compression, harmonic distortion, reverb and lossy codec as possible degradations, and establish U-Former as a baseline method, demonstrating the feasibility of MSR on our dataset. We release the RawStems dataset annotations, degradation simulation pipeline, training code and pre-trained models to be publicly available.
Training-Free Multi-Step Audio Source Separation
May 26, 2025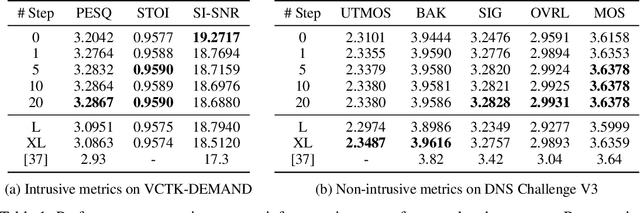
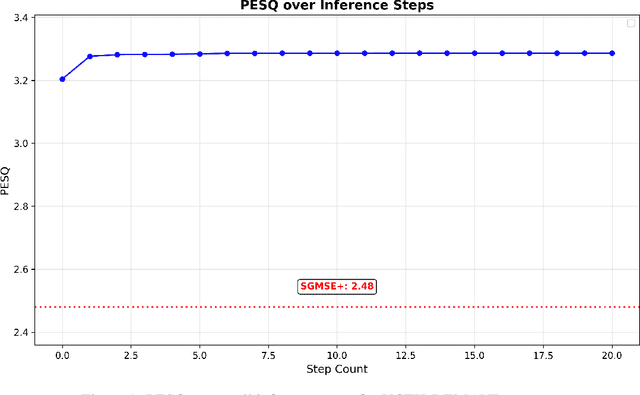
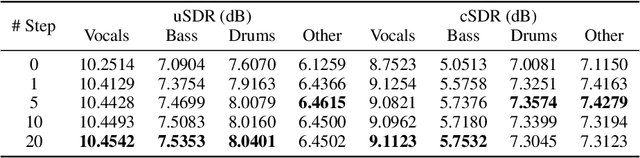
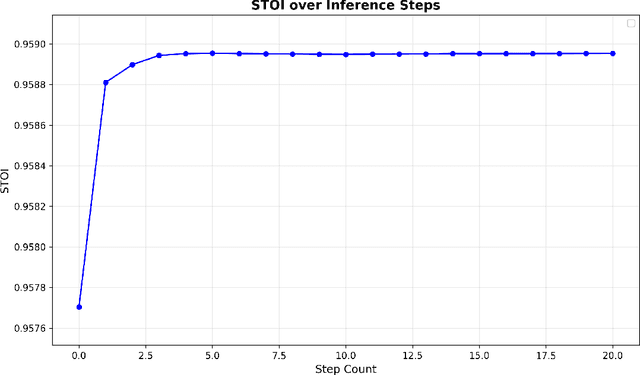
Audio source separation aims to separate a mixture into target sources. Previous audio source separation systems usually conduct one-step inference, which does not fully explore the separation ability of models. In this work, we reveal that pretrained one-step audio source separation models can be leveraged for multi-step separation without additional training. We propose a simple yet effective inference method that iteratively applies separation by optimally blending the input mixture with the previous step's separation result. At each step, we determine the optimal blending ratio by maximizing a metric. We prove that our method always yield improvement over one-step inference, provide error bounds based on model smoothness and metric robustness, and provide theoretical analysis connecting our method to denoising along linear interpolation paths between noise and clean distributions, a property we link to denoising diffusion bridge models. Our approach effectively delivers improved separation performance as a "free lunch" from existing models. Our empirical results demonstrate that our multi-step separation approach consistently outperforms one-step inference across both speech enhancement and music source separation tasks, and can achieve scaling performance similar to training a larger model, using more data, or in some cases employing a multi-step training objective. These improvements appear not only on the optimization metric during multi-step inference, but also extend to nearly all non-optimized metrics (with one exception). We also discuss limitations of our approach and directions for future research.
Source Separation of Small Classical Ensembles: Challenges and Opportunities
May 23, 2025Musical (MSS) source separation of western popular music using non-causal deep learning can be very effective. In contrast, MSS for classical music is an unsolved problem. Classical ensembles are harder to separate than popular music because of issues such as the inherent greater variation in the music; the sparsity of recordings with ground truth for supervised training; and greater ambiguity between instruments. The Cadenza project has been exploring MSS for classical music. This is being done so music can be remixed to improve listening experiences for people with hearing loss. To enable the work, a new database of synthesized woodwind ensembles was created to overcome instrumental imbalances in the EnsembleSet. For the MSS, a set of ConvTasNet models was used with each model being trained to extract a string or woodwind instrument. ConvTasNet was chosen because it enabled both causal and non-causal approaches to be tested. Non-causal approaches have dominated MSS work and are useful for recorded music, but for live music or processing on hearing aids, causal signal processing is needed. The MSS performance was evaluated on the two small datasets (Bach10 and URMP) of real instrument recordings where the ground-truth is available. The performances of the causal and non-causal systems were similar. Comparing the average Signal-to-Distortion (SDR) of the synthesized validation set (6.2 dB causal; 6.9 non-causal), to the real recorded evaluation set (0.3 dB causal, 0.4 dB non-causal), shows that mismatch between synthesized and recorded data is a problem. Future work needs to either gather more real recordings that can be used for training, or to improve the realism and diversity of the synthesized recordings to reduce the mismatch...
Solving Copyright Infringement on Short Video Platforms: Novel Datasets and an Audio Restoration Deep Learning Pipeline
Apr 30, 2025



Short video platforms like YouTube Shorts and TikTok face significant copyright compliance challenges, as infringers frequently embed arbitrary background music (BGM) to obscure original soundtracks (OST) and evade content originality detection. To tackle this issue, we propose a novel pipeline that integrates Music Source Separation (MSS) and cross-modal video-music retrieval (CMVMR). Our approach effectively separates arbitrary BGM from the original OST, enabling the restoration of authentic video audio tracks. To support this work, we introduce two domain-specific datasets: OASD-20K for audio separation and OSVAR-160 for pipeline evaluation. OASD-20K contains 20,000 audio clips featuring mixed BGM and OST pairs, while OSVAR160 is a unique benchmark dataset comprising 1,121 video and mixed-audio pairs, specifically designed for short video restoration tasks. Experimental results demonstrate that our pipeline not only removes arbitrary BGM with high accuracy but also restores OSTs, ensuring content integrity. This approach provides an ethical and scalable solution to copyright challenges in user-generated content on short video platforms.
MGE-LDM: Joint Latent Diffusion for Simultaneous Music Generation and Source Extraction
May 29, 2025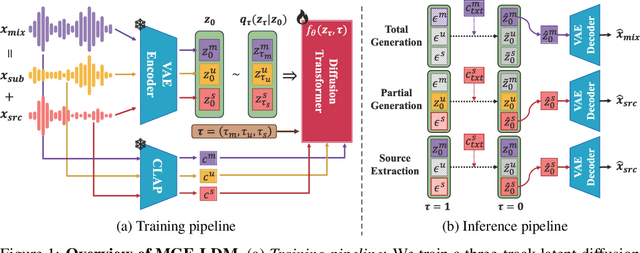
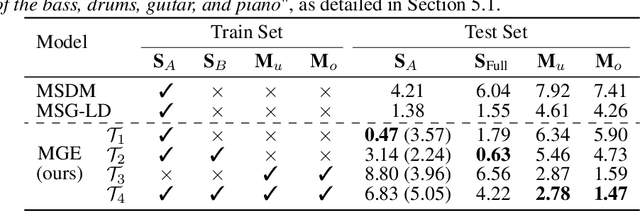

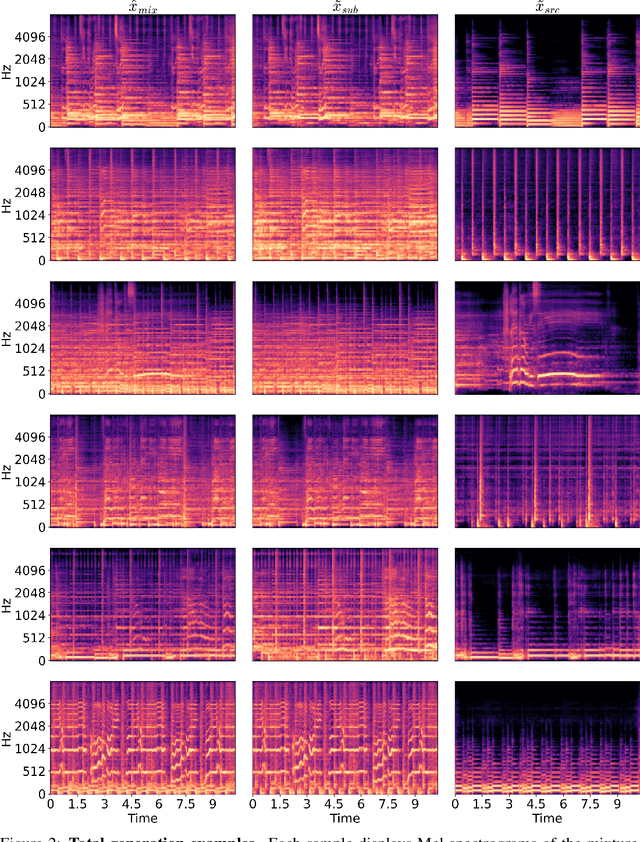
We present MGE-LDM, a unified latent diffusion framework for simultaneous music generation, source imputation, and query-driven source separation. Unlike prior approaches constrained to fixed instrument classes, MGE-LDM learns a joint distribution over full mixtures, submixtures, and individual stems within a single compact latent diffusion model. At inference, MGE-LDM enables (1) complete mixture generation, (2) partial generation (i.e., source imputation), and (3) text-conditioned extraction of arbitrary sources. By formulating both separation and imputation as conditional inpainting tasks in the latent space, our approach supports flexible, class-agnostic manipulation of arbitrary instrument sources. Notably, MGE-LDM can be trained jointly across heterogeneous multi-track datasets (e.g., Slakh2100, MUSDB18, MoisesDB) without relying on predefined instrument categories. Audio samples are available at our project page: https://yoongi43.github.io/MGELDM_Samples/.
Score-informed Music Source Separation: Improving Synthetic-to-real Generalization in Classical Music
Mar 10, 2025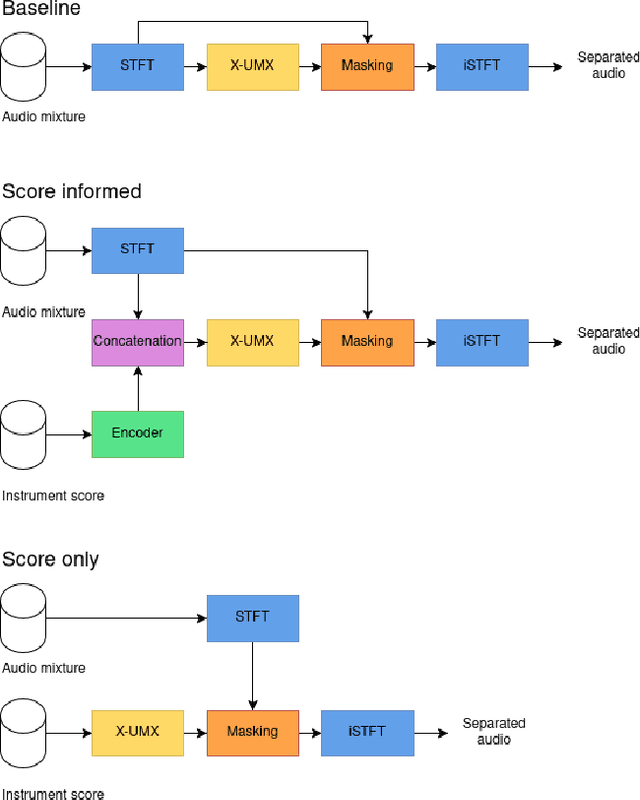
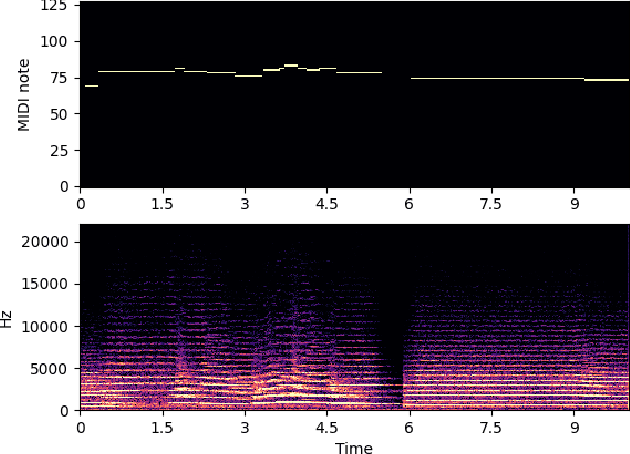
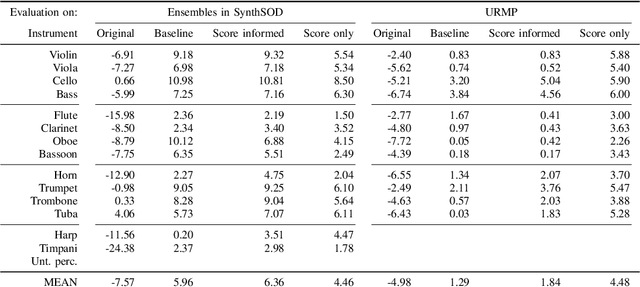
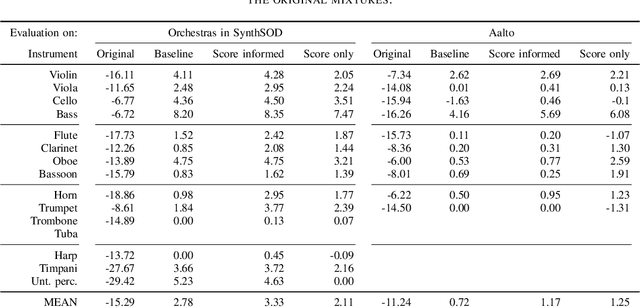
Music source separation is the task of separating a mixture of instruments into constituent tracks. Music source separation models are typically trained using only audio data, although additional information can be used to improve the model's separation capability. In this paper, we propose two ways of using musical scores to aid music source separation: a score-informed model where the score is concatenated with the magnitude spectrogram of the audio mixture as the input of the model, and a model where we use only the score to calculate the separation mask. We train our models on synthetic data in the SynthSOD dataset and evaluate our methods on the URMP and Aalto anechoic orchestra datasets, comprised of real recordings. The score-informed model improves separation results compared to a baseline approach, but struggles to generalize from synthetic to real data, whereas the score-only model shows a clear improvement in synthetic-to-real generalization.
Musical Source Separation of Brazilian Percussion
Mar 06, 2025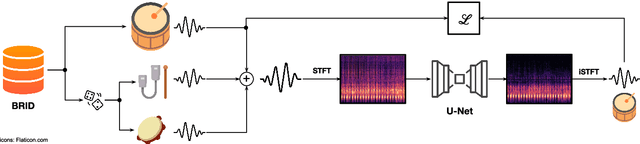
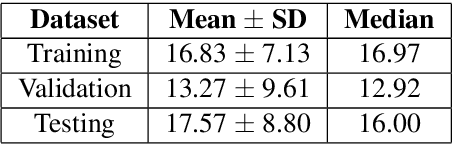
Musical source separation (MSS) has recently seen a big breakthrough in separating instruments from a mixture in the context of Western music, but research on non-Western instruments is still limited due to a lack of data. In this demo, we use an existing dataset of Brazilian sama percussion to create artificial mixtures for training a U-Net model to separate the surdo drum, a traditional instrument in samba. Despite limited training data, the model effectively isolates the surdo, given the drum's repetitive patterns and its characteristic low-pitched timbre. These results suggest that MSS systems can be successfully harnessed to work in more culturally-inclusive scenarios without the need of collecting extensive amounts of data.
Separate This, and All of these Things Around It: Music Source Separation via Hyperellipsoidal Queries
Jan 27, 2025



Music source separation is an audio-to-audio retrieval task of extracting one or more constituent components, or composites thereof, from a musical audio mixture. Each of these constituent components is often referred to as a "stem" in literature. Historically, music source separation has been dominated by a stem-based paradigm, leading to most state-of-the-art systems being either a collection of single-stem extraction models, or a tightly coupled system with a fixed, difficult-to-modify, set of supported stems. Combined with the limited data availability, advances in music source separation have thus been mostly limited to the "VDBO" set of stems: \textit{vocals}, \textit{drum}, \textit{bass}, and the catch-all \textit{others}. Recent work in music source separation has begun to challenge the fixed-stem paradigm, moving towards models able to extract any musical sound as long as this target type of sound could be specified to the model as an additional query input. We generalize this idea to a \textit{query-by-region} source separation system, specifying the target based on the query regardless of how many sound sources or which sound classes are contained within it. To do so, we propose the use of hyperellipsoidal regions as queries to allow for an intuitive yet easily parametrizable approach to specifying both the target (location) as well as its spread. Evaluation of the proposed system on the MoisesDB dataset demonstrated state-of-the-art performance of the proposed system both in terms of signal-to-noise ratios and retrieval metrics.