 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRain Removal
Rain removal is the process of removing rain or rain streaks from images to improve their visibility.
Papers and Code
IDSOR: Intensity- and Distance-Aware Statistical Outlier Removal for Weather-Robust LiDAR Point Clouds
Feb 05, 2026LiDAR point clouds captured in rain or snow are often corrupted by weather-induced returns, which can degrade perception and safety-critical scene understanding. This paper proposes Intensity- and Distance-Aware Statistical Outlier Removal (IDSOR), a range-adaptive filtering method that jointly exploits intensity cues and neighborhood sparsity. By incorporating an empirical, range-dependent distribution of weather returns into the threshold design, IDSOR suppresses weather-induced points while preserving fine structural details without cumbersome manual parameter tuning. We also propose a variant that uses a previously proposed method to estimate the weather return distribution from data, and integrates it into IDSOR. Experiments on simulation-augmented level-crossing measurements and on the Winter Adverse Driving dataset (WADS) demonstrate that IDSOR achieves a favorable precision-recall trade-off, maintaining both precision and recall above 90% on WADS.
A curated UK rain radar data set for training and benchmarking nowcasting models
Dec 08, 2025This paper documents a data set of UK rain radar image sequences for use in statistical modeling and machine learning methods for nowcasting. The main dataset contains 1,000 randomly sampled sequences of length 20 steps (15-minute increments) of 2D radar intensity fields of dimension 40x40 (at 5km spatial resolution). Spatially stratified sampling ensures spatial homogeneity despite removal of clear-sky cases by threshold-based truncation. For each radar sequence, additional atmospheric and geographic features are made available, including date, location, mean elevation, mean wind direction and speed and prevailing storm type. New R functions to extract data from the binary "Nimrod" radar data format are provided. A case study is presented to train and evaluate a simple convolutional neural network for radar nowcasting, including self-contained R code.
Seeing Through the Rain: Resolving High-Frequency Conflicts in Deraining and Super-Resolution via Diffusion Guidance
Nov 16, 2025Clean images are crucial for visual tasks such as small object detection, especially at high resolutions. However, real-world images are often degraded by adverse weather, and weather restoration methods may sacrifice high-frequency details critical for analyzing small objects. A natural solution is to apply super-resolution (SR) after weather removal to recover both clarity and fine structures. However, simply cascading restoration and SR struggle to bridge their inherent conflict: removal aims to remove high-frequency weather-induced noise, while SR aims to hallucinate high-frequency textures from existing details, leading to inconsistent restoration contents. In this paper, we take deraining as a case study and propose DHGM, a Diffusion-based High-frequency Guided Model for generating clean and high-resolution images. DHGM integrates pre-trained diffusion priors with high-pass filters to simultaneously remove rain artifacts and enhance structural details. Extensive experiments demonstrate that DHGM achieves superior performance over existing methods, with lower costs.
SNNSIR: A Simple Spiking Neural Network for Stereo Image Restoration
Aug 17, 2025Spiking Neural Networks (SNNs), characterized by discrete binary activations, offer high computational efficiency and low energy consumption, making them well-suited for computation-intensive tasks such as stereo image restoration. In this work, we propose SNNSIR, a simple yet effective Spiking Neural Network for Stereo Image Restoration, specifically designed under the spike-driven paradigm where neurons transmit information through sparse, event-based binary spikes. In contrast to existing hybrid SNN-ANN models that still rely on operations such as floating-point matrix division or exponentiation, which are incompatible with the binary and event-driven nature of SNNs, our proposed SNNSIR adopts a fully spike-driven architecture to achieve low-power and hardware-friendly computation. To address the expressiveness limitations of binary spiking neurons, we first introduce a lightweight Spike Residual Basic Block (SRBB) to enhance information flow via spike-compatible residual learning. Building on this, the Spike Stereo Convolutional Modulation (SSCM) module introduces simplified nonlinearity through element-wise multiplication and highlights noise-sensitive regions via cross-view-aware modulation. Complementing this, the Spike Stereo Cross-Attention (SSCA) module further improves stereo correspondence by enabling efficient bidirectional feature interaction across views within a spike-compatible framework. Extensive experiments on diverse stereo image restoration tasks, including rain streak removal, raindrop removal, low-light enhancement, and super-resolution demonstrate that our model achieves competitive restoration performance while significantly reducing computational overhead. These results highlight the potential for real-time, low-power stereo vision applications. The code will be available after the article is accepted.
DenoiseCP-Net: Efficient Collective Perception in Adverse Weather via Joint LiDAR-Based 3D Object Detection and Denoising
Jul 09, 2025While automated vehicles hold the potential to significantly reduce traffic accidents, their perception systems remain vulnerable to sensor degradation caused by adverse weather and environmental occlusions. Collective perception, which enables vehicles to share information, offers a promising approach to overcoming these limitations. However, to this date collective perception in adverse weather is mostly unstudied. Therefore, we conduct the first study of LiDAR-based collective perception under diverse weather conditions and present a novel multi-task architecture for LiDAR-based collective perception under adverse weather. Adverse weather conditions can not only degrade perception capabilities, but also negatively affect bandwidth requirements and latency due to the introduced noise that is also transmitted and processed. Denoising prior to communication can effectively mitigate these issues. Therefore, we propose DenoiseCP-Net, a novel multi-task architecture for LiDAR-based collective perception under adverse weather conditions. DenoiseCP-Net integrates voxel-level noise filtering and object detection into a unified sparse convolution backbone, eliminating redundant computations associated with two-stage pipelines. This design not only reduces inference latency and computational cost but also minimizes communication overhead by removing non-informative noise. We extended the well-known OPV2V dataset by simulating rain, snow, and fog using our realistic weather simulation models. We demonstrate that DenoiseCP-Net achieves near-perfect denoising accuracy in adverse weather, reduces the bandwidth requirements by up to 23.6% while maintaining the same detection accuracy and reducing the inference latency for cooperative vehicles.
Semi-Supervised State-Space Model with Dynamic Stacking Filter for Real-World Video Deraining
May 22, 2025

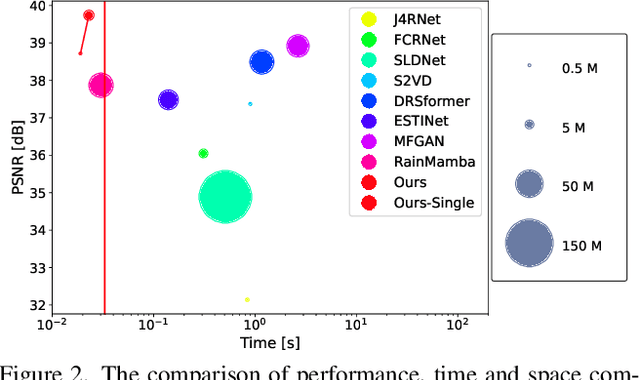

Significant progress has been made in video restoration under rainy conditions over the past decade, largely propelled by advancements in deep learning. Nevertheless, existing methods that depend on paired data struggle to generalize effectively to real-world scenarios, primarily due to the disparity between synthetic and authentic rain effects. To address these limitations, we propose a dual-branch spatio-temporal state-space model to enhance rain streak removal in video sequences. Specifically, we design spatial and temporal state-space model layers to extract spatial features and incorporate temporal dependencies across frames, respectively. To improve multi-frame feature fusion, we derive a dynamic stacking filter, which adaptively approximates statistical filters for superior pixel-wise feature refinement. Moreover, we develop a median stacking loss to enable semi-supervised learning by generating pseudo-clean patches based on the sparsity prior of rain. To further explore the capacity of deraining models in supporting other vision-based tasks in rainy environments, we introduce a novel real-world benchmark focused on object detection and tracking in rainy conditions. Our method is extensively evaluated across multiple benchmarks containing numerous synthetic and real-world rainy videos, consistently demonstrating its superiority in quantitative metrics, visual quality, efficiency, and its utility for downstream tasks.
Image Restoration via Multi-domain Learning
May 07, 2025



Due to adverse atmospheric and imaging conditions, natural images suffer from various degradation phenomena. Consequently, image restoration has emerged as a key solution and garnered substantial attention. Although recent Transformer architectures have demonstrated impressive success across various restoration tasks, their considerable model complexity poses significant challenges for both training and real-time deployment. Furthermore, instead of investigating the commonalities among different degradations, most existing restoration methods focus on modifying Transformer under limited restoration priors. In this work, we first review various degradation phenomena under multi-domain perspective, identifying common priors. Then, we introduce a novel restoration framework, which integrates multi-domain learning into Transformer. Specifically, in Token Mixer, we propose a Spatial-Wavelet-Fourier multi-domain structure that facilitates local-region-global multi-receptive field modeling to replace vanilla self-attention. Additionally, in Feed-Forward Network, we incorporate multi-scale learning to fuse multi-domain features at different resolutions. Comprehensive experimental results across ten restoration tasks, such as dehazing, desnowing, motion deblurring, defocus deblurring, rain streak/raindrop removal, cloud removal, shadow removal, underwater enhancement and low-light enhancement, demonstrate that our proposed model outperforms state-of-the-art methods and achieves a favorable trade-off among restoration performance, parameter size, computational cost and inference latency. The code is available at: https://github.com/deng-ai-lab/SWFormer.
Iterative Optimal Attention and Local Model for Single Image Rain Streak Removal
Mar 20, 2025High-fidelity imaging is crucial for the successful safety supervision and intelligent deployment of vision-based measurement systems (VBMS). It ensures high-quality imaging in VBMS, which is fundamental for reliable visual measurement and analysis. However, imaging quality can be significantly impaired by adverse weather conditions, particularly rain, leading to blurred images and reduced contrast. Such impairments increase the risk of inaccurate evaluations and misinterpretations in VBMS. To address these limitations, we propose an Expectation Maximization Reconstruction Transformer (EMResformer) for single image rain streak removal. The EMResformer retains the key self-attention values for feature aggregation, enhancing local features to produce superior image reconstruction. Specifically, we propose an Expectation Maximization Block seamlessly integrated into the single image rain streak removal network, enhancing its ability to eliminate superfluous information and restore a cleaner background image. Additionally, to further enhance local information for improved detail rendition, we introduce a Local Model Residual Block, which integrates two local model blocks along with a sequence of convolutions and activation functions. This integration synergistically facilitates the extraction of more pertinent features for enhanced single image rain streak removal. Extensive experiments validate that our proposed EMResformer surpasses current state-of-the-art single image rain streak removal methods on both synthetic and real-world datasets, achieving an improved balance between model complexity and single image deraining performance. Furthermore, we evaluate the effectiveness of our method in VBMS scenarios, demonstrating that high-quality imaging significantly improves the accuracy and reliability of VBMS tasks.
CMAWRNet: Multiple Adverse Weather Removal via a Unified Quaternion Neural Architecture
May 03, 2025



Images used in real-world applications such as image or video retrieval, outdoor surveillance, and autonomous driving suffer from poor weather conditions. When designing robust computer vision systems, removing adverse weather such as haze, rain, and snow is a significant problem. Recently, deep-learning methods offered a solution for a single type of degradation. Current state-of-the-art universal methods struggle with combinations of degradations, such as haze and rain-streak. Few algorithms have been developed that perform well when presented with images containing multiple adverse weather conditions. This work focuses on developing an efficient solution for multiple adverse weather removal using a unified quaternion neural architecture called CMAWRNet. It is based on a novel texture-structure decomposition block, a novel lightweight encoder-decoder quaternion transformer architecture, and an attentive fusion block with low-light correction. We also introduce a quaternion similarity loss function to preserve color information better. The quantitative and qualitative evaluation of the current state-of-the-art benchmarking datasets and real-world images shows the performance advantages of the proposed CMAWRNet compared to other state-of-the-art weather removal approaches dealing with multiple weather artifacts. Extensive computer simulations validate that CMAWRNet improves the performance of downstream applications such as object detection. This is the first time the decomposition approach has been applied to the universal weather removal task.
SpikeDerain: Unveiling Clear Videos from Rainy Sequences Using Color Spike Streams
Mar 26, 2025Restoring clear frames from rainy videos presents a significant challenge due to the rapid motion of rain streaks. Traditional frame-based visual sensors, which capture scene content synchronously, struggle to capture the fast-moving details of rain accurately. In recent years, neuromorphic sensors have introduced a new paradigm for dynamic scene perception, offering microsecond temporal resolution and high dynamic range. However, existing multimodal methods that fuse event streams with RGB images face difficulties in handling the complex spatiotemporal interference of raindrops in real scenes, primarily due to hardware synchronization errors and computational redundancy. In this paper, we propose a Color Spike Stream Deraining Network (SpikeDerain), capable of reconstructing spike streams of dynamic scenes and accurately removing rain streaks. To address the challenges of data scarcity in real continuous rainfall scenes, we design a physically interpretable rain streak synthesis model that generates parameterized continuous rain patterns based on arbitrary background images. Experimental results demonstrate that the network, trained with this synthetic data, remains highly robust even under extreme rainfall conditions. These findings highlight the effectiveness and robustness of our method across varying rainfall levels and datasets, setting new standards for video deraining tasks. The code will be released soon.