 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Answer Matters: Evaluating Commonsense with Probabilistic Measures
Jun 06, 2024



Large language models have demonstrated impressive performance on commonsense tasks; however, these tasks are often posed as multiple-choice questions, allowing models to exploit systematic biases. Commonsense is also inherently probabilistic with multiple correct answers. The purpose of "boiling water" could be making tea and cooking, but it also could be killing germs. Existing tasks do not capture the probabilistic nature of common sense. To this end, we present commonsense frame completion (CFC), a new generative task that evaluates common sense via multiple open-ended generations. We also propose a method of probabilistic evaluation that strongly correlates with human judgments. Humans drastically outperform strong language model baselines on our dataset, indicating this approach is both a challenging and useful evaluation of machine common sense.
DocAMR: Multi-Sentence AMR Representation and Evaluation
Dec 15, 2021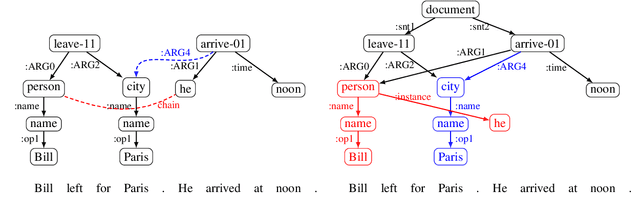
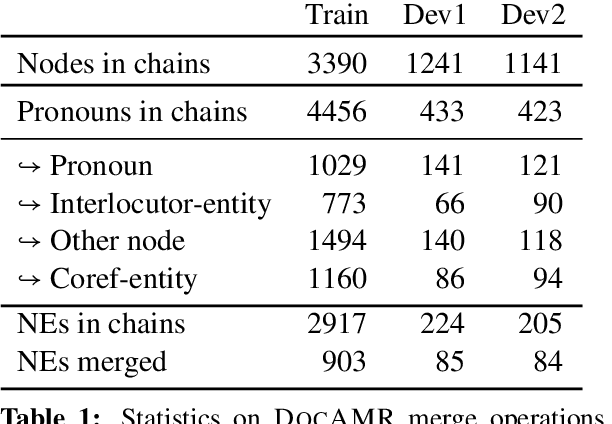
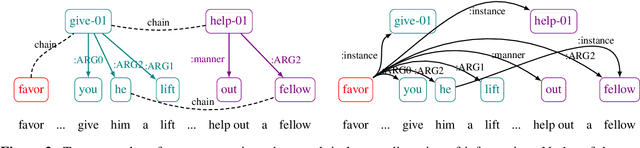
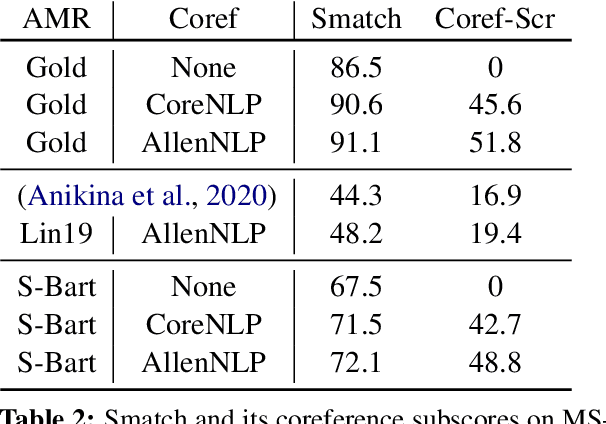
Despite extensive research on parsing of English sentences into Abstraction Meaning Representation (AMR) graphs, which are compared to gold graphs via the Smatch metric, full-document parsing into a unified graph representation lacks well-defined representation and evaluation. Taking advantage of a super-sentential level of coreference annotation from previous work, we introduce a simple algorithm for deriving a unified graph representation, avoiding the pitfalls of information loss from over-merging and lack of coherence from under-merging. Next, we describe improvements to the Smatch metric to make it tractable for comparing document-level graphs, and use it to re-evaluate the best published document-level AMR parser. We also present a pipeline approach combining the top performing AMR parser and coreference resolution systems, providing a strong baseline for future research.
A Dataset for Discourse Structure in Peer Review Discussions
Oct 16, 2021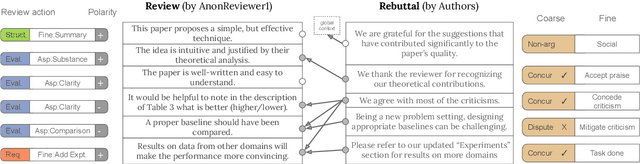
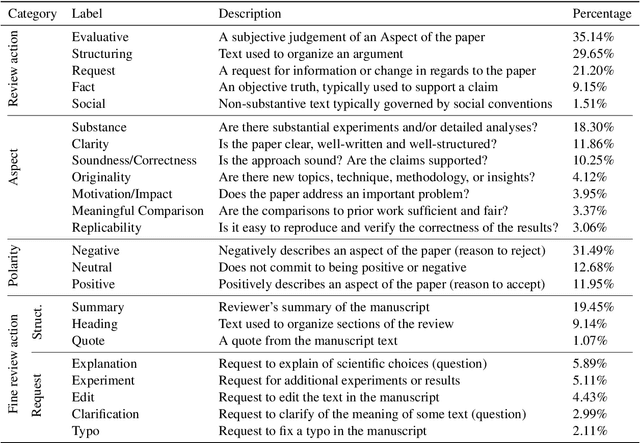

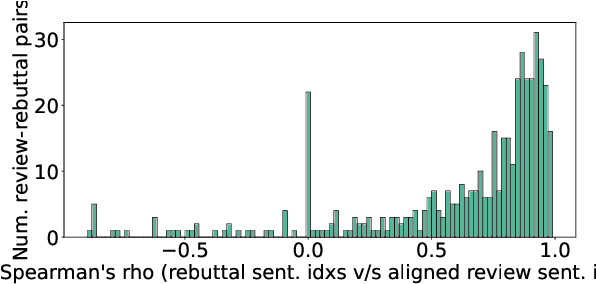
At the foundation of scientific evaluation is the labor-intensive process of peer review. This critical task requires participants to consume and interpret vast amounts of highly technical text. We show that discourse cues from rebuttals can shed light on the quality and interpretation of reviews. Further, an understanding of the argumentative strategies employed by the reviewers and authors provides useful signal for area chairs and other decision makers. This paper presents a new labeled dataset of 20k sentences contained in 506 review-rebuttal pairs in English, annotated by experts. While existing datasets annotate a subset of review sentences using various schemes, ours synthesizes existing label sets and extends them to include fine-grained annotation of the rebuttal sentences, characterizing the authors' stance towards the reviewers' criticisms and their commitment to addressing them. Further, we annotate \textit{every} sentence in both the review and the rebuttal, including a description of the context for each rebuttal sentence.
Improved Latent Tree Induction with Distant Supervision via Span Constraints
Sep 10, 2021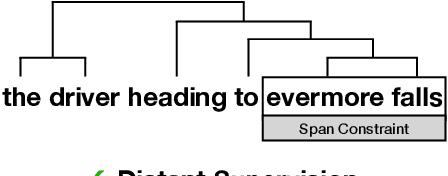

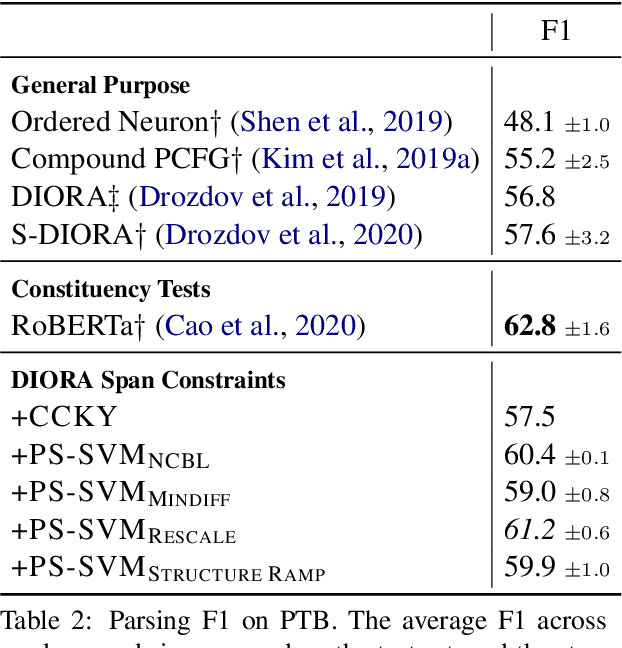
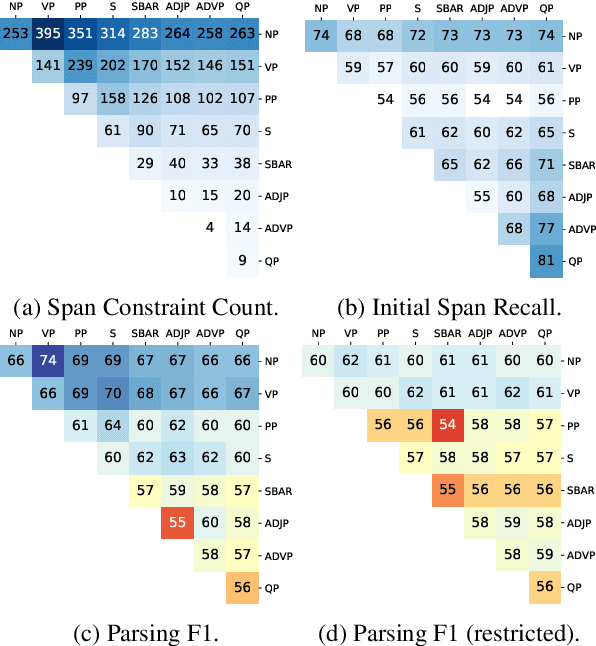
For over thirty years, researchers have developed and analyzed methods for latent tree induction as an approach for unsupervised syntactic parsing. Nonetheless, modern systems still do not perform well enough compared to their supervised counterparts to have any practical use as structural annotation of text. In this work, we present a technique that uses distant supervision in the form of span constraints (i.e. phrase bracketing) to improve performance in unsupervised constituency parsing. Using a relatively small number of span constraints we can substantially improve the output from DIORA, an already competitive unsupervised parsing system. Compared with full parse tree annotation, span constraints can be acquired with minimal effort, such as with a lexicon derived from Wikipedia, to find exact text matches. Our experiments show span constraints based on entities improves constituency parsing on English WSJ Penn Treebank by more than 5 F1. Furthermore, our method extends to any domain where span constraints are easily attainable, and as a case study we demonstrate its effectiveness by parsing biomedical text from the CRAFT dataset.
CSFCube -- A Test Collection of Computer Science Research Articles for Faceted Query by Example
Mar 24, 2021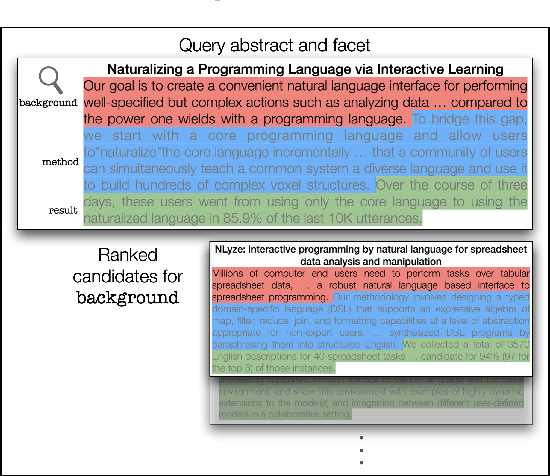
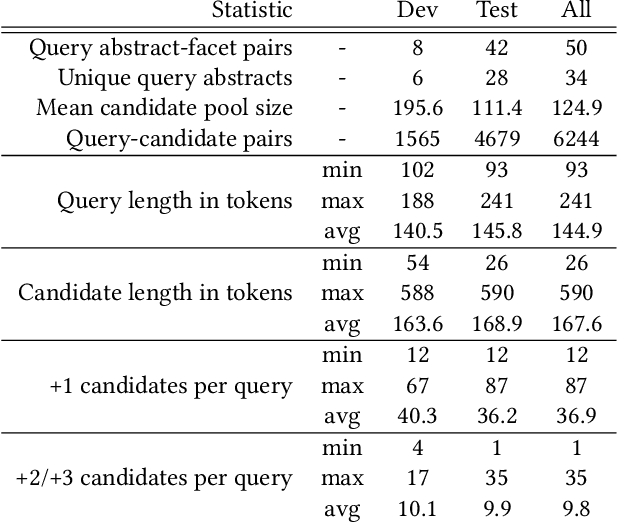
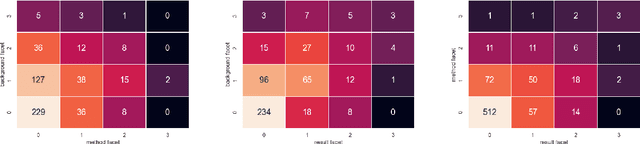
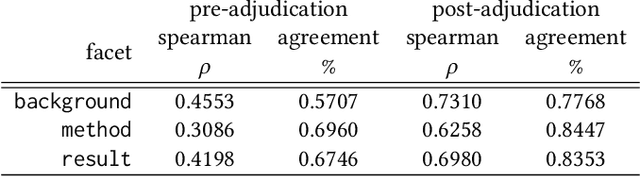
Query by Example is a well-known information retrieval task in which a document is chosen by the user as the search query and the goal is to retrieve relevant documents from a large collection. However, a document often covers multiple aspects of a topic. To address this scenario we introduce the task of faceted Query by Example in which users can also specify a finer grained aspect in addition to the input query document. We focus on the application of this task in scientific literature search. We envision models which are able to retrieve scientific papers analogous to a query scientific paper along specifically chosen rhetorical structure elements as one solution to this problem. In this work, the rhetorical structure elements, which we refer to as facets, indicate "background", "method", or "result" aspects of a scientific paper. We introduce and describe an expert annotated test collection to evaluate models trained to perform this task. Our test collection consists of a diverse set of 50 query documents, drawn from computational linguistics and machine learning venues. We carefully followed the annotation guideline used by TREC for depth-k pooling (k = 100 or 250) and the resulting data collection consists of graded relevance scores with high annotation agreement. The data is freely available for research purposes.
ProtoQA: A Question Answering Dataset for Prototypical Common-Sense Reasoning
May 02, 2020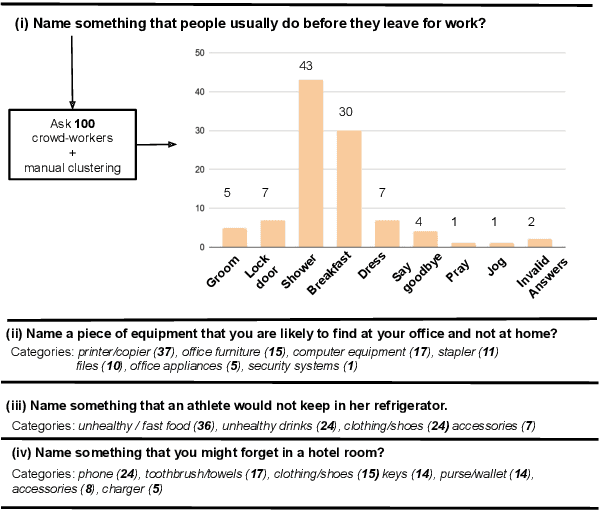

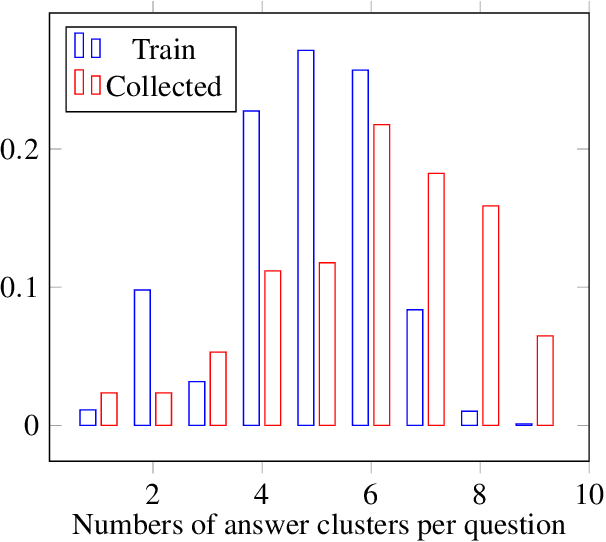
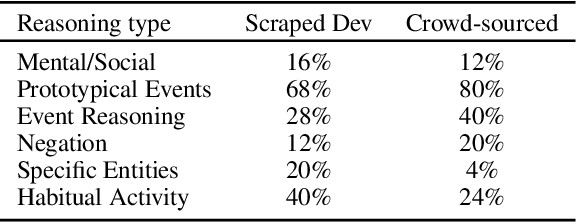
Given questions regarding some prototypical situation -- such as Name something that people usually do before they leave the house for work? -- a human can easily answer them via acquired experiences. There can be multiple right answers for such questions with some more common for a situation than others. This paper introduces a new question answering dataset for training and evaluating common-sense reasoning capabilities of artificial intelligence systems in such prototypical situations. The training set is gathered from an existing set of questions played in a long-running international trivia game show -- Family Feud. The hidden evaluation set is created by gathering answers for each question from 100 crowd-workers. We also propose an open-domain task where a model has to output a ranked list of answers, ideally covering all prototypical answers for a question. On evaluating our dataset with various competitive state-of-the-art models, we find there is a significant gap between the best model and human performance on a number of evaluation metrics.
Adposition and Case Supersenses v2: Guidelines for English
Jul 02, 2018This document offers a detailed linguistic description of SNACS (Semantic Network of Adposition and Case Supersenses; Schneider et al., 2018), an inventory of 50 semantic labels ("supersenses") that characterize the use of adpositions and case markers at a somewhat coarse level of granularity, as demonstrated in the STREUSLE 4.1 corpus (https://github.com/nert-gu/streusle/). Though the SNACS inventory aspires to be universal, this document is specific to English; documentation for other languages will be published separately. Version 2 is a revision of the supersense inventory proposed for English by Schneider et al. (2015, 2016) (henceforth "v1"), which in turn was based on previous schemes. The present inventory was developed after extensive review of the v1 corpus annotations for English, plus previously unanalyzed genitive case possessives (Blodgett and Schneider, 2018), as well as consideration of adposition and case phenomena in Hebrew, Hindi, Korean, and German. Hwang et al. (2017) present the theoretical underpinnings of the v2 scheme. Schneider et al. (2018) summarize the scheme, its application to English corpus data, and an automatic disambiguation task.
Coping with Construals in Broad-Coverage Semantic Annotation of Adpositions
Mar 10, 2017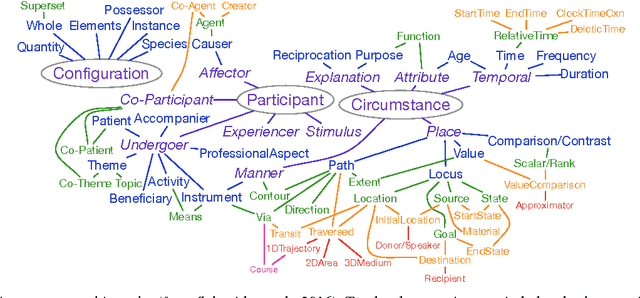
We consider the semantics of prepositions, revisiting a broad-coverage annotation scheme used for annotating all 4,250 preposition tokens in a 55,000 word corpus of English. Attempts to apply the scheme to adpositions and case markers in other languages, as well as some problematic cases in English, have led us to reconsider the assumption that a preposition's lexical contribution is equivalent to the role/relation that it mediates. Our proposal is to embrace the potential for construal in adposition use, expressing such phenomena directly at the token level to manage complexity and avoid sense proliferation. We suggest a framework to represent both the scene role and the adposition's lexical function so they can be annotated at scale---supporting automatic, statistical processing of domain-general language---and sketch how this representation would inform a constructional analysis.
A corpus of preposition supersenses in English web reviews
May 08, 2016
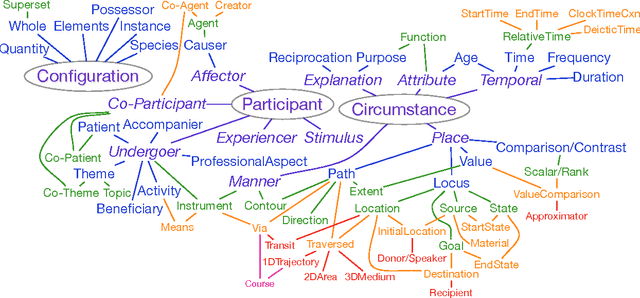

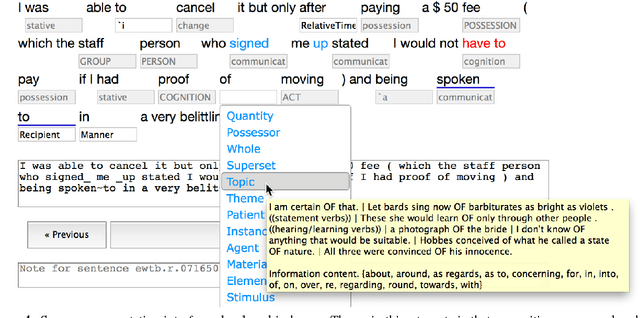
We present the first corpus annotated with preposition supersenses, unlexicalized categories for semantic functions that can be marked by English prepositions (Schneider et al., 2015). That scheme improves upon its predecessors to better facilitate comprehensive manual annotation. Moreover, unlike the previous schemes, the preposition supersenses are organized hierarchically. Our data will be publicly released on the web upon publication.