 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoQA: A Question Answering Dataset for Prototypical Common-Sense Reasoning
May 02, 2020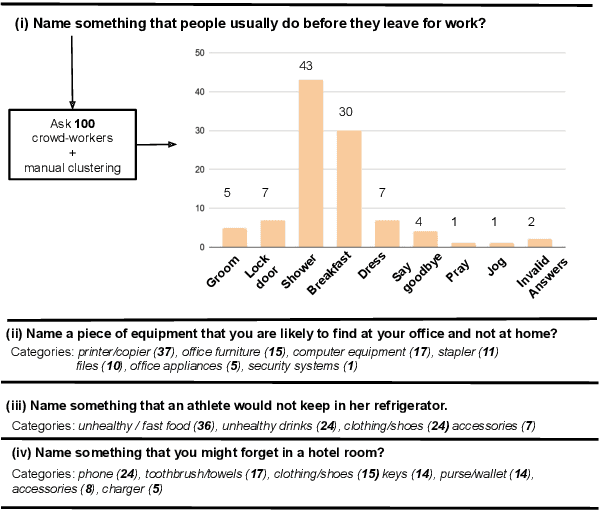

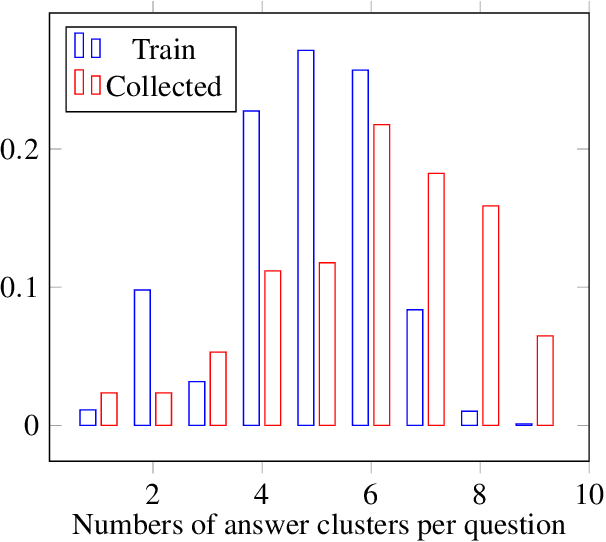
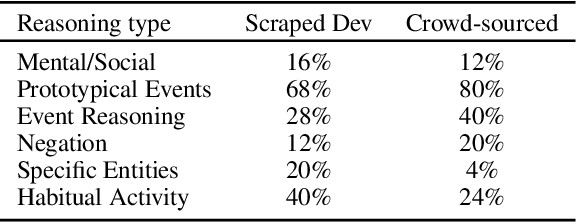
Given questions regarding some prototypical situation -- such as Name something that people usually do before they leave the house for work? -- a human can easily answer them via acquired experiences. There can be multiple right answers for such questions with some more common for a situation than others. This paper introduces a new question answering dataset for training and evaluating common-sense reasoning capabilities of artificial intelligence systems in such prototypical situations. The training set is gathered from an existing set of questions played in a long-running international trivia game show -- Family Feud. The hidden evaluation set is created by gathering answers for each question from 100 crowd-workers. We also propose an open-domain task where a model has to output a ranked list of answers, ideally covering all prototypical answers for a question. On evaluating our dataset with various competitive state-of-the-art models, we find there is a significant gap between the best model and human performance on a number of evaluation metrics.