 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSFCube -- A Test Collection of Computer Science Research Articles for Faceted Query by Example
Paper and Code
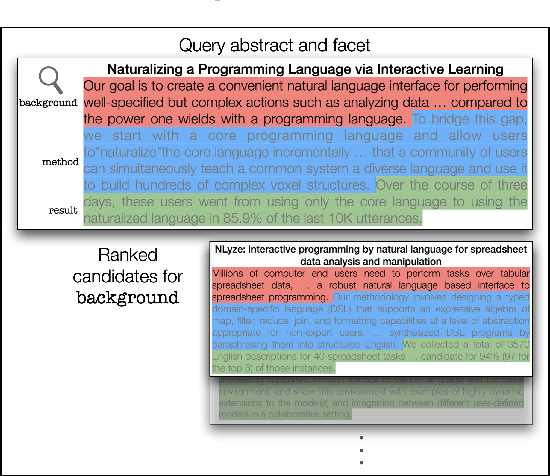
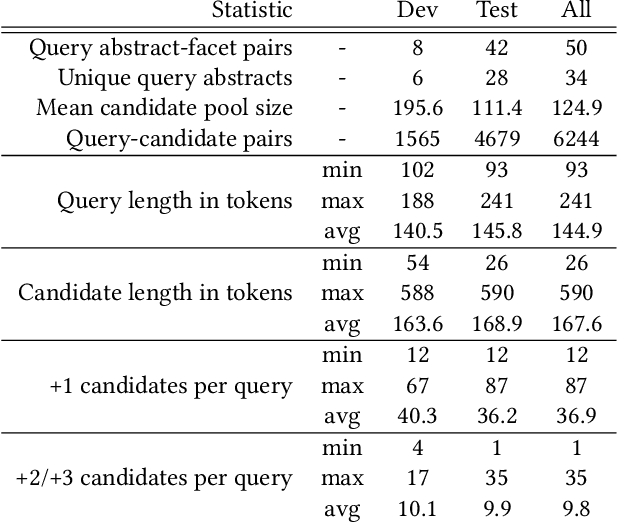
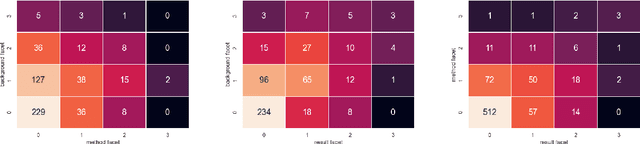
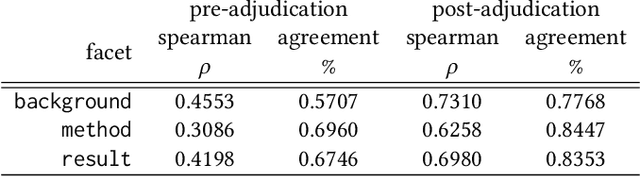
Query by Example is a well-known information retrieval task in which a document is chosen by the user as the search query and the goal is to retrieve relevant documents from a large collection. However, a document often covers multiple aspects of a topic. To address this scenario we introduce the task of faceted Query by Example in which users can also specify a finer grained aspect in addition to the input query document. We focus on the application of this task in scientific literature search. We envision models which are able to retrieve scientific papers analogous to a query scientific paper along specifically chosen rhetorical structure elements as one solution to this problem. In this work, the rhetorical structure elements, which we refer to as facets, indicate "background", "method", or "result" aspects of a scientific paper. We introduce and describe an expert annotated test collection to evaluate models trained to perform this task. Our test collection consists of a diverse set of 50 query documents, drawn from computational linguistics and machine learning venues. We carefully followed the annotation guideline used by TREC for depth-k pooling (k = 100 or 250) and the resulting data collection consists of graded relevance scores with high annotation agreement. The data is freely available for research purposes.