 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Aware-Predictive Control Barrier Functions: Safer Human Robot Interaction through Probabilistic Motion Forecasting
Aug 28, 2025To enable flexible, high-throughput automation in settings where people and robots share workspaces, collaborative robotic cells must reconcile stringent safety guarantees with the need for responsive and effective behavior. A dynamic obstacle is the stochastic, task-dependent variability of human motion: when robots fall back on purely reactive or worst-case envelopes, they brake unnecessarily, stall task progress, and tamper with the fluidity that true Human-Robot Interaction demands. In recent years, learning-based human-motion prediction has rapidly advanced, although most approaches produce worst-case scenario forecasts that often do not treat prediction uncertainty in a well-structured way, resulting in over-conservative planning algorithms, limiting their flexibility. We introduce Uncertainty-Aware Predictive Control Barrier Functions (UA-PCBFs), a unified framework that fuses probabilistic human hand motion forecasting with the formal safety guarantees of Control Barrier Functions. In contrast to other variants, our framework allows for dynamic adjustment of the safety margin thanks to the human motion uncertainty estimation provided by a forecasting module. Thanks to uncertainty estimation, UA-PCBFs empower collaborative robots with a deeper understanding of future human states, facilitating more fluid and intelligent interactions through informed motion planning. We validate UA-PCBFs through comprehensive real-world experiments with an increasing level of realism, including automated setups (to perform exactly repeatable motions) with a robotic hand and direct human-robot interactions (to validate promptness, usability, and human confidence). Relative to state-of-the-art HRI architectures, UA-PCBFs show better performance in task-critical metrics, significantly reducing the number of violations of the robot's safe space during interaction with respect to the state-of-the-art.
FF-SRL: High Performance GPU-Based Surgical Simulation For Robot Learning
Mar 24, 2025

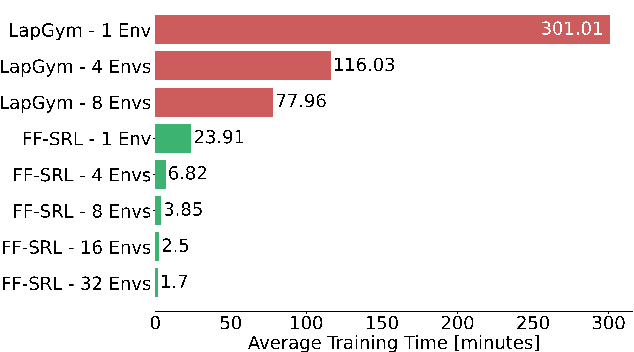

Robotic surgery is a rapidly developing field that can greatly benefit from the automation of surgical tasks. However, training techniques such as Reinforcement Learning (RL) require a high number of task repetitions, which are generally unsafe and impractical to perform on real surgical systems. This stresses the need for simulated surgical environments, which are not only realistic, but also computationally efficient and scalable. We introduce FF-SRL (Fast and Flexible Surgical Reinforcement Learning), a high-performance learning environment for robotic surgery. In FF-SRL both physics simulation and RL policy training reside entirely on a single GPU. This avoids typical bottlenecks associated with data transfer between the CPU and GPU, leading to accelerated learning rates. Our results show that FF-SRL reduces the training time of a complex tissue manipulation task by an order of magnitude, down to a couple of minutes, compared to a common CPU/GPU simulator. Such speed-up may facilitate the experimentation with RL techniques and contribute to the development of new generation of surgical systems. To this end, we make our code publicly available to the community.
SimuScope: Realistic Endoscopic Synthetic Dataset Generation through Surgical Simulation and Diffusion Models
Dec 03, 2024



Computer-assisted surgical (CAS) systems enhance surgical execution and outcomes by providing advanced support to surgeons. These systems often rely on deep learning models trained on complex, challenging-to-annotate data. While synthetic data generation can address these challenges, enhancing the realism of such data is crucial. This work introduces a multi-stage pipeline for generating realistic synthetic data, featuring a fully-fledged surgical simulator that automatically produces all necessary annotations for modern CAS systems. This simulator generates a wide set of annotations that surpass those available in public synthetic datasets. Additionally, it offers a more complex and realistic simulation of surgical interactions, including the dynamics between surgical instruments and deformable anatomical environments, outperforming existing approaches. To further bridge the visual gap between synthetic and real data, we propose a lightweight and flexible image-to-image translation method based on Stable Diffusion (SD) and Low-Rank Adaptation (LoRA). This method leverages a limited amount of annotated data, enables efficient training, and maintains the integrity of annotations generated by our simulator. The proposed pipeline is experimentally validated and can translate synthetic images into images with real-world characteristics, which can generalize to real-world context, thereby improving both training and CAS guidance. The code and the dataset are available at https://github.com/SanoScience/SimuScope.
PR-ENDO: Physically Based Relightable Gaussian Splatting for Endoscopy
Nov 19, 2024



Endoscopic procedures are crucial for colorectal cancer diagnosis, and three-dimensional reconstruction of the environment for real-time novel-view synthesis can significantly enhance diagnosis. We present PR-ENDO, a framework that leverages 3D Gaussian Splatting within a physically based, relightable model tailored for the complex acquisition conditions in endoscopy, such as restricted camera rotations and strong view-dependent illumination. By exploiting the connection between the camera and light source, our approach introduces a relighting model to capture the intricate interactions between light and tissue using physically based rendering and MLP. Existing methods often produce artifacts and inconsistencies under these conditions, which PR-ENDO overcomes by incorporating a specialized diffuse MLP that utilizes light angles and normal vectors, achieving stable reconstructions even with limited training camera rotations. We benchmarked our framework using a publicly available dataset and a newly introduced dataset with wider camera rotations. Our methods demonstrated superior image quality compared to baseline approaches.
Imitation Learning for Robotic Assisted Ultrasound Examination of Deep Venous Thrombosis using Kernelized Movement Primitives
Jul 11, 2024Deep Vein Thrombosis (DVT) is a common yet potentially fatal condition, often leading to critical complications like pulmonary embolism. DVT is commonly diagnosed using Ultrasound (US) imaging, which can be inconsistent due to its high dependence on the operator's skill. Robotic US Systems (RUSs) aim to improve diagnostic test consistency but face challenges with the complex scanning pattern needed for DVT assessment, where precise control over US probe pressure is crucial for indirectly detecting occlusions. This work introduces an imitation learning method, based on Kernelized Movement Primitives (KMP), to standardize DVT US exams by training an autonomous robotic controller using sonographer demonstrations. A new recording device design enhances demonstration ergonomics, integrating with US probes and enabling seamless force and position data recording. KMPs are used to capture scanning skills, linking scan trajectory and force, enabling generalization beyond the demonstrations. Our approach, evaluated on synthetic models and volunteers, shows that the KMP-based RUS can replicate an expert's force control and image quality in DVT US examination. It outperforms previous methods using manually defined force profiles, improving exam standardization and reducing reliance on specialized sonographers.
DEAR: Disentangled Environment and Agent Representations for Reinforcement Learning without Reconstruction
Jun 30, 2024Reinforcement Learning (RL) algorithms can learn robotic control tasks from visual observations, but they often require a large amount of data, especially when the visual scene is complex and unstructured. In this paper, we explore how the agent's knowledge of its shape can improve the sample efficiency of visual RL methods. We propose a novel method, Disentangled Environment and Agent Representations (DEAR), that uses the segmentation mask of the agent as supervision to learn disentangled representations of the environment and the agent through feature separation constraints. Unlike previous approaches, DEAR does not require reconstruction of visual observations. These representations are then used as an auxiliary loss to the RL objective, encouraging the agent to focus on the relevant features of the environment. We evaluate DEAR on two challenging benchmarks: Distracting DeepMind control suite and Franka Kitchen manipulation tasks. Our findings demonstrate that DEAR surpasses state-of-the-art methods in sample efficiency, achieving comparable or superior performance with reduced parameters. Our results indicate that integrating agent knowledge into visual RL methods has the potential to enhance their learning efficiency and robustness.
Sim-To-Real Transfer for Visual Reinforcement Learning of Deformable Object Manipulation for Robot-Assisted Surgery
Jun 10, 2024Automation holds the potential to assist surgeons in robotic interventions, shifting their mental work load from visuomotor control to high level decision making. Reinforcement learning has shown promising results in learning complex visuomotor policies, especially in simulation environments where many samples can be collected at low cost. A core challenge is learning policies in simulation that can be deployed in the real world, thereby overcoming the sim-to-real gap. In this work, we bridge the visual sim-to-real gap with an image-based reinforcement learning pipeline based on pixel-level domain adaptation and demonstrate its effectiveness on an image-based task in deformable object manipulation. We choose a tissue retraction task because of its importance in clinical reality of precise cancer surgery. After training in simulation on domain-translated images, our policy requires no retraining to perform tissue retraction with a 50% success rate on the real robotic system using raw RGB images. Furthermore, our sim-to-real transfer method makes no assumptions on the task itself and requires no paired images. This work introduces the first successful application of visual sim-to-real transfer for robotic manipulation of deformable objects in the surgical field, which represents a notable step towards the clinical translation of cognitive surgical robotics.
Challenges in Multi-centric Generalization: Phase and Step Recognition in Roux-en-Y Gastric Bypass Surgery
Dec 18, 2023Most studies on surgical activity recognition utilizing Artificial intelligence (AI) have focused mainly on recognizing one type of activity from small and mono-centric surgical video datasets. It remains speculative whether those models would generalize to other centers. In this work, we introduce a large multi-centric multi-activity dataset consisting of 140 videos (MultiBypass140) of laparoscopic Roux-en-Y gastric bypass (LRYGB) surgeries performed at two medical centers: the University Hospital of Strasbourg (StrasBypass70) and Inselspital, Bern University Hospital (BernBypass70). The dataset has been fully annotated with phases and steps. Furthermore, we assess the generalizability and benchmark different deep learning models in 7 experimental studies: 1) Training and evaluation on BernBypass70; 2) Training and evaluation on StrasBypass70; 3) Training and evaluation on the MultiBypass140; 4) Training on BernBypass70, evaluation on StrasBypass70; 5) Training on StrasBypass70, evaluation on BernBypass70; Training on MultiBypass140, evaluation 6) on BernBypass70 and 7) on StrasBypass70. The model's performance is markedly influenced by the training data. The worst results were obtained in experiments 4) and 5) confirming the limited generalization capabilities of models trained on mono-centric data. The use of multi-centric training data, experiments 6) and 7), improves the generalization capabilities of the models, bringing them beyond the level of independent mono-centric training and validation (experiments 1) and 2)). MultiBypass140 shows considerable variation in surgical technique and workflow of LRYGB procedures between centers. Therefore, generalization experiments demonstrate a remarkable difference in model performance. These results highlight the importance of multi-centric datasets for AI model generalization to account for variance in surgical technique and workflows.
Autonomous Navigation for Robot-assisted Intraluminal and Endovascular Procedures: A Systematic Review
May 06, 2023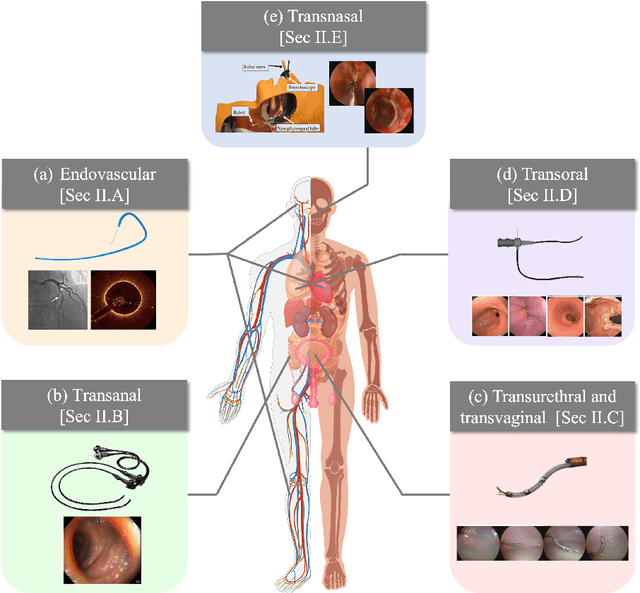
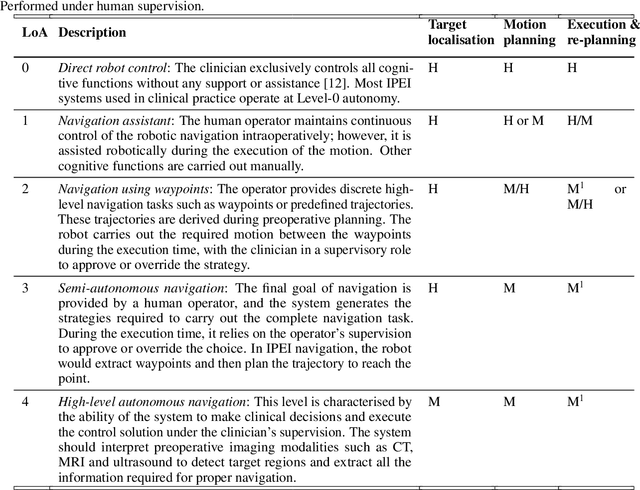
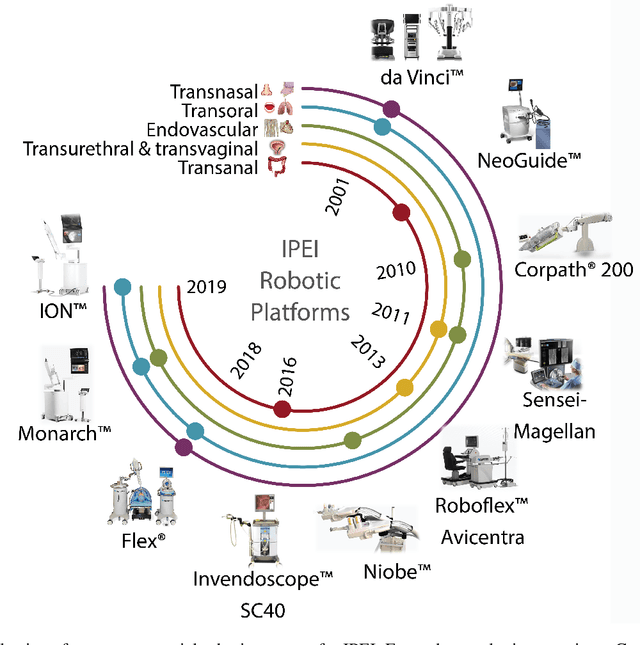

Increased demand for less invasive procedures has accelerated the adoption of Intraluminal Procedures (IP) and Endovascular Interventions (EI) performed through body lumens and vessels. As navigation through lumens and vessels is quite complex, interest grows to establish autonomous navigation techniques for IP and EI for reaching the target area. Current research efforts are directed toward increasing the Level of Autonomy (LoA) during the navigation phase. One key ingredient for autonomous navigation is Motion Planning (MP) techniques. This paper provides an overview of MP techniques categorizing them based on LoA. Our analysis investigates advances for the different clinical scenarios. Through a systematic literature analysis using the PRISMA method, the study summarizes relevant works and investigates the clinical aim, LoA, adopted MP techniques, and validation types. We identify the limitations of the corresponding MP methods and provide directions to improve the robustness of the algorithms in dynamic intraluminal environments. MP for IP and EI can be classified into four subgroups: node, sampling, optimization, and learning-based techniques, with a notable rise in learning-based approaches in recent years. One of the review's contributions is the identification of the limiting factors in IP and EI robotic systems hindering higher levels of autonomous navigation. In the future, navigation is bound to become more autonomous, placing the clinician in a supervisory position to improve control precision and reduce workload.
Constrained Reinforcement Learning and Formal Verification for Safe Colonoscopy Navigation
Mar 16, 2023



The field of robotic Flexible Endoscopes (FEs) has progressed significantly, offering a promising solution to reduce patient discomfort. However, the limited autonomy of most robotic FEs results in non-intuitive and challenging manoeuvres, constraining their application in clinical settings. While previous studies have employed lumen tracking for autonomous navigation, they fail to adapt to the presence of obstructions and sharp turns when the endoscope faces the colon wall. In this work, we propose a Deep Reinforcement Learning (DRL)-based navigation strategy that eliminates the need for lumen tracking. However, the use of DRL methods poses safety risks as they do not account for potential hazards associated with the actions taken. To ensure safety, we exploit a Constrained Reinforcement Learning (CRL) method to restrict the policy in a predefined safety regime. Moreover, we present a model selection strategy that utilises Formal Verification (FV) to choose a policy that is entirely safe before deployment. We validate our approach in a virtual colonoscopy environment and report that out of the 300 trained policies, we could identify three policies that are entirely safe. Our work demonstrates that CRL, combined with model selection through FV, can improve the robustness and safety of robotic behaviour in surgical applications.