 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHateful Meme Classification
Papers and Code
ToxicTAGS: Decoding Toxic Memes with Rich Tag Annotations
Aug 06, 2025



The 2025 Global Risks Report identifies state-based armed conflict and societal polarisation among the most pressing global threats, with social media playing a central role in amplifying toxic discourse. Memes, as a widely used mode of online communication, often serve as vehicles for spreading harmful content. However, limitations in data accessibility and the high cost of dataset curation hinder the development of robust meme moderation systems. To address this challenge, in this work, we introduce a first-of-its-kind dataset of 6,300 real-world meme-based posts annotated in two stages: (i) binary classification into toxic and normal, and (ii) fine-grained labelling of toxic memes as hateful, dangerous, or offensive. A key feature of this dataset is that it is enriched with auxiliary metadata of socially relevant tags, enhancing the context of each meme. In addition, we propose a tag generation module that produces socially grounded tags, because most in-the-wild memes often do not come with tags. Experimental results show that incorporating these tags substantially enhances the performance of state-of-the-art VLMs detection tasks. Our contributions offer a novel and scalable foundation for improved content moderation in multimodal online environments.
LLM-based Semantic Augmentation for Harmful Content Detection
Apr 22, 2025Recent advances in large language models (LLMs) have demonstrated strong performance on simple text classification tasks, frequently under zero-shot settings. However, their efficacy declines when tackling complex social media challenges such as propaganda detection, hateful meme classification, and toxicity identification. Much of the existing work has focused on using LLMs to generate synthetic training data, overlooking the potential of LLM-based text preprocessing and semantic augmentation. In this paper, we introduce an approach that prompts LLMs to clean noisy text and provide context-rich explanations, thereby enhancing training sets without substantial increases in data volume. We systematically evaluate on the SemEval 2024 multi-label Persuasive Meme dataset and further validate on the Google Jigsaw toxic comments and Facebook hateful memes datasets to assess generalizability. Our results reveal that zero-shot LLM classification underperforms on these high-context tasks compared to supervised models. In contrast, integrating LLM-based semantic augmentation yields performance on par with approaches that rely on human-annotated data, at a fraction of the cost. These findings underscore the importance of strategically incorporating LLMs into machine learning (ML) pipeline for social media classification tasks, offering broad implications for combating harmful content online.
Improving Multimodal Hateful Meme Detection Exploiting LMM-Generated Knowledge
Apr 14, 2025Memes have become a dominant form of communication in social media in recent years. Memes are typically humorous and harmless, however there are also memes that promote hate speech, being in this way harmful to individuals and groups based on their identity. Therefore, detecting hateful content in memes has emerged as a task of critical importance. The need for understanding the complex interactions of images and their embedded text renders the hateful meme detection a challenging multimodal task. In this paper we propose to address the aforementioned task leveraging knowledge encoded in powerful Large Multimodal Models (LMM). Specifically, we propose to exploit LMMs in a two-fold manner. First, by extracting knowledge oriented to the hateful meme detection task in order to build strong meme representations. Specifically, generic semantic descriptions and emotions that the images along with their embedded texts elicit are extracted, which are then used to train a simple classification head for hateful meme detection. Second, by developing a novel hard mining approach introducing directly LMM-encoded knowledge to the training process, providing further improvements. We perform extensive experiments on two datasets that validate the effectiveness of the proposed method, achieving state-of-the-art performance. Our code and trained models are publicly available at: https://github.com/IDT-ITI/LMM-CLIP-meme.
Detecting and Understanding Hateful Contents in Memes Through Captioning and Visual Question-Answering
Apr 23, 2025Memes are widely used for humor and cultural commentary, but they are increasingly exploited to spread hateful content. Due to their multimodal nature, hateful memes often evade traditional text-only or image-only detection systems, particularly when they employ subtle or coded references. To address these challenges, we propose a multimodal hate detection framework that integrates key components: OCR to extract embedded text, captioning to describe visual content neutrally, sub-label classification for granular categorization of hateful content, RAG for contextually relevant retrieval, and VQA for iterative analysis of symbolic and contextual cues. This enables the framework to uncover latent signals that simpler pipelines fail to detect. Experimental results on the Facebook Hateful Memes dataset reveal that the proposed framework exceeds the performance of unimodal and conventional multimodal models in both accuracy and AUC-ROC.
MemeBLIP2: A novel lightweight multimodal system to detect harmful memes
Apr 29, 2025Memes often merge visuals with brief text to share humor or opinions, yet some memes contain harmful messages such as hate speech. In this paper, we introduces MemeBLIP2, a light weight multimodal system that detects harmful memes by combining image and text features effectively. We build on previous studies by adding modules that align image and text representations into a shared space and fuse them for better classification. Using BLIP-2 as the core vision-language model, our system is evaluated on the PrideMM datasets. The results show that MemeBLIP2 can capture subtle cues in both modalities, even in cases with ironic or culturally specific content, thereby improving the detection of harmful material.
Prompt-enhanced Network for Hateful Meme Classification
Nov 12, 2024



The dynamic expansion of social media has led to an inundation of hateful memes on media platforms, accentuating the growing need for efficient identification and removal. Acknowledging the constraints of conventional multimodal hateful meme classification, which heavily depends on external knowledge and poses the risk of including irrelevant or redundant content, we developed Pen -- a prompt-enhanced network framework based on the prompt learning approach. Specifically, after constructing the sequence through the prompt method and encoding it with a language model, we performed region information global extraction on the encoded sequence for multi-view perception. By capturing global information about inference instances and demonstrations, Pen facilitates category selection by fully leveraging sequence information. This approach significantly improves model classification accuracy. Additionally, to bolster the model's reasoning capabilities in the feature space, we introduced prompt-aware contrastive learning into the framework to improve the quality of sample feature distributions. Through extensive ablation experiments on two public datasets, we evaluate the effectiveness of the Pen framework, concurrently comparing it with state-of-the-art model baselines. Our research findings highlight that Pen surpasses manual prompt methods, showcasing superior generalization and classification accuracy in hateful meme classification tasks. Our code is available at https://github.com/juszzi/Pen.
MIMIC: Multimodal Islamophobic Meme Identification and Classification
Dec 01, 2024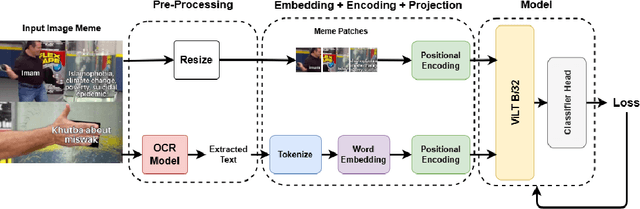

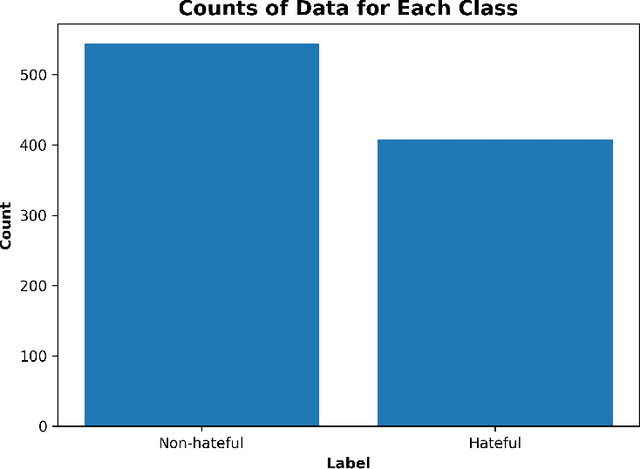
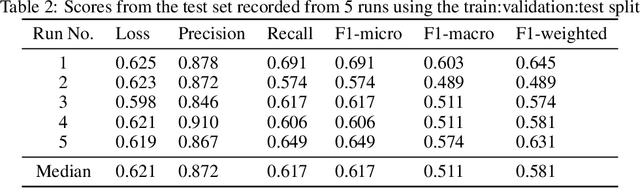
Anti-Muslim hate speech has emerged within memes, characterized by context-dependent and rhetorical messages using text and images that seemingly mimic humor but convey Islamophobic sentiments. This work presents a novel dataset and proposes a classifier based on the Vision-and-Language Transformer (ViLT) specifically tailored to identify anti-Muslim hate within memes by integrating both visual and textual representations. Our model leverages joint modal embeddings between meme images and incorporated text to capture nuanced Islamophobic narratives that are unique to meme culture, providing both high detection accuracy and interoperability.
Improved Fine-Tuning of Large Multimodal Models for Hateful Meme Detection
Feb 18, 2025Hateful memes have become a significant concern on the Internet, necessitating robust automated detection systems. While large multimodal models have shown strong generalization across various tasks, they exhibit poor generalization to hateful meme detection due to the dynamic nature of memes tied to emerging social trends and breaking news. Recent work further highlights the limitations of conventional supervised fine-tuning for large multimodal models in this context. To address these challenges, we propose Large Multimodal Model Retrieval-Guided Contrastive Learning (LMM-RGCL), a novel two-stage fine-tuning framework designed to improve both in-domain accuracy and cross-domain generalization. Experimental results on six widely used meme classification datasets demonstrate that LMM-RGCL achieves state-of-the-art performance, outperforming agent-based systems such as VPD-PALI-X-55B. Furthermore, our method effectively generalizes to out-of-domain memes under low-resource settings, surpassing models like GPT-4o.
Hateful Meme Detection through Context-Sensitive Prompting and Fine-Grained Labeling
Nov 13, 2024The prevalence of multi-modal content on social media complicates automated moderation strategies. This calls for an enhancement in multi-modal classification and a deeper understanding of understated meanings in images and memes. Although previous efforts have aimed at improving model performance through fine-tuning, few have explored an end-to-end optimization pipeline that accounts for modalities, prompting, labeling, and fine-tuning. In this study, we propose an end-to-end conceptual framework for model optimization in complex tasks. Experiments support the efficacy of this traditional yet novel framework, achieving the highest accuracy and AUROC. Ablation experiments demonstrate that isolated optimizations are not ineffective on their own.
Bridging Modalities: Enhancing Cross-Modality Hate Speech Detection with Few-Shot In-Context Learning
Oct 08, 2024The widespread presence of hate speech on the internet, including formats such as text-based tweets and vision-language memes, poses a significant challenge to digital platform safety. Recent research has developed detection models tailored to specific modalities; however, there is a notable gap in transferring detection capabilities across different formats. This study conducts extensive experiments using few-shot in-context learning with large language models to explore the transferability of hate speech detection between modalities. Our findings demonstrate that text-based hate speech examples can significantly enhance the classification accuracy of vision-language hate speech. Moreover, text-based demonstrations outperform vision-language demonstrations in few-shot learning settings. These results highlight the effectiveness of cross-modality knowledge transfer and offer valuable insights for improving hate speech detection systems.