 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multimodal Hateful Meme Detection Exploiting LMM-Generated Knowledge
Apr 14, 2025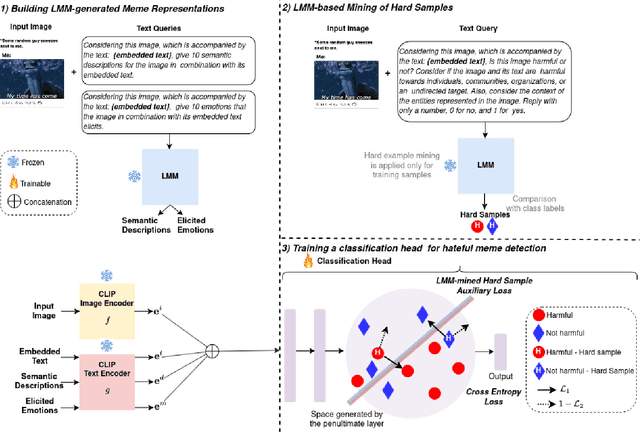



Memes have become a dominant form of communication in social media in recent years. Memes are typically humorous and harmless, however there are also memes that promote hate speech, being in this way harmful to individuals and groups based on their identity. Therefore, detecting hateful content in memes has emerged as a task of critical importance. The need for understanding the complex interactions of images and their embedded text renders the hateful meme detection a challenging multimodal task. In this paper we propose to address the aforementioned task leveraging knowledge encoded in powerful Large Multimodal Models (LMM). Specifically, we propose to exploit LMMs in a two-fold manner. First, by extracting knowledge oriented to the hateful meme detection task in order to build strong meme representations. Specifically, generic semantic descriptions and emotions that the images along with their embedded texts elicit are extracted, which are then used to train a simple classification head for hateful meme detection. Second, by developing a novel hard mining approach introducing directly LMM-encoded knowledge to the training process, providing further improvements. We perform extensive experiments on two datasets that validate the effectiveness of the proposed method, achieving state-of-the-art performance. Our code and trained models are publicly available at: https://github.com/IDT-ITI/LMM-CLIP-meme.
LMM-Regularized CLIP Embeddings for Image Classification
Dec 16, 2024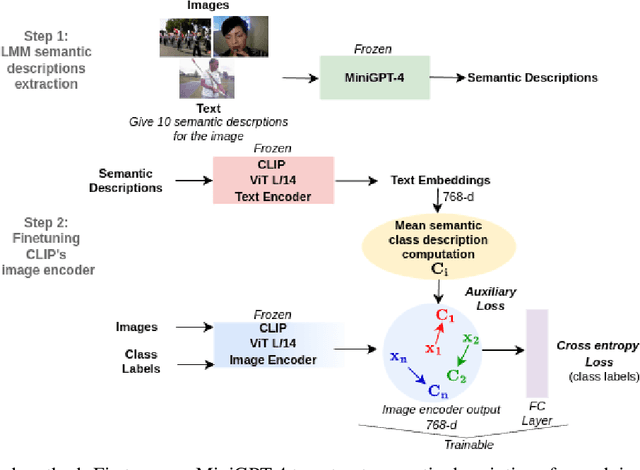

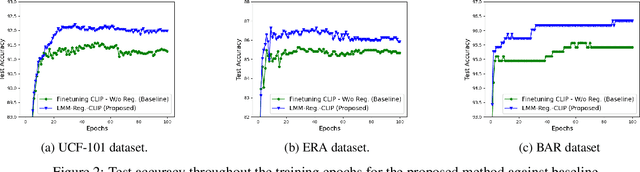
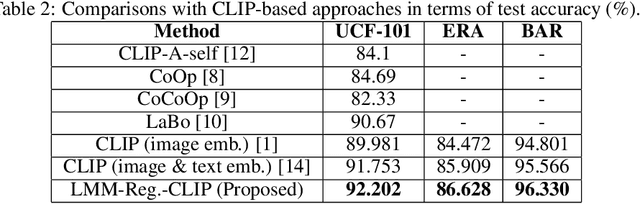
In this paper we deal with image classification tasks using the powerful CLIP vision-language model. Our goal is to advance the classification performance using the CLIP's image encoder, by proposing a novel Large Multimodal Model (LMM) based regularization method. The proposed method uses an LMM to extract semantic descriptions for the images of the dataset. Then, it uses the CLIP's text encoder, frozen, in order to obtain the corresponding text embeddings and compute the mean semantic class descriptions. Subsequently, we adapt the CLIP's image encoder by adding a classification head, and we train it along with the image encoder output, apart from the main classification objective, with an additional auxiliary objective. The additional objective forces the embeddings at the image encoder's output to become similar to their corresponding LMM-generated mean semantic class descriptions. In this way, it produces embeddings with enhanced discrimination ability, leading to improved classification performance. The effectiveness of the proposed regularization method is validated through extensive experiments on three image classification datasets.
Disturbing Image Detection Using LMM-Elicited Emotion Embeddings
Jun 18, 2024



In this paper we deal with the task of Disturbing Image Detection (DID), exploiting knowledge encoded in Large Multimodal Models (LMMs). Specifically, we propose to exploit LMM knowledge in a two-fold manner: first by extracting generic semantic descriptions, and second by extracting elicited emotions. Subsequently, we use the CLIP's text encoder in order to obtain the text embeddings of both the generic semantic descriptions and LMM-elicited emotions. Finally, we use the aforementioned text embeddings along with the corresponding CLIP's image embeddings for performing the DID task. The proposed method significantly improves the baseline classification accuracy, achieving state-of-the-art performance on the augmented Disturbing Image Detection dataset.
Online Anchor-based Training for Image Classification Tasks
Jun 18, 2024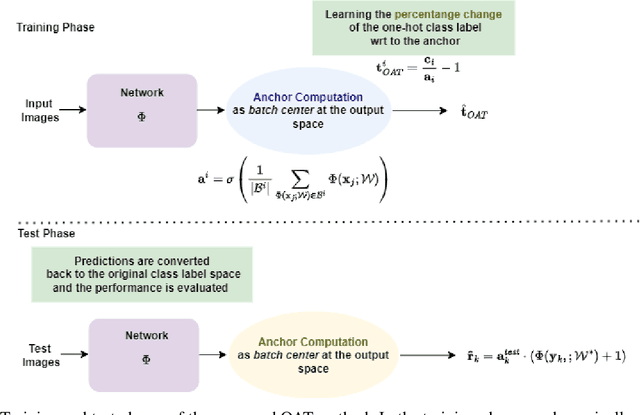
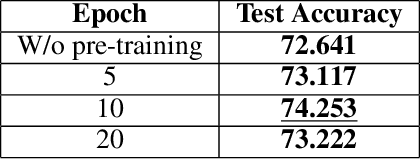
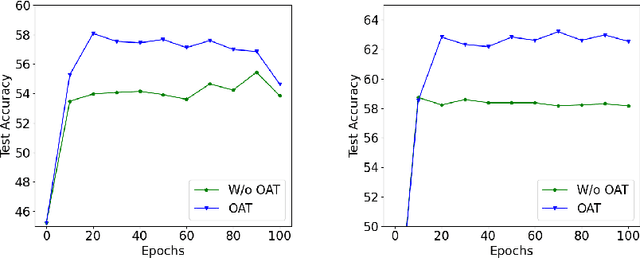

In this paper, we aim to improve the performance of a deep learning model towards image classification tasks, proposing a novel anchor-based training methodology, named \textit{Online Anchor-based Training} (OAT). The OAT method, guided by the insights provided in the anchor-based object detection methodologies, instead of learning directly the class labels, proposes to train a model to learn percentage changes of the class labels with respect to defined anchors. We define as anchors the batch centers at the output of the model. Then, during the test phase, the predictions are converted back to the original class label space, and the performance is evaluated. The effectiveness of the OAT method is validated on four datasets.
Exploiting LMM-based knowledge for image classification tasks
Jun 05, 2024In this paper we address image classification tasks leveraging knowledge encoded in Large Multimodal Models (LMMs). More specifically, we use the MiniGPT-4 model to extract semantic descriptions for the images, in a multimodal prompting fashion. In the current literature, vision language models such as CLIP, among other approaches, are utilized as feature extractors, using only the image encoder, for solving image classification tasks. In this paper, we propose to additionally use the text encoder to obtain the text embeddings corresponding to the MiniGPT-4-generated semantic descriptions. Thus, we use both the image and text embeddings for solving the image classification task. The experimental evaluation on three datasets validates the improved classification performance achieved by exploiting LMM-based knowledge.
Deep Learning for Energy Time-Series Analysis and Forecasting
Jun 29, 2023Energy time-series analysis describes the process of analyzing past energy observations and possibly external factors so as to predict the future. Different tasks are involved in the general field of energy time-series analysis and forecasting, with electric load demand forecasting, personalized energy consumption forecasting, as well as renewable energy generation forecasting being among the most common ones. Following the exceptional performance of Deep Learning (DL) in a broad area of vision tasks, DL models have successfully been utilized in time-series forecasting tasks. This paper aims to provide insight into various DL methods geared towards improving the performance in energy time-series forecasting tasks, with special emphasis in Greek Energy Market, and equip the reader with the necessary knowledge to apply these methods in practice.
Efficient training of lightweight neural networks using Online Self-Acquired Knowledge Distillation
Aug 26, 2021
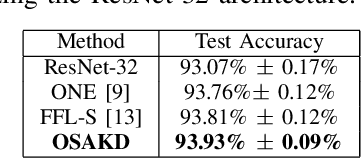
Knowledge Distillation has been established as a highly promising approach for training compact and faster models by transferring knowledge from heavyweight and powerful models. However, KD in its conventional version constitutes an enduring, computationally and memory demanding process. In this paper, Online Self-Acquired Knowledge Distillation (OSAKD) is proposed, aiming to improve the performance of any deep neural model in an online manner. We utilize k-nn non-parametric density estimation technique for estimating the unknown probability distributions of the data samples in the output feature space. This allows us for directly estimating the posterior class probabilities of the data samples, and we use them as soft labels that encode explicit information about the similarities of the data with the classes, negligibly affecting the computational cost. The experimental evaluation on four datasets validates the effectiveness of proposed method.
Quadratic mutual information regularization in real-time deep CNN models
Aug 26, 2021



In this paper, regularized lightweight deep convolutional neural network models, capable of effectively operating in real-time on devices with restricted computational power for high-resolution video input are proposed. Furthermore, a novel regularization method motivated by the Quadratic Mutual Information, in order to improve the generalization ability of the utilized models is proposed. Extensive experiments on various binary classification problems involved in autonomous systems are performed, indicating the effectiveness of the proposed models as well as of the proposed regularizer.
Semantic Scene Segmentation for Robotics Applications
Aug 25, 2021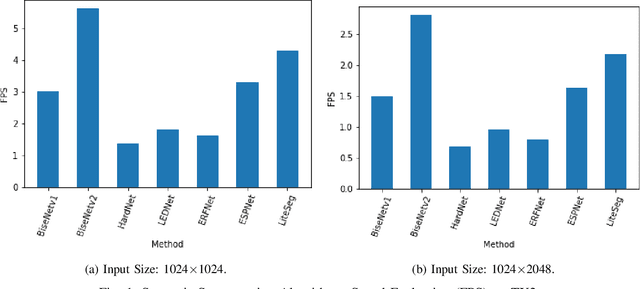
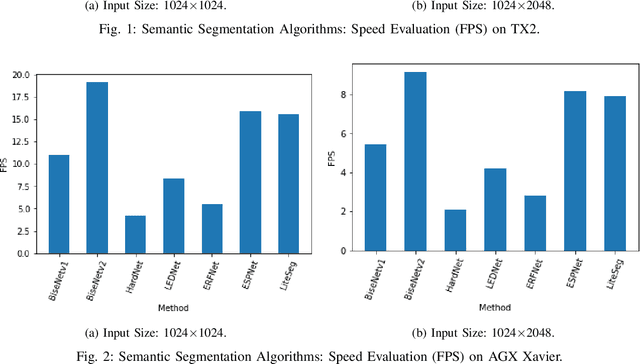
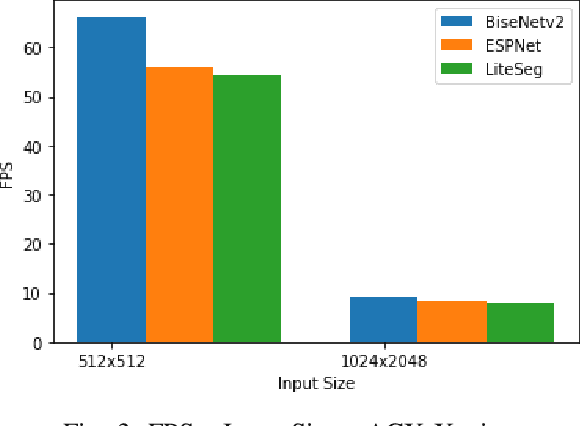
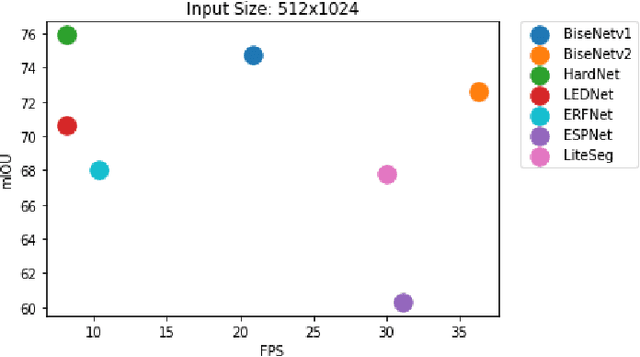
Semantic scene segmentation plays a critical role in a wide range of robotics applications, e.g., autonomous navigation. These applications are accompanied by specific computational restrictions, e.g., operation on low-power GPUs, at sufficient speed, and also for high-resolution input. Existing state-of-the-art segmentation models provide evaluation results under different setups and mainly considering high-power GPUs. In this paper, we investigate the behavior of the most successful semantic scene segmentation models, in terms of deployment (inference) speed, under various setups (GPUs, input sizes, etc.) in the context of robotics applications. The target of this work is to provide a comparative study of current state-of-the-art segmentation models so as to select the most compliant with the robotics applications requirements.
Heterogeneous Knowledge Distillation using Information Flow Modeling
May 02, 2020

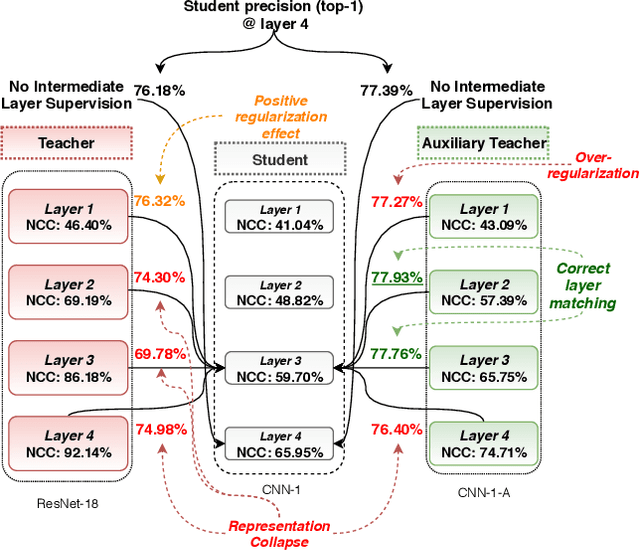

Knowledge Distillation (KD) methods are capable of transferring the knowledge encoded in a large and complex teacher into a smaller and faster student. Early methods were usually limited to transferring the knowledge only between the last layers of the networks, while latter approaches were capable of performing multi-layer KD, further increasing the accuracy of the student. However, despite their improved performance, these methods still suffer from several limitations that restrict both their efficiency and flexibility. First, existing KD methods typically ignore that neural networks undergo through different learning phases during the training process, which often requires different types of supervision for each one. Furthermore, existing multi-layer KD methods are usually unable to effectively handle networks with significantly different architectures (heterogeneous KD). In this paper we propose a novel KD method that works by modeling the information flow through the various layers of the teacher model and then train a student model to mimic this information flow. The proposed method is capable of overcoming the aforementioned limitations by using an appropriate supervision scheme during the different phases of the training process, as well as by designing and training an appropriate auxiliary teacher model that acts as a proxy model capable of "explaining" the way the teacher works to the student. The effectiveness of the proposed method is demonstrated using four image datasets and several different evaluation setups.