 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-CKD: Bottom-Up Cascaded Knowledge Distillation for Vision-Language Models
May 11, 2026Large Vision-Language Models (VLMs) are successful in addressing a multitude of vision-language understanding tasks, such as Visual Question Answering (VQA), but their memory and compute requirements remain a concern for practical deployment. A promising class of techniques for mitigating this concern is Knowledge Distillation, where knowledge from a high-capacity Teacher network is transferred to a considerably smaller Student network. However, the capacity gap between the two networks is both a blessing and a curse: the smaller the Student network, the better its efficiency, and the larger the Teacher, the more knowledge it carries; yet, beyond a point, the larger capacity gap between the two leads to worse knowledge transfer. To counter this effect, we propose a bottom-up cascaded knowledge distillation (CKD) framework. Instead of treating knowledge transfer as an activity involving one high-capacity Teacher (or an ensemble of such), inspired by human formal education systems, we introduce one (potentially, more) additional Teacher(s) of intermediate capacity that gradually bring the Student network to the next level, where the next (higher-capacity) Teacher can take over. We provide a theoretical analysis in order to study the effect of cascaded distillation in the generalization performance of the Student. We apply the proposed framework on models build upon the LLaVA methodology and evaluate the derived models on seven standard, publicly available VQA benchmarks, demonstrating their SotA performance.
Sens-VisualNews: A Benchmark Dataset for Sensational Image Detection
May 11, 2026The detection of sensational content in media items can be a critical filtering mechanism for identifying check-worthy content and flagging potential disinformation, since such content triggers physiological arousal that often bypasses critical evaluation and accelerates viral sharing. In this paper we introduce the task of sensational image detection, which aims to determine whether an image contains shocking, provocative, or emotionally charged features to grab attention and trigger strong emotional responses. To support research on this task, we create a new benchmark dataset (called Sens-VisualNews) that contains 9,576 images from news items, annotated based on the (in-)existence of various sensational concepts and events in their visual content. Finally, using Sens-VisualNews, we study the prompt sensitivity, performance and robustness of a wide range of open SotA Multimodal LLMs, across both zero-shot and fine-tuned settings.
SD-VSum: A Method and Dataset for Script-Driven Video Summarization
May 06, 2025In this work, we introduce the task of script-driven video summarization, which aims to produce a summary of the full-length video by selecting the parts that are most relevant to a user-provided script outlining the visual content of the desired summary. Following, we extend a recently-introduced large-scale dataset for generic video summarization (VideoXum) by producing natural language descriptions of the different human-annotated summaries that are available per video. In this way we make it compatible with the introduced task, since the available triplets of ``video, summary and summary description'' can be used for training a method that is able to produce different summaries for a given video, driven by the provided script about the content of each summary. Finally, we develop a new network architecture for script-driven video summarization (SD-VSum), that relies on the use of a cross-modal attention mechanism for aligning and fusing information from the visual and text modalities. Our experimental evaluations demonstrate the advanced performance of SD-VSum against state-of-the-art approaches for query-driven and generic (unimodal and multimodal) summarization from the literature, and document its capacity to produce video summaries that are adapted to each user's needs about their content.
Improving Multimodal Hateful Meme Detection Exploiting LMM-Generated Knowledge
Apr 14, 2025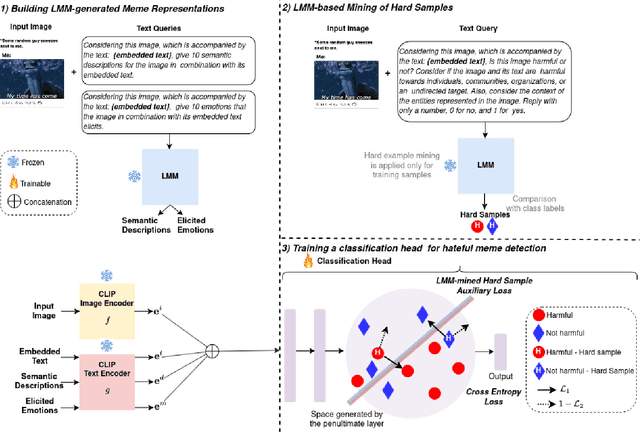



Memes have become a dominant form of communication in social media in recent years. Memes are typically humorous and harmless, however there are also memes that promote hate speech, being in this way harmful to individuals and groups based on their identity. Therefore, detecting hateful content in memes has emerged as a task of critical importance. The need for understanding the complex interactions of images and their embedded text renders the hateful meme detection a challenging multimodal task. In this paper we propose to address the aforementioned task leveraging knowledge encoded in powerful Large Multimodal Models (LMM). Specifically, we propose to exploit LMMs in a two-fold manner. First, by extracting knowledge oriented to the hateful meme detection task in order to build strong meme representations. Specifically, generic semantic descriptions and emotions that the images along with their embedded texts elicit are extracted, which are then used to train a simple classification head for hateful meme detection. Second, by developing a novel hard mining approach introducing directly LMM-encoded knowledge to the training process, providing further improvements. We perform extensive experiments on two datasets that validate the effectiveness of the proposed method, achieving state-of-the-art performance. Our code and trained models are publicly available at: https://github.com/IDT-ITI/LMM-CLIP-meme.
Improving the Perturbation-Based Explanation of Deepfake Detectors Through the Use of Adversarially-Generated Samples
Feb 06, 2025



In this paper, we introduce the idea of using adversarially-generated samples of the input images that were classified as deepfakes by a detector, to form perturbation masks for inferring the importance of different input features and produce visual explanations. We generate these samples based on Natural Evolution Strategies, aiming to flip the original deepfake detector's decision and classify these samples as real. We apply this idea to four perturbation-based explanation methods (LIME, SHAP, SOBOL and RISE) and evaluate the performance of the resulting modified methods using a SOTA deepfake detection model, a benchmarking dataset (FaceForensics++) and a corresponding explanation evaluation framework. Our quantitative assessments document the mostly positive contribution of the proposed perturbation approach in the performance of explanation methods. Our qualitative analysis shows the capacity of the modified explanation methods to demarcate the manipulated image regions more accurately, and thus to provide more useful explanations.
P-TAME: Explain Any Image Classifier with Trained Perturbations
Jan 29, 2025
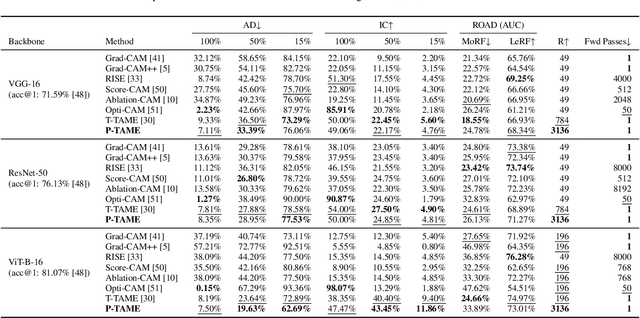
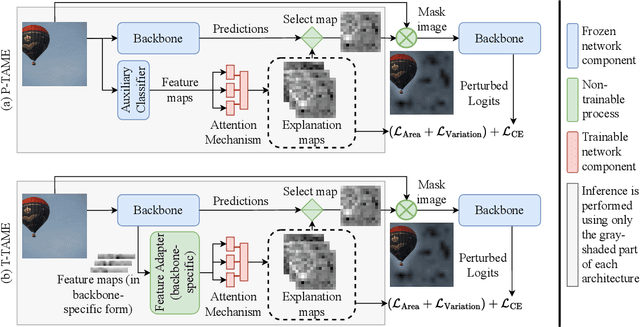
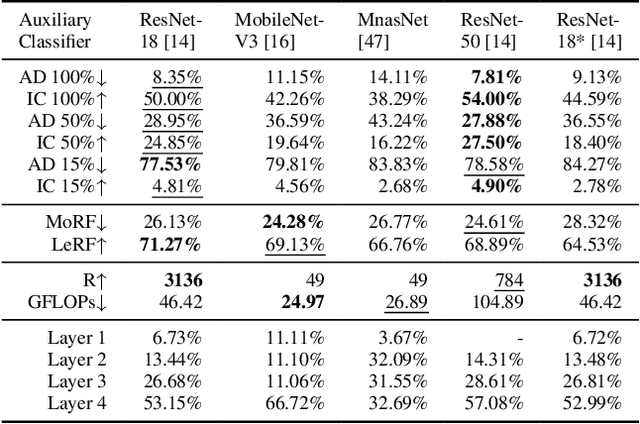
The adoption of Deep Neural Networks (DNNs) in critical fields where predictions need to be accompanied by justifications is hindered by their inherent black-box nature. In this paper, we introduce P-TAME (Perturbation-based Trainable Attention Mechanism for Explanations), a model-agnostic method for explaining DNN-based image classifiers. P-TAME employs an auxiliary image classifier to extract features from the input image, bypassing the need to tailor the explanation method to the internal architecture of the backbone classifier being explained. Unlike traditional perturbation-based methods, which have high computational requirements, P-TAME offers an efficient alternative by generating high-resolution explanations in a single forward pass during inference. We apply P-TAME to explain the decisions of VGG-16, ResNet-50, and ViT-B-16, three distinct and widely used image classifiers. Quantitative and qualitative results show that our method matches or outperforms previous explainability methods, including model-specific approaches. Code and trained models will be released upon acceptance.
B-FPGM: Lightweight Face Detection via Bayesian-Optimized Soft FPGM Pruning
Jan 28, 2025



Face detection is a computer vision application that increasingly demands lightweight models to facilitate deployment on devices with limited computational resources. Neural network pruning is a promising technique that can effectively reduce network size without significantly affecting performance. In this work, we propose a novel face detection pruning pipeline that leverages Filter Pruning via Geometric Median (FPGM) pruning, Soft Filter Pruning (SFP) and Bayesian optimization in order to achieve a superior trade-off between size and performance compared to existing approaches. FPGM pruning is a structured pruning technique that allows pruning the least significant filters in each layer, while SFP iteratively prunes the filters and allows them to be updated in any subsequent training step. Bayesian optimization is employed in order to optimize the pruning rates of each layer, rather than relying on engineering expertise to determine the optimal pruning rates for each layer. In our experiments across all three subsets of the WIDER FACE dataset, our proposed approach B-FPGM consistently outperforms existing ones in balancing model size and performance. All our experiments were applied to EResFD, the currently smallest (in number of parameters) well-performing face detector of the literature; a small ablation study with a second small face detector, EXTD, is also reported. The source code and trained pruned face detection models can be found at: https://github.com/IDTITI/B-FPGM.
VidCtx: Context-aware Video Question Answering with Image Models
Dec 23, 2024To address computational and memory limitations of Large Multimodal Models in the Video Question-Answering task, several recent methods extract textual representations per frame (e.g., by captioning) and feed them to a Large Language Model (LLM) that processes them to produce the final response. However, in this way, the LLM does not have access to visual information and often has to process repetitive textual descriptions of nearby frames. To address those shortcomings, in this paper, we introduce VidCtx, a novel training-free VideoQA framework which integrates both modalities, i.e. both visual information from input frames and textual descriptions of others frames that give the appropriate context. More specifically, in the proposed framework a pre-trained Large Multimodal Model (LMM) is prompted to extract at regular intervals, question-aware textual descriptions (captions) of video frames. Those will be used as context when the same LMM will be prompted to answer the question at hand given as input a) a certain frame, b) the question and c) the context/caption of an appropriate frame. To avoid redundant information, we chose as context the descriptions of distant frames. Finally, a simple yet effective max pooling mechanism is used to aggregate the frame-level decisions. This methodology enables the model to focus on the relevant segments of the video and scale to a high number of frames. Experiments show that VidCtx achieves competitive performance among approaches that rely on open models on three public Video QA benchmarks, NExT-QA, IntentQA and STAR.
LMM-Regularized CLIP Embeddings for Image Classification
Dec 16, 2024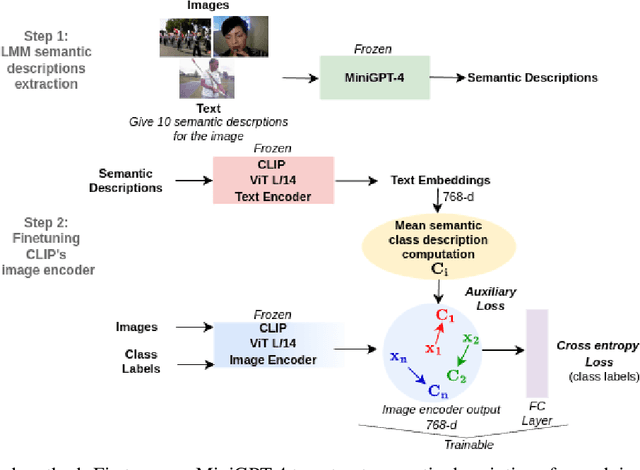

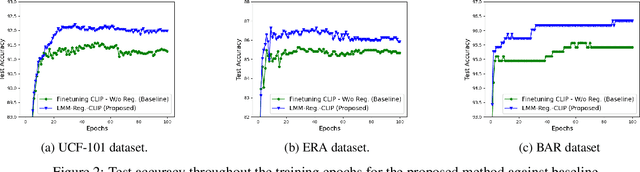
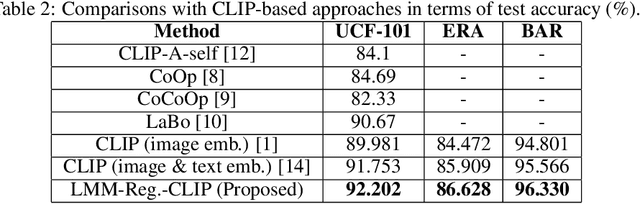
In this paper we deal with image classification tasks using the powerful CLIP vision-language model. Our goal is to advance the classification performance using the CLIP's image encoder, by proposing a novel Large Multimodal Model (LMM) based regularization method. The proposed method uses an LMM to extract semantic descriptions for the images of the dataset. Then, it uses the CLIP's text encoder, frozen, in order to obtain the corresponding text embeddings and compute the mean semantic class descriptions. Subsequently, we adapt the CLIP's image encoder by adding a classification head, and we train it along with the image encoder output, apart from the main classification objective, with an additional auxiliary objective. The additional objective forces the embeddings at the image encoder's output to become similar to their corresponding LMM-generated mean semantic class descriptions. In this way, it produces embeddings with enhanced discrimination ability, leading to improved classification performance. The effectiveness of the proposed regularization method is validated through extensive experiments on three image classification datasets.
Online Anchor-based Training for Image Classification Tasks
Jun 18, 2024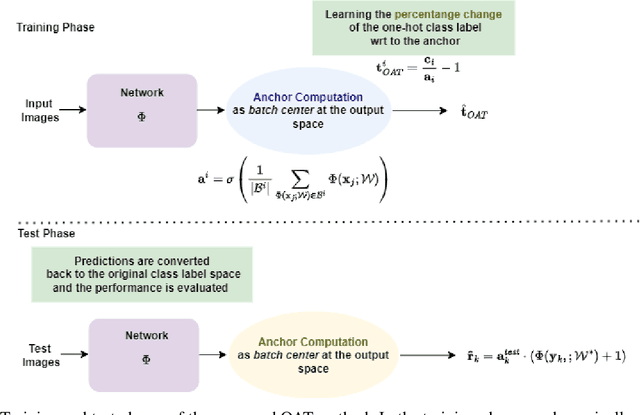
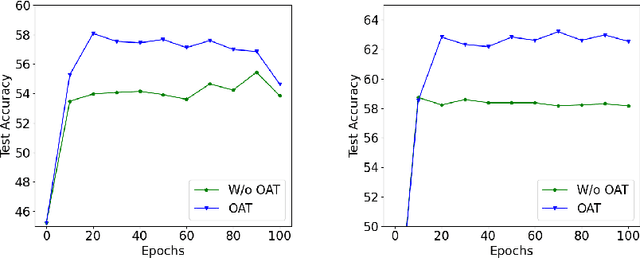

In this paper, we aim to improve the performance of a deep learning model towards image classification tasks, proposing a novel anchor-based training methodology, named \textit{Online Anchor-based Training} (OAT). The OAT method, guided by the insights provided in the anchor-based object detection methodologies, instead of learning directly the class labels, proposes to train a model to learn percentage changes of the class labels with respect to defined anchors. We define as anchors the batch centers at the output of the model. Then, during the test phase, the predictions are converted back to the original class label space, and the performance is evaluated. The effectiveness of the OAT method is validated on four datasets.