 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Perturbation-Based Explanation of Deepfake Detectors Through the Use of Adversarially-Generated Samples
Feb 06, 2025



In this paper, we introduce the idea of using adversarially-generated samples of the input images that were classified as deepfakes by a detector, to form perturbation masks for inferring the importance of different input features and produce visual explanations. We generate these samples based on Natural Evolution Strategies, aiming to flip the original deepfake detector's decision and classify these samples as real. We apply this idea to four perturbation-based explanation methods (LIME, SHAP, SOBOL and RISE) and evaluate the performance of the resulting modified methods using a SOTA deepfake detection model, a benchmarking dataset (FaceForensics++) and a corresponding explanation evaluation framework. Our quantitative assessments document the mostly positive contribution of the proposed perturbation approach in the performance of explanation methods. Our qualitative analysis shows the capacity of the modified explanation methods to demarcate the manipulated image regions more accurately, and thus to provide more useful explanations.
An Integrated Framework for Multi-Granular Explanation of Video Summarization
May 16, 2024
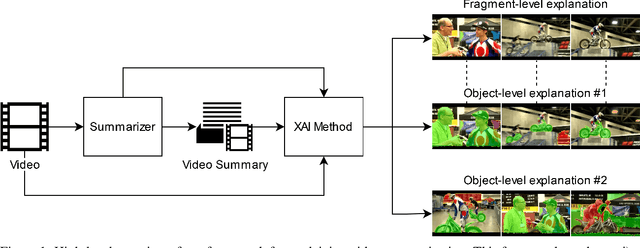
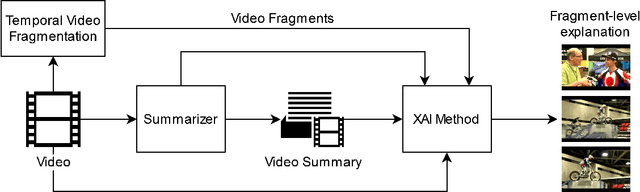
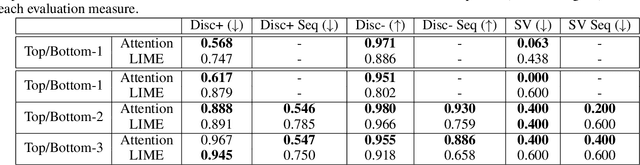
In this paper, we propose an integrated framework for multi-granular explanation of video summarization. This framework integrates methods for producing explanations both at the fragment level (indicating which video fragments influenced the most the decisions of the summarizer) and the more fine-grained visual object level (highlighting which visual objects were the most influential for the summarizer). To build this framework, we extend our previous work on this field, by investigating the use of a model-agnostic, perturbation-based approach for fragment-level explanation of the video summarization results, and introducing a new method that combines the results of video panoptic segmentation with an adaptation of a perturbation-based explanation approach to produce object-level explanations. The performance of the developed framework is evaluated using a state-of-the-art summarization method and two datasets for benchmarking video summarization. The findings of the conducted quantitative and qualitative evaluations demonstrate the ability of our framework to spot the most and least influential fragments and visual objects of the video for the summarizer, and to provide a comprehensive set of visual-based explanations about the output of the summarization process.
Towards Quantitative Evaluation of Explainable AI Methods for Deepfake Detection
Apr 29, 2024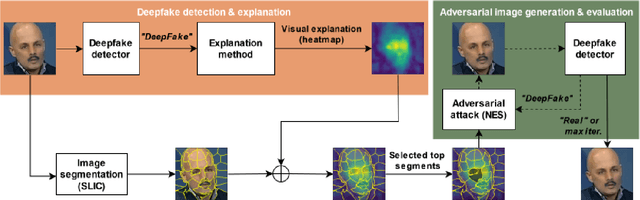
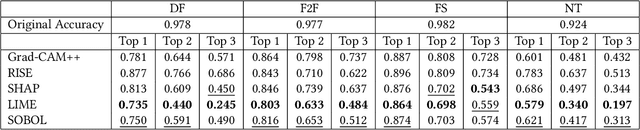
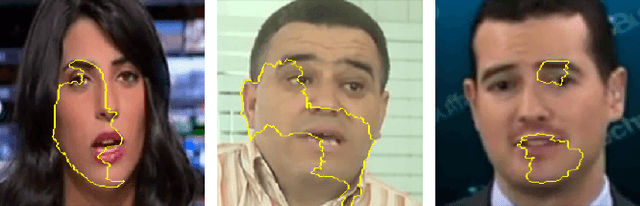

In this paper we propose a new framework for evaluating the performance of explanation methods on the decisions of a deepfake detector. This framework assesses the ability of an explanation method to spot the regions of a fake image with the biggest influence on the decision of the deepfake detector, by examining the extent to which these regions can be modified through a set of adversarial attacks, in order to flip the detector's prediction or reduce its initial prediction; we anticipate a larger drop in deepfake detection accuracy and prediction, for methods that spot these regions more accurately. Based on this framework, we conduct a comparative study using a state-of-the-art model for deepfake detection that has been trained on the FaceForensics++ dataset, and five explanation methods from the literature. The findings of our quantitative and qualitative evaluations document the advanced performance of the LIME explanation method against the other compared ones, and indicate this method as the most appropriate for explaining the decisions of the utilized deepfake detector.