 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Quantitative Evaluation of Explainable AI Methods for Deepfake Detection
Paper and Code
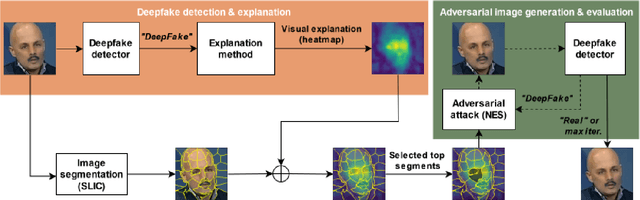
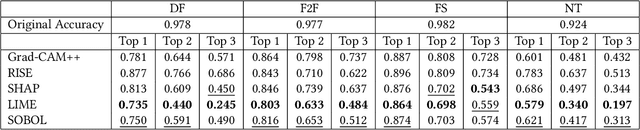
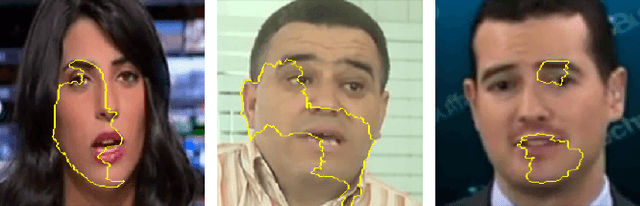

In this paper we propose a new framework for evaluating the performance of explanation methods on the decisions of a deepfake detector. This framework assesses the ability of an explanation method to spot the regions of a fake image with the biggest influence on the decision of the deepfake detector, by examining the extent to which these regions can be modified through a set of adversarial attacks, in order to flip the detector's prediction or reduce its initial prediction; we anticipate a larger drop in deepfake detection accuracy and prediction, for methods that spot these regions more accurately. Based on this framework, we conduct a comparative study using a state-of-the-art model for deepfake detection that has been trained on the FaceForensics++ dataset, and five explanation methods from the literature. The findings of our quantitative and qualitative evaluations document the advanced performance of the LIME explanation method against the other compared ones, and indicate this method as the most appropriate for explaining the decisions of the utilized deepfake detector.