 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSD-VSum: A Method and Dataset for Script-Driven Video Summarization
May 06, 2025In this work, we introduce the task of script-driven video summarization, which aims to produce a summary of the full-length video by selecting the parts that are most relevant to a user-provided script outlining the visual content of the desired summary. Following, we extend a recently-introduced large-scale dataset for generic video summarization (VideoXum) by producing natural language descriptions of the different human-annotated summaries that are available per video. In this way we make it compatible with the introduced task, since the available triplets of ``video, summary and summary description'' can be used for training a method that is able to produce different summaries for a given video, driven by the provided script about the content of each summary. Finally, we develop a new network architecture for script-driven video summarization (SD-VSum), that relies on the use of a cross-modal attention mechanism for aligning and fusing information from the visual and text modalities. Our experimental evaluations demonstrate the advanced performance of SD-VSum against state-of-the-art approaches for query-driven and generic (unimodal and multimodal) summarization from the literature, and document its capacity to produce video summaries that are adapted to each user's needs about their content.
Improving the Perturbation-Based Explanation of Deepfake Detectors Through the Use of Adversarially-Generated Samples
Feb 06, 2025



In this paper, we introduce the idea of using adversarially-generated samples of the input images that were classified as deepfakes by a detector, to form perturbation masks for inferring the importance of different input features and produce visual explanations. We generate these samples based on Natural Evolution Strategies, aiming to flip the original deepfake detector's decision and classify these samples as real. We apply this idea to four perturbation-based explanation methods (LIME, SHAP, SOBOL and RISE) and evaluate the performance of the resulting modified methods using a SOTA deepfake detection model, a benchmarking dataset (FaceForensics++) and a corresponding explanation evaluation framework. Our quantitative assessments document the mostly positive contribution of the proposed perturbation approach in the performance of explanation methods. Our qualitative analysis shows the capacity of the modified explanation methods to demarcate the manipulated image regions more accurately, and thus to provide more useful explanations.
A Human-Annotated Video Dataset for Training and Evaluation of 360-Degree Video Summarization Methods
Jun 05, 2024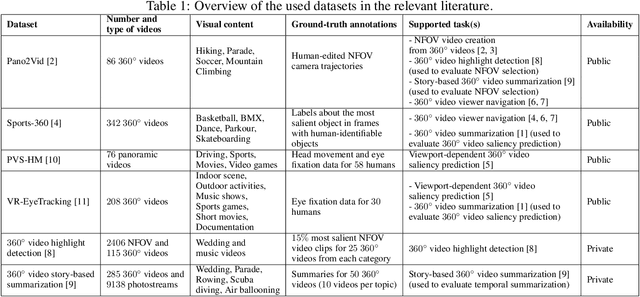
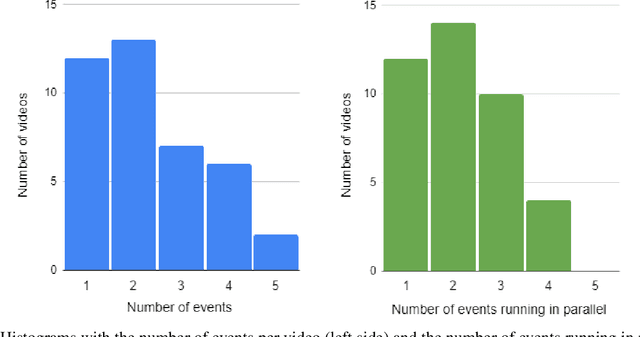
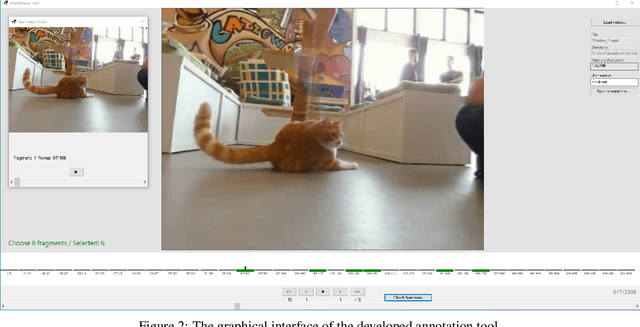
In this paper we introduce a new dataset for 360-degree video summarization: the transformation of 360-degree video content to concise 2D-video summaries that can be consumed via traditional devices, such as TV sets and smartphones. The dataset includes ground-truth human-generated summaries, that can be used for training and objectively evaluating 360-degree video summarization methods. Using this dataset, we train and assess two state-of-the-art summarization methods that were originally proposed for 2D-video summarization, to serve as a baseline for future comparisons with summarization methods that are specifically tailored to 360-degree video. Finally, we present an interactive tool that was developed to facilitate the data annotation process and can assist other annotation activities that rely on video fragment selection.
An Integrated Framework for Multi-Granular Explanation of Video Summarization
May 16, 2024
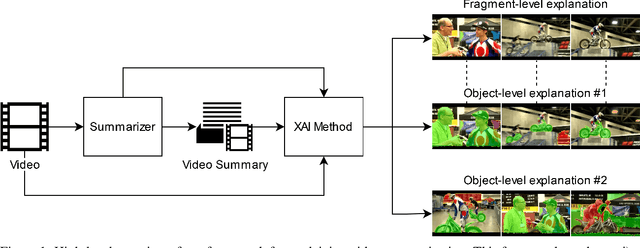
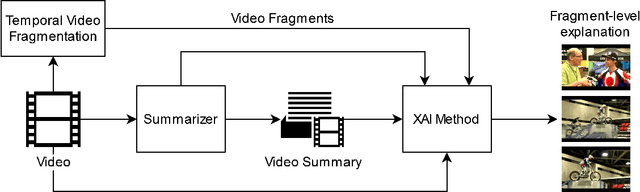
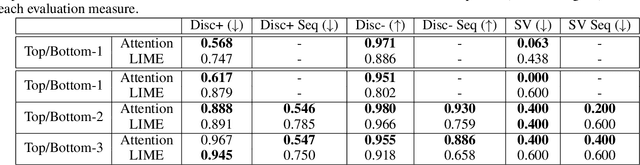
In this paper, we propose an integrated framework for multi-granular explanation of video summarization. This framework integrates methods for producing explanations both at the fragment level (indicating which video fragments influenced the most the decisions of the summarizer) and the more fine-grained visual object level (highlighting which visual objects were the most influential for the summarizer). To build this framework, we extend our previous work on this field, by investigating the use of a model-agnostic, perturbation-based approach for fragment-level explanation of the video summarization results, and introducing a new method that combines the results of video panoptic segmentation with an adaptation of a perturbation-based explanation approach to produce object-level explanations. The performance of the developed framework is evaluated using a state-of-the-art summarization method and two datasets for benchmarking video summarization. The findings of the conducted quantitative and qualitative evaluations demonstrate the ability of our framework to spot the most and least influential fragments and visual objects of the video for the summarizer, and to provide a comprehensive set of visual-based explanations about the output of the summarization process.
Towards Quantitative Evaluation of Explainable AI Methods for Deepfake Detection
Apr 29, 2024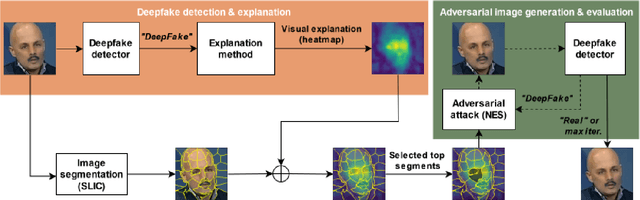
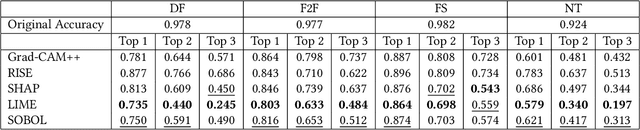
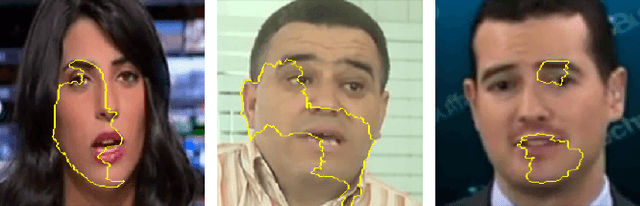

In this paper we propose a new framework for evaluating the performance of explanation methods on the decisions of a deepfake detector. This framework assesses the ability of an explanation method to spot the regions of a fake image with the biggest influence on the decision of the deepfake detector, by examining the extent to which these regions can be modified through a set of adversarial attacks, in order to flip the detector's prediction or reduce its initial prediction; we anticipate a larger drop in deepfake detection accuracy and prediction, for methods that spot these regions more accurately. Based on this framework, we conduct a comparative study using a state-of-the-art model for deepfake detection that has been trained on the FaceForensics++ dataset, and five explanation methods from the literature. The findings of our quantitative and qualitative evaluations document the advanced performance of the LIME explanation method against the other compared ones, and indicate this method as the most appropriate for explaining the decisions of the utilized deepfake detector.
An Integrated System for Spatio-Temporal Summarization of 360-degrees Videos
Dec 05, 2023



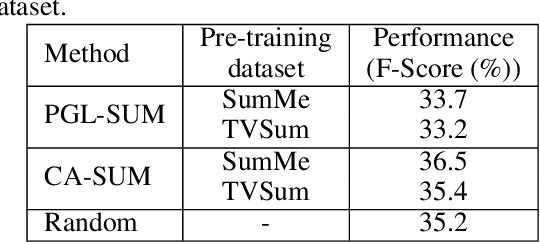
In this work, we present an integrated system for spatiotemporal summarization of 360-degrees videos. The video summary production mainly involves the detection of salient events and their synopsis into a concise summary. The analysis relies on state-of-the-art methods for saliency detection in 360-degrees video (ATSal and SST-Sal) and video summarization (CA-SUM). It also contains a mechanism that classifies a 360-degrees video based on the use of static or moving camera during recording and decides which saliency detection method will be used, as well as a 2D video production component that is responsible to create a conventional 2D video containing the salient events in the 360-degrees video. Quantitative evaluations using two datasets for 360-degrees video saliency detection (VR-EyeTracking, Sports-360) show the accuracy and positive impact of the developed decision mechanism, and justify our choice to use two different methods for detecting the salient events. A qualitative analysis using content from these datasets, gives further insights about the functionality of the decision mechanism, shows the pros and cons of each used saliency detection method and demonstrates the advanced performance of the trained summarization method against a more conventional approach.
Facilitating the Production of Well-tailored Video Summaries for Sharing on Social Media
Dec 05, 2023



This paper presents a web-based tool that facilitates the production of tailored summaries for online sharing on social media. Through an interactive user interface, it supports a ``one-click'' video summarization process. Based on the integrated AI models for video summarization and aspect ratio transformation, it facilitates the generation of multiple summaries of a full-length video according to the needs of target platforms with regard to the video's length and aspect ratio.
Video Summarization Using Deep Neural Networks: A Survey
Jan 15, 2021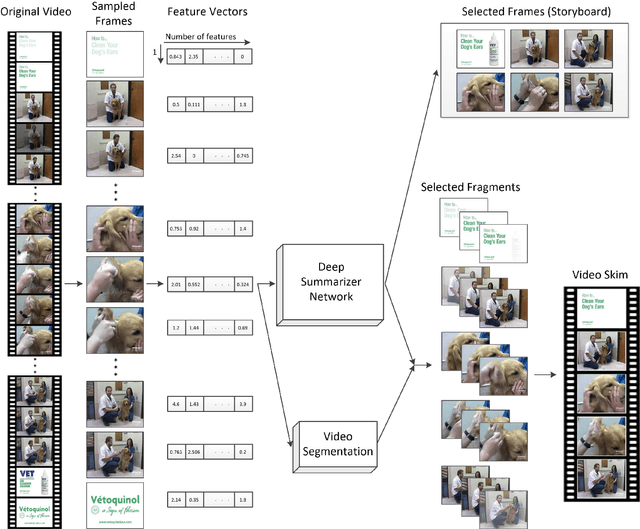
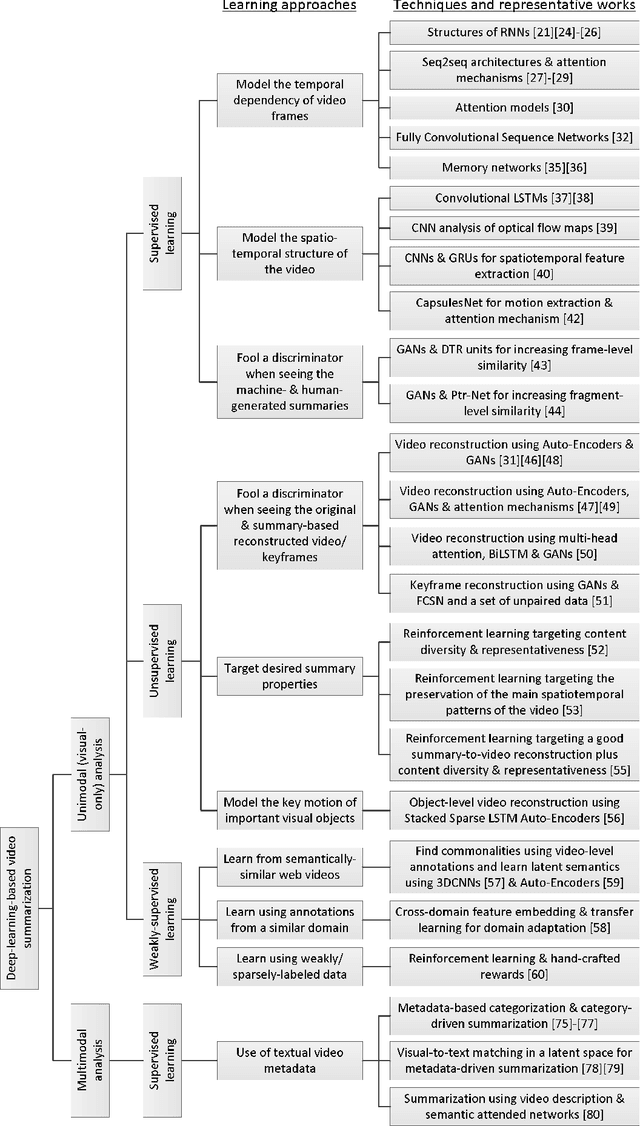
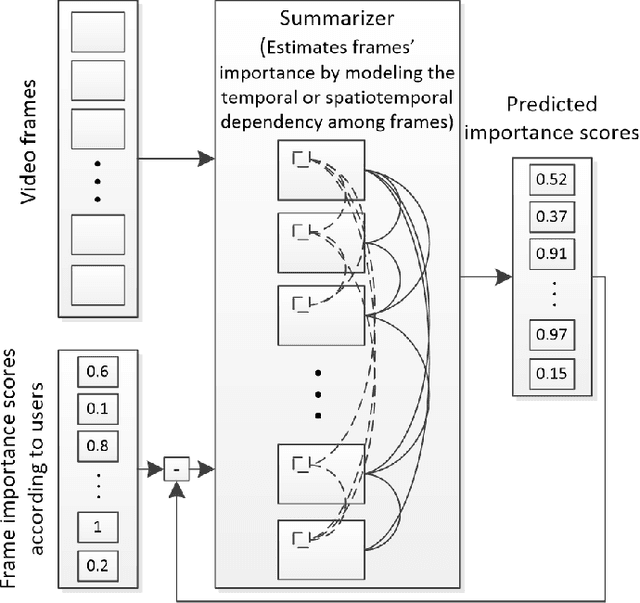
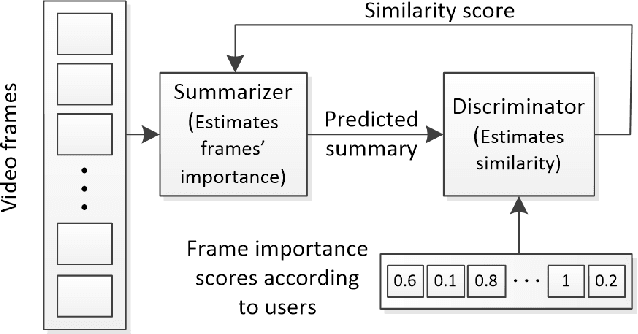
Video summarization technologies aim to create a concise and complete synopsis by selecting the most informative parts of the video content. Several approaches have been developed over the last couple of decades and the current state of the art is represented by methods that rely on modern deep neural network architectures. This work focuses on the recent advances in the area and provides a comprehensive survey of the existing deep-learning-based methods for generic video summarization. After presenting the motivation behind the development of technologies for video summarization, we formulate the video summarization task and discuss the main characteristics of a typical deep-learning-based analysis pipeline. Then, we suggest a taxonomy of the existing algorithms and provide a systematic review of the relevant literature that shows the evolution of the deep-learning-based video summarization technologies and leads to suggestions for future developments. We then report on protocols for the objective evaluation of video summarization algorithms and we compare the performance of several deep-learning-based approaches. Based on the outcomes of these comparisons, as well as some documented considerations about the suitability of evaluation protocols, we indicate potential future research directions.