 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMM-Regularized CLIP Embeddings for Image Classification
Paper and Code
Dec 16, 2024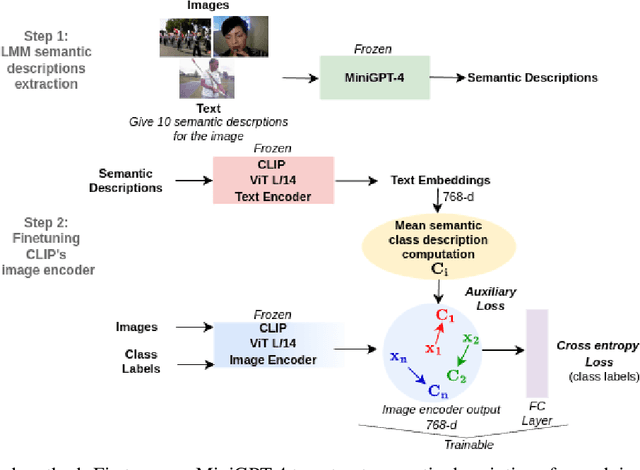

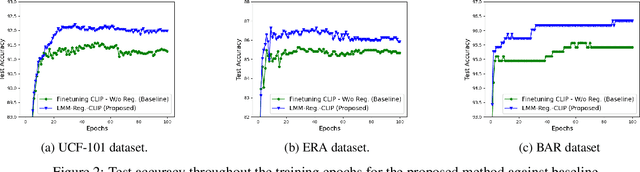
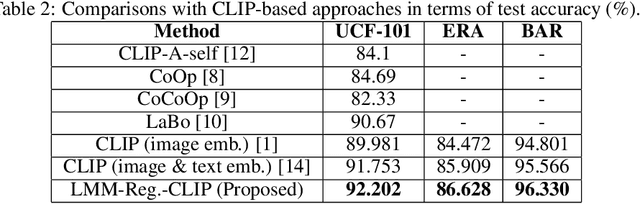
In this paper we deal with image classification tasks using the powerful CLIP vision-language model. Our goal is to advance the classification performance using the CLIP's image encoder, by proposing a novel Large Multimodal Model (LMM) based regularization method. The proposed method uses an LMM to extract semantic descriptions for the images of the dataset. Then, it uses the CLIP's text encoder, frozen, in order to obtain the corresponding text embeddings and compute the mean semantic class descriptions. Subsequently, we adapt the CLIP's image encoder by adding a classification head, and we train it along with the image encoder output, apart from the main classification objective, with an additional auxiliary objective. The additional objective forces the embeddings at the image encoder's output to become similar to their corresponding LMM-generated mean semantic class descriptions. In this way, it produces embeddings with enhanced discrimination ability, leading to improved classification performance. The effectiveness of the proposed regularization method is validated through extensive experiments on three image classification datasets.