 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-TAME: Explain Any Image Classifier with Trained Perturbations
Jan 29, 2025
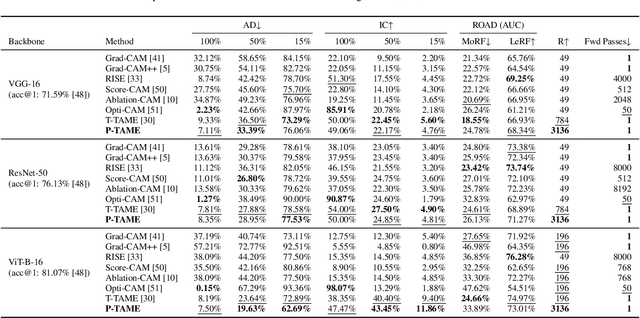
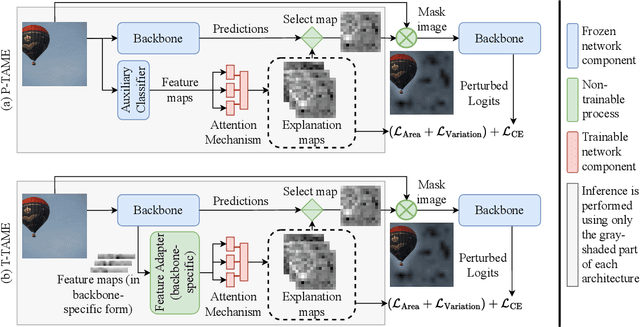
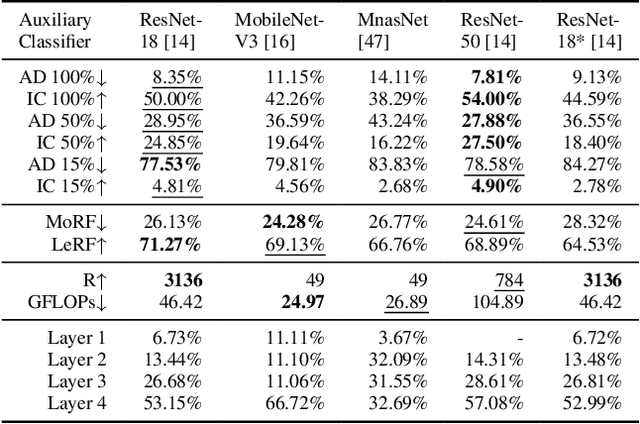
The adoption of Deep Neural Networks (DNNs) in critical fields where predictions need to be accompanied by justifications is hindered by their inherent black-box nature. In this paper, we introduce P-TAME (Perturbation-based Trainable Attention Mechanism for Explanations), a model-agnostic method for explaining DNN-based image classifiers. P-TAME employs an auxiliary image classifier to extract features from the input image, bypassing the need to tailor the explanation method to the internal architecture of the backbone classifier being explained. Unlike traditional perturbation-based methods, which have high computational requirements, P-TAME offers an efficient alternative by generating high-resolution explanations in a single forward pass during inference. We apply P-TAME to explain the decisions of VGG-16, ResNet-50, and ViT-B-16, three distinct and widely used image classifiers. Quantitative and qualitative results show that our method matches or outperforms previous explainability methods, including model-specific approaches. Code and trained models will be released upon acceptance.
T-TAME: Trainable Attention Mechanism for Explaining Convolutional Networks and Vision Transformers
Mar 07, 2024The development and adoption of Vision Transformers and other deep-learning architectures for image classification tasks has been rapid. However, the "black box" nature of neural networks is a barrier to adoption in applications where explainability is essential. While some techniques for generating explanations have been proposed, primarily for Convolutional Neural Networks, adapting such techniques to the new paradigm of Vision Transformers is non-trivial. This paper presents T-TAME, Transformer-compatible Trainable Attention Mechanism for Explanations, a general methodology for explaining deep neural networks used in image classification tasks. The proposed architecture and training technique can be easily applied to any convolutional or Vision Transformer-like neural network, using a streamlined training approach. After training, explanation maps can be computed in a single forward pass; these explanation maps are comparable to or outperform the outputs of computationally expensive perturbation-based explainability techniques, achieving SOTA performance. We apply T-TAME to three popular deep learning classifier architectures, VGG-16, ResNet-50, and ViT-B-16, trained on the ImageNet dataset, and we demonstrate improvements over existing state-of-the-art explainability methods. A detailed analysis of the results and an ablation study provide insights into how the T-TAME design choices affect the quality of the generated explanation maps.