 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaVA-CKD: Bottom-Up Cascaded Knowledge Distillation for Vision-Language Models
May 11, 2026Large Vision-Language Models (VLMs) are successful in addressing a multitude of vision-language understanding tasks, such as Visual Question Answering (VQA), but their memory and compute requirements remain a concern for practical deployment. A promising class of techniques for mitigating this concern is Knowledge Distillation, where knowledge from a high-capacity Teacher network is transferred to a considerably smaller Student network. However, the capacity gap between the two networks is both a blessing and a curse: the smaller the Student network, the better its efficiency, and the larger the Teacher, the more knowledge it carries; yet, beyond a point, the larger capacity gap between the two leads to worse knowledge transfer. To counter this effect, we propose a bottom-up cascaded knowledge distillation (CKD) framework. Instead of treating knowledge transfer as an activity involving one high-capacity Teacher (or an ensemble of such), inspired by human formal education systems, we introduce one (potentially, more) additional Teacher(s) of intermediate capacity that gradually bring the Student network to the next level, where the next (higher-capacity) Teacher can take over. We provide a theoretical analysis in order to study the effect of cascaded distillation in the generalization performance of the Student. We apply the proposed framework on models build upon the LLaVA methodology and evaluate the derived models on seven standard, publicly available VQA benchmarks, demonstrating their SotA performance.
T-TAME: Trainable Attention Mechanism for Explaining Convolutional Networks and Vision Transformers
Mar 07, 2024The development and adoption of Vision Transformers and other deep-learning architectures for image classification tasks has been rapid. However, the "black box" nature of neural networks is a barrier to adoption in applications where explainability is essential. While some techniques for generating explanations have been proposed, primarily for Convolutional Neural Networks, adapting such techniques to the new paradigm of Vision Transformers is non-trivial. This paper presents T-TAME, Transformer-compatible Trainable Attention Mechanism for Explanations, a general methodology for explaining deep neural networks used in image classification tasks. The proposed architecture and training technique can be easily applied to any convolutional or Vision Transformer-like neural network, using a streamlined training approach. After training, explanation maps can be computed in a single forward pass; these explanation maps are comparable to or outperform the outputs of computationally expensive perturbation-based explainability techniques, achieving SOTA performance. We apply T-TAME to three popular deep learning classifier architectures, VGG-16, ResNet-50, and ViT-B-16, trained on the ImageNet dataset, and we demonstrate improvements over existing state-of-the-art explainability methods. A detailed analysis of the results and an ablation study provide insights into how the T-TAME design choices affect the quality of the generated explanation maps.
Filter-Pruning of Lightweight Face Detectors Using a Geometric Median Criterion
Nov 28, 2023
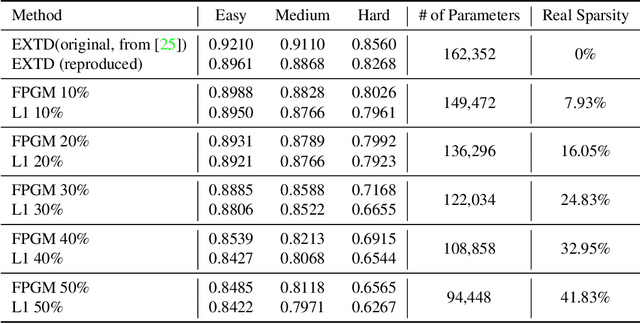
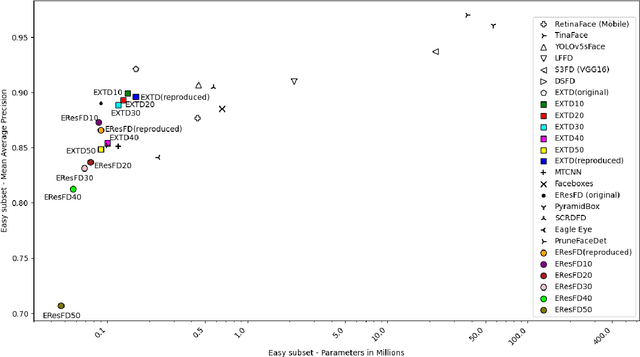
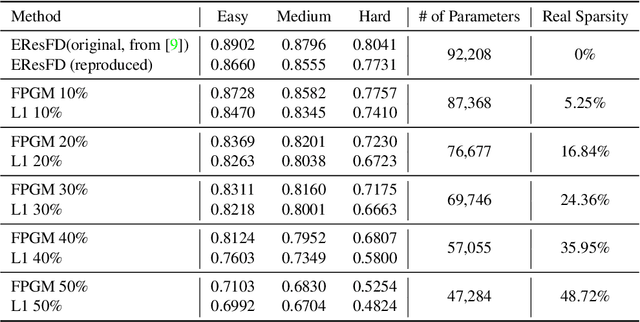
Face detectors are becoming a crucial component of many applications, including surveillance, that often have to run on edge devices with limited processing power and memory. Therefore, there's a pressing demand for compact face detection models that can function efficiently across resource-constrained devices. Over recent years, network pruning techniques have attracted a lot of attention from researchers. These methods haven't been well examined in the context of face detectors, despite their expanding popularity. In this paper, we implement filter pruning on two already small and compact face detectors, named EXTD (Extremely Tiny Face Detector) and EResFD (Efficient ResNet Face Detector). The main pruning algorithm that we utilize is Filter Pruning via Geometric Median (FPGM), combined with the Soft Filter Pruning (SFP) iterative procedure. We also apply L1 Norm pruning, as a baseline to compare with the proposed approach. The experimental evaluation on the WIDER FACE dataset indicates that the proposed approach has the potential to further reduce the model size of already lightweight face detectors, with limited accuracy loss, or even with small accuracy gain for low pruning rates.
Masked Feature Modelling: Feature Masking for the Unsupervised Pre-training of a Graph Attention Network Block for Bottom-up Video Event Recognition
Aug 25, 2023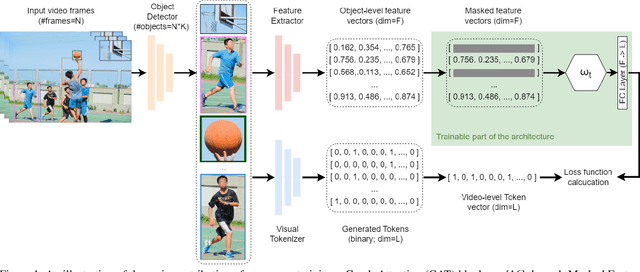
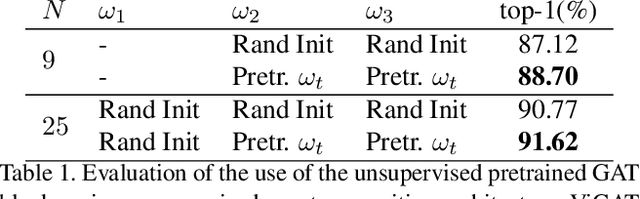
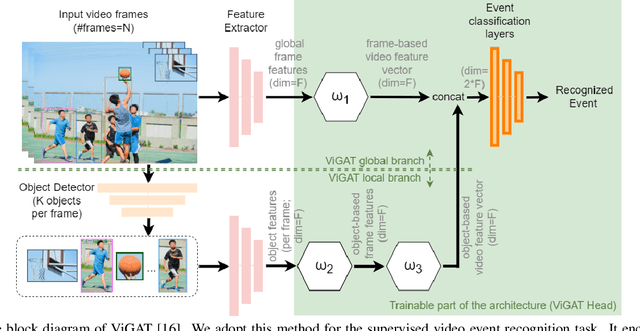

In this paper, we introduce Masked Feature Modelling (MFM), a novel approach for the unsupervised pre-training of a Graph Attention Network (GAT) block. MFM utilizes a pretrained Visual Tokenizer to reconstruct masked features of objects within a video, leveraging the MiniKinetics dataset. We then incorporate the pre-trained GAT block into a state-of-the-art bottom-up supervised video-event recognition architecture, ViGAT, to improve the model's starting point and overall accuracy. Experimental evaluations on the YLI-MED dataset demonstrate the effectiveness of MFM in improving event recognition performance.
Gated-ViGAT: Efficient Bottom-Up Event Recognition and Explanation Using a New Frame Selection Policy and Gating Mechanism
Jan 18, 2023In this paper, Gated-ViGAT, an efficient approach for video event recognition, utilizing bottom-up (object) information, a new frame sampling policy and a gating mechanism is proposed. Specifically, the frame sampling policy uses weighted in-degrees (WiDs), derived from the adjacency matrices of graph attention networks (GATs), and a dissimilarity measure to select the most salient and at the same time diverse frames representing the event in the video. Additionally, the proposed gating mechanism fetches the selected frames sequentially, and commits early-exiting when an adequately confident decision is achieved. In this way, only a few frames are processed by the computationally expensive branch of our network that is responsible for the bottom-up information extraction. The experimental evaluation on two large, publicly available video datasets (MiniKinetics, ActivityNet) demonstrates that Gated-ViGAT provides a large computational complexity reduction in comparison to our previous approach (ViGAT), while maintaining the excellent event recognition and explainability performance. Gated-ViGAT source code is made publicly available at https://github.com/bmezaris/Gated-ViGAT
TAME: Attention Mechanism Based Feature Fusion for Generating Explanation Maps of Convolutional Neural Networks
Jan 18, 2023The apparent ``black box'' nature of neural networks is a barrier to adoption in applications where explainability is essential. This paper presents TAME (Trainable Attention Mechanism for Explanations), a method for generating explanation maps with a multi-branch hierarchical attention mechanism. TAME combines a target model's feature maps from multiple layers using an attention mechanism, transforming them into an explanation map. TAME can easily be applied to any convolutional neural network (CNN) by streamlining the optimization of the attention mechanism's training method and the selection of target model's feature maps. After training, explanation maps can be computed in a single forward pass. We apply TAME to two widely used models, i.e. VGG-16 and ResNet-50, trained on ImageNet and show improvements over previous top-performing methods. We also provide a comprehensive ablation study comparing the performance of different variations of TAME's architecture. TAME source code is made publicly available at https://github.com/bmezaris/TAME
Learning Visual Explanations for DCNN-Based Image Classifiers Using an Attention Mechanism
Sep 22, 2022
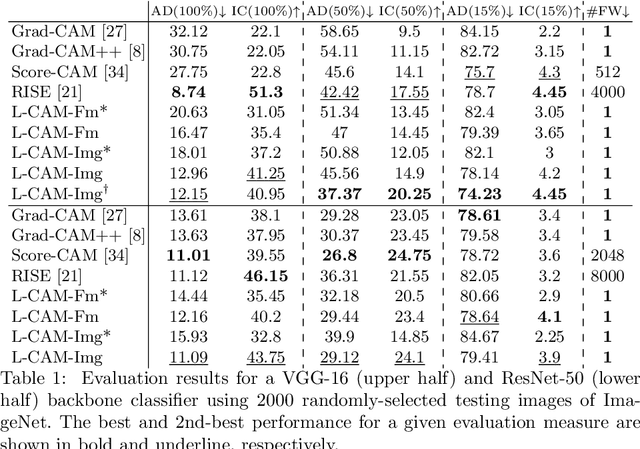
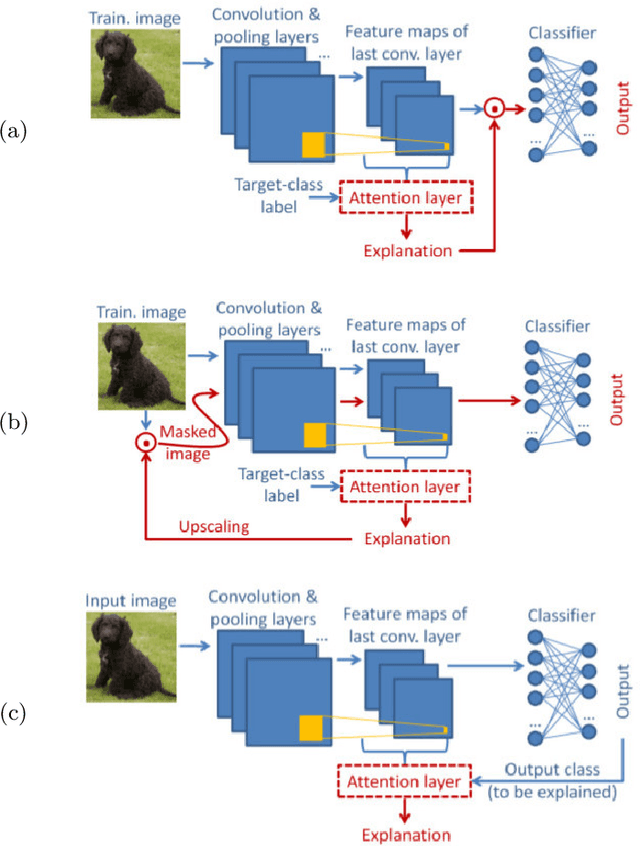

In this paper two new learning-based eXplainable AI (XAI) methods for deep convolutional neural network (DCNN) image classifiers, called L-CAM-Fm and L-CAM-Img, are proposed. Both methods use an attention mechanism that is inserted in the original (frozen) DCNN and is trained to derive class activation maps (CAMs) from the last convolutional layer's feature maps. During training, CAMs are applied to the feature maps (L-CAM-Fm) or the input image (L-CAM-Img) forcing the attention mechanism to learn the image regions explaining the DCNN's outcome. Experimental evaluation on ImageNet shows that the proposed methods achieve competitive results while requiring a single forward pass at the inference stage. Moreover, based on the derived explanations a comprehensive qualitative analysis is performed providing valuable insight for understanding the reasons behind classification errors, including possible dataset biases affecting the trained classifier.
ViGAT: Bottom-up event recognition and explanation in video using factorized graph attention network
Jul 20, 2022


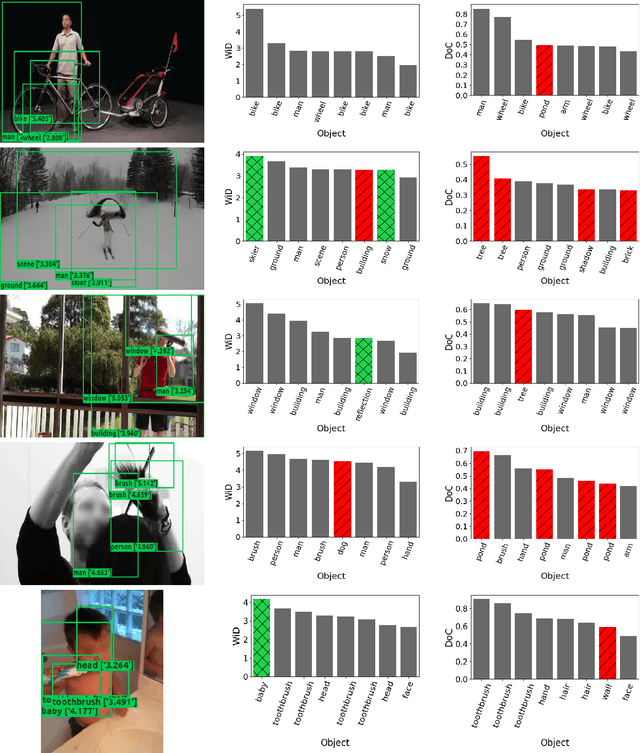
In this paper a pure-attention bottom-up approach, called ViGAT, that utilizes an object detector together with a Vision Transformer (ViT) backbone network to derive object and frame features, and a head network to process these features for the task of event recognition and explanation in video, is proposed. The ViGAT head consists of graph attention network (GAT) blocks factorized along the spatial and temporal dimensions in order to capture effectively both local and long-term dependencies between objects or frames. Moreover, using the weighted in-degrees (WiDs) derived from the adjacency matrices at the various GAT blocks, we show that the proposed architecture can identify the most salient objects and frames that explain the decision of the network. A comprehensive evaluation study is performed, demonstrating that the proposed approach provides state-of-the-art results on three large, publicly available video datasets (FCVID, Mini-Kinetics, ActivityNet).
Accelerated kernel discriminant analysis
Nov 27, 2017In this paper, using a novel matrix factorization and simultaneous reduction to diagonal form approach (or in short simultaneous reduction approach), Accelerated Kernel Discriminant Analysis (AKDA) and Accelerated Kernel Subclass Discriminant Analysis (AKSDA) are proposed. Specifically, instead of performing the simultaneous reduction of the between- and within-class or subclass scatter matrices, the nonzero eigenpairs (NZEP) of the so-called core matrix, which is of relatively small dimensionality, and the Cholesky factorization of the kernel matrix are computed, achieving more than one order of magnitude speed up over kernel discriminant analysis (KDA). Moreover, consisting of a few elementary matrix operations and very stable numerical algorithms, AKDA and AKSDA offer improved classification accuracy. The experimental evaluation on various datasets confirms that the proposed approaches provide state-of-the-art performance in terms of both training time and classification accuracy.