 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViGAT: Bottom-up event recognition and explanation in video using factorized graph attention network
Paper and Code



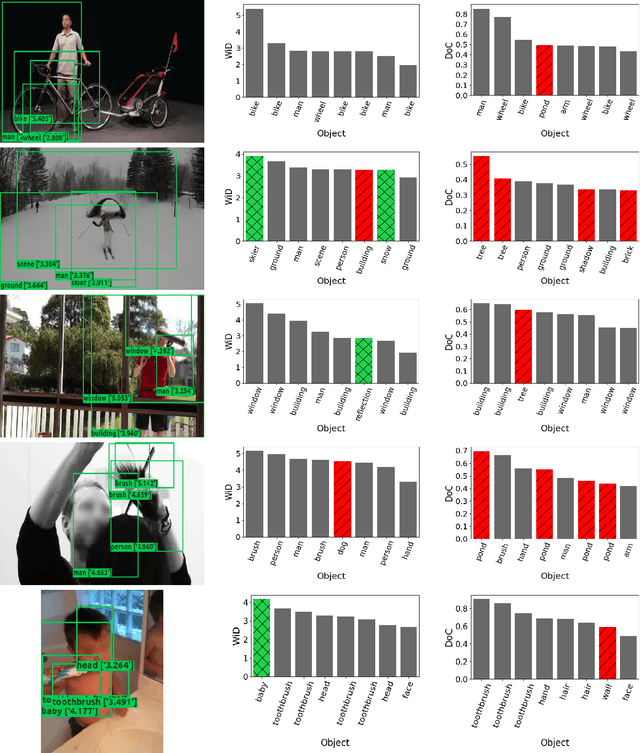
In this paper a pure-attention bottom-up approach, called ViGAT, that utilizes an object detector together with a Vision Transformer (ViT) backbone network to derive object and frame features, and a head network to process these features for the task of event recognition and explanation in video, is proposed. The ViGAT head consists of graph attention network (GAT) blocks factorized along the spatial and temporal dimensions in order to capture effectively both local and long-term dependencies between objects or frames. Moreover, using the weighted in-degrees (WiDs) derived from the adjacency matrices at the various GAT blocks, we show that the proposed architecture can identify the most salient objects and frames that explain the decision of the network. A comprehensive evaluation study is performed, demonstrating that the proposed approach provides state-of-the-art results on three large, publicly available video datasets (FCVID, Mini-Kinetics, ActivityNet).