 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Feature Modelling: Feature Masking for the Unsupervised Pre-training of a Graph Attention Network Block for Bottom-up Video Event Recognition
Aug 25, 2023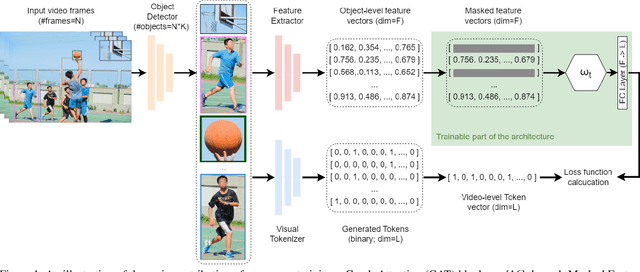
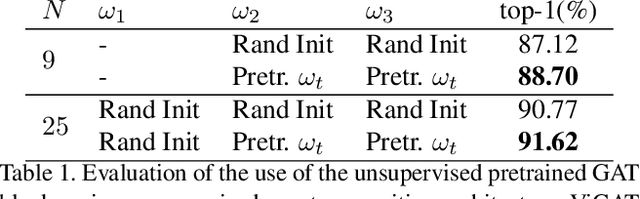

In this paper, we introduce Masked Feature Modelling (MFM), a novel approach for the unsupervised pre-training of a Graph Attention Network (GAT) block. MFM utilizes a pretrained Visual Tokenizer to reconstruct masked features of objects within a video, leveraging the MiniKinetics dataset. We then incorporate the pre-trained GAT block into a state-of-the-art bottom-up supervised video-event recognition architecture, ViGAT, to improve the model's starting point and overall accuracy. Experimental evaluations on the YLI-MED dataset demonstrate the effectiveness of MFM in improving event recognition performance.
Gated-ViGAT: Efficient Bottom-Up Event Recognition and Explanation Using a New Frame Selection Policy and Gating Mechanism
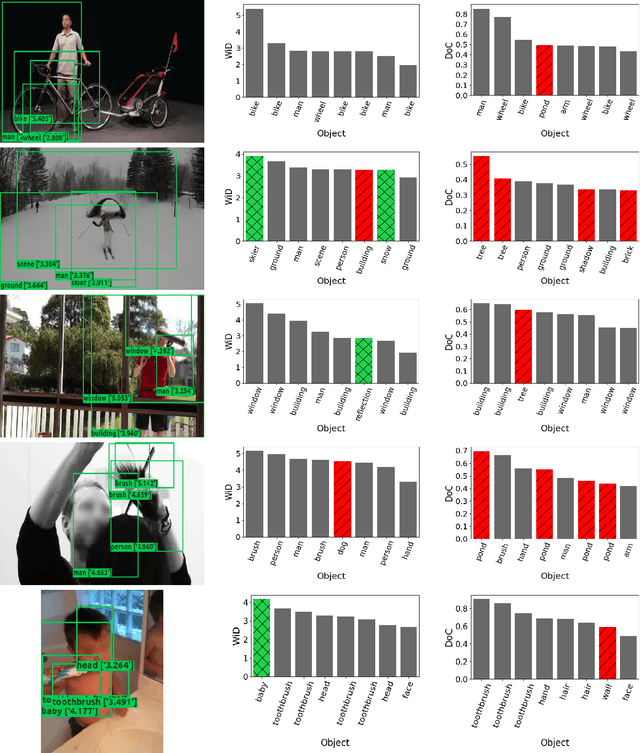
Jan 18, 2023In this paper, Gated-ViGAT, an efficient approach for video event recognition, utilizing bottom-up (object) information, a new frame sampling policy and a gating mechanism is proposed. Specifically, the frame sampling policy uses weighted in-degrees (WiDs), derived from the adjacency matrices of graph attention networks (GATs), and a dissimilarity measure to select the most salient and at the same time diverse frames representing the event in the video. Additionally, the proposed gating mechanism fetches the selected frames sequentially, and commits early-exiting when an adequately confident decision is achieved. In this way, only a few frames are processed by the computationally expensive branch of our network that is responsible for the bottom-up information extraction. The experimental evaluation on two large, publicly available video datasets (MiniKinetics, ActivityNet) demonstrates that Gated-ViGAT provides a large computational complexity reduction in comparison to our previous approach (ViGAT), while maintaining the excellent event recognition and explainability performance. Gated-ViGAT source code is made publicly available at https://github.com/bmezaris/Gated-ViGAT
ViGAT: Bottom-up event recognition and explanation in video using factorized graph attention network
Jul 20, 2022


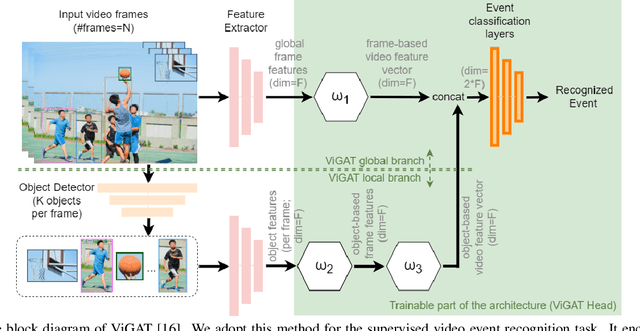
In this paper a pure-attention bottom-up approach, called ViGAT, that utilizes an object detector together with a Vision Transformer (ViT) backbone network to derive object and frame features, and a head network to process these features for the task of event recognition and explanation in video, is proposed. The ViGAT head consists of graph attention network (GAT) blocks factorized along the spatial and temporal dimensions in order to capture effectively both local and long-term dependencies between objects or frames. Moreover, using the weighted in-degrees (WiDs) derived from the adjacency matrices at the various GAT blocks, we show that the proposed architecture can identify the most salient objects and frames that explain the decision of the network. A comprehensive evaluation study is performed, demonstrating that the proposed approach provides state-of-the-art results on three large, publicly available video datasets (FCVID, Mini-Kinetics, ActivityNet).