 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Scene Segmentation for Robotics Applications
Paper and Code
Aug 25, 2021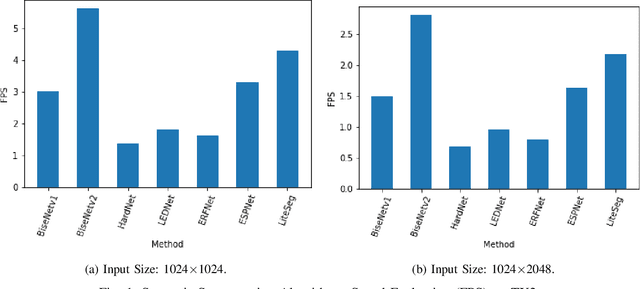
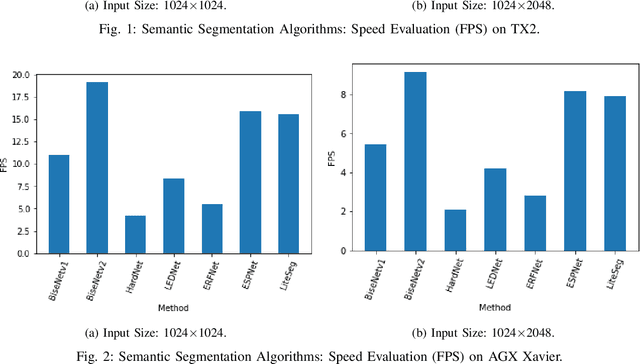
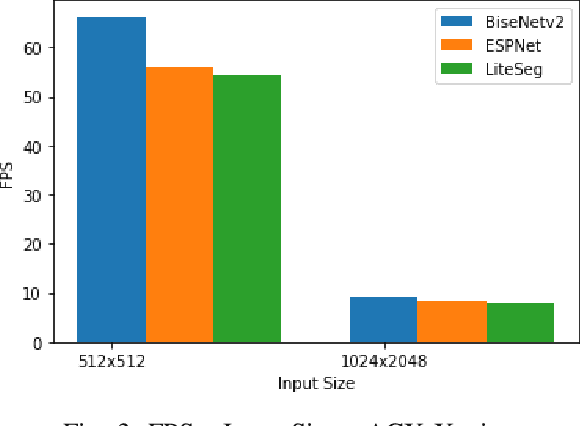
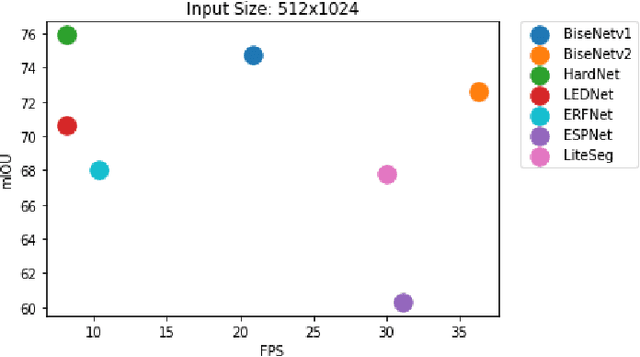
Semantic scene segmentation plays a critical role in a wide range of robotics applications, e.g., autonomous navigation. These applications are accompanied by specific computational restrictions, e.g., operation on low-power GPUs, at sufficient speed, and also for high-resolution input. Existing state-of-the-art segmentation models provide evaluation results under different setups and mainly considering high-power GPUs. In this paper, we investigate the behavior of the most successful semantic scene segmentation models, in terms of deployment (inference) speed, under various setups (GPUs, input sizes, etc.) in the context of robotics applications. The target of this work is to provide a comparative study of current state-of-the-art segmentation models so as to select the most compliant with the robotics applications requirements.