 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Knowledge Distillation using Information Flow Modeling
Paper and Code


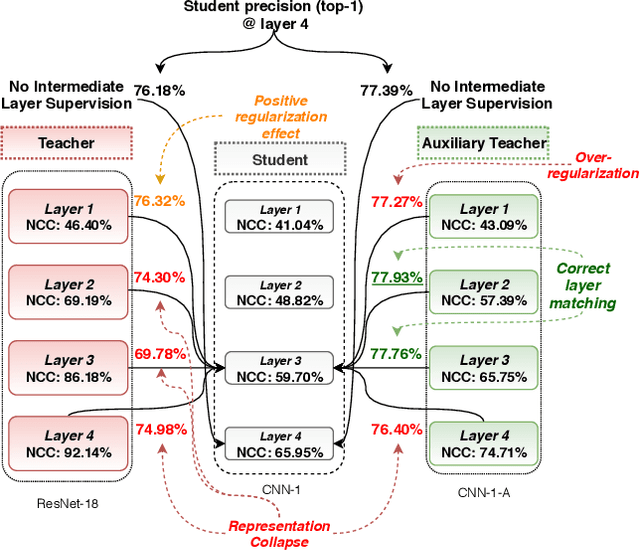

Knowledge Distillation (KD) methods are capable of transferring the knowledge encoded in a large and complex teacher into a smaller and faster student. Early methods were usually limited to transferring the knowledge only between the last layers of the networks, while latter approaches were capable of performing multi-layer KD, further increasing the accuracy of the student. However, despite their improved performance, these methods still suffer from several limitations that restrict both their efficiency and flexibility. First, existing KD methods typically ignore that neural networks undergo through different learning phases during the training process, which often requires different types of supervision for each one. Furthermore, existing multi-layer KD methods are usually unable to effectively handle networks with significantly different architectures (heterogeneous KD). In this paper we propose a novel KD method that works by modeling the information flow through the various layers of the teacher model and then train a student model to mimic this information flow. The proposed method is capable of overcoming the aforementioned limitations by using an appropriate supervision scheme during the different phases of the training process, as well as by designing and training an appropriate auxiliary teacher model that acts as a proxy model capable of "explaining" the way the teacher works to the student. The effectiveness of the proposed method is demonstrated using four image datasets and several different evaluation setups.