 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeautification
Papers and Code
Deceptive Beauty: Evaluating the Impact of Beauty Filters on Deepfake and Morphing Attack Detection
Sep 17, 2025
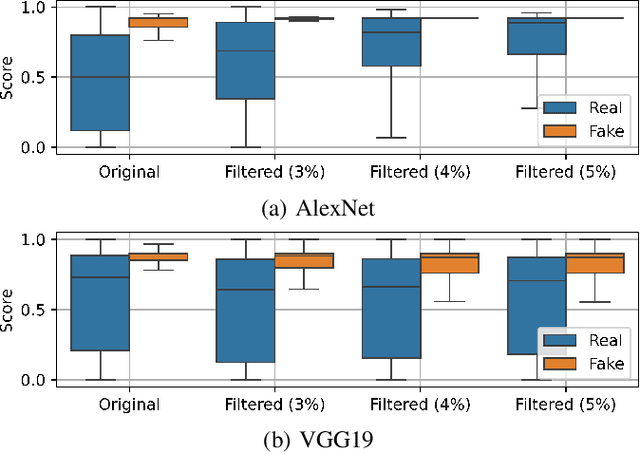
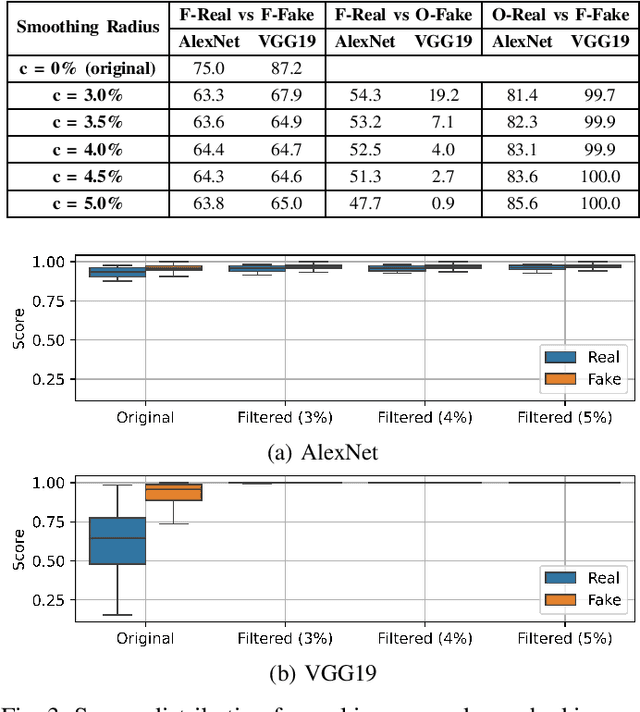

Digital beautification through social media filters has become increasingly popular, raising concerns about the reliability of facial images and videos and the effectiveness of automated face analysis. This issue is particularly critical for digital manipulation detectors, systems aiming at distinguishing between genuine and manipulated data, especially in cases involving deepfakes and morphing attacks designed to deceive humans and automated facial recognition. This study examines whether beauty filters impact the performance of deepfake and morphing attack detectors. We perform a comprehensive analysis, evaluating multiple state-of-the-art detectors on benchmark datasets before and after applying various smoothing filters. Our findings reveal performance degradation, highlighting vulnerabilities introduced by facial enhancements and underscoring the need for robust detection models resilient to such alterations.
AvatarMakeup: Realistic Makeup Transfer for 3D Animatable Head Avatars
Jul 03, 2025Similar to facial beautification in real life, 3D virtual avatars require personalized customization to enhance their visual appeal, yet this area remains insufficiently explored. Although current 3D Gaussian editing methods can be adapted for facial makeup purposes, these methods fail to meet the fundamental requirements for achieving realistic makeup effects: 1) ensuring a consistent appearance during drivable expressions, 2) preserving the identity throughout the makeup process, and 3) enabling precise control over fine details. To address these, we propose a specialized 3D makeup method named AvatarMakeup, leveraging a pretrained diffusion model to transfer makeup patterns from a single reference photo of any individual. We adopt a coarse-to-fine idea to first maintain the consistent appearance and identity, and then to refine the details. In particular, the diffusion model is employed to generate makeup images as supervision. Due to the uncertainties in diffusion process, the generated images are inconsistent across different viewpoints and expressions. Therefore, we propose a Coherent Duplication method to coarsely apply makeup to the target while ensuring consistency across dynamic and multiview effects. Coherent Duplication optimizes a global UV map by recoding the averaged facial attributes among the generated makeup images. By querying the global UV map, it easily synthesizes coherent makeup guidance from arbitrary views and expressions to optimize the target avatar. Given the coarse makeup avatar, we further enhance the makeup by incorporating a Refinement Module into the diffusion model to achieve high makeup quality. Experiments demonstrate that AvatarMakeup achieves state-of-the-art makeup transfer quality and consistency throughout animation.
Artificial Intelligence in Landscape Architecture: A Survey
Aug 26, 2024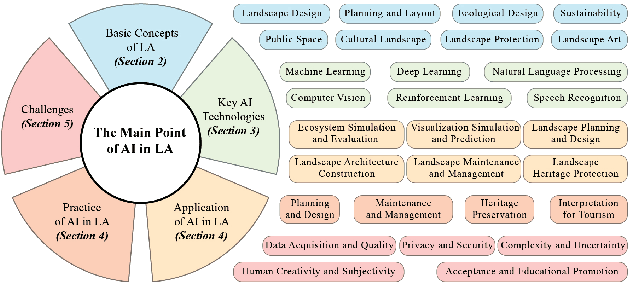
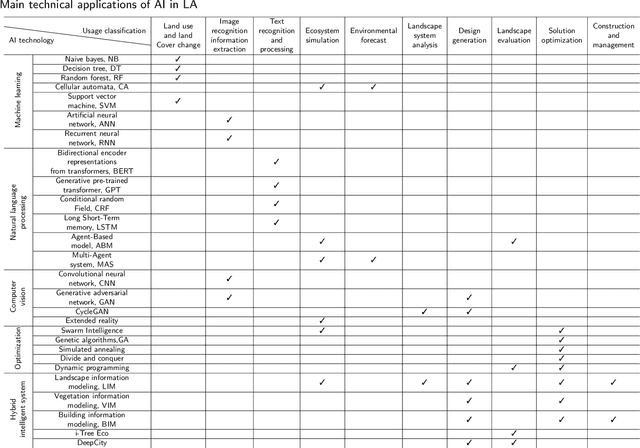
The development history of landscape architecture (LA) reflects the human pursuit of environmental beautification and ecological balance. With the advancement of artificial intelligence (AI) technologies that simulate and extend human intelligence, immense opportunities have been provided for LA, offering scientific and technological support throughout the entire workflow. In this article, we comprehensively review the applications of AI technology in the field of LA. First, we introduce the many potential benefits that AI brings to the design, planning, and management aspects of LA. Secondly, we discuss how AI can assist the LA field in solving its current development problems, including urbanization, environmental degradation and ecological decline, irrational planning, insufficient management and maintenance, and lack of public participation. Furthermore, we summarize the key technologies and practical cases of applying AI in the LA domain, from design assistance to intelligent management, all of which provide innovative solutions for the planning, design, and maintenance of LA. Finally, we look ahead to the problems and opportunities in LA, emphasizing the need to combine human expertise and judgment for rational decision-making. This article provides both theoretical and practical guidance for LA designers, researchers, and technology developers. The successful integration of AI technology into LA holds great promise for enhancing the field's capabilities and achieving more sustainable, efficient, and user-friendly outcomes.
CONTUNER: Singing Voice Beautifying with Pitch and Expressiveness Condition
Apr 30, 2024Singing voice beautifying is a novel task that has application value in people's daily life, aiming to correct the pitch of the singing voice and improve the expressiveness without changing the original timbre and content. Existing methods rely on paired data or only concentrate on the correction of pitch. However, professional songs and amateur songs from the same person are hard to obtain, and singing voice beautifying doesn't only contain pitch correction but other aspects like emotion and rhythm. Since we propose a fast and high-fidelity singing voice beautifying system called ConTuner, a diffusion model combined with the modified condition to generate the beautified Mel-spectrogram, where the modified condition is composed of optimized pitch and expressiveness. For pitch correction, we establish a mapping relationship from MIDI, spectrum envelope to pitch. To make amateur singing more expressive, we propose the expressiveness enhancer in the latent space to convert amateur vocal tone to professional. ConTuner achieves a satisfactory beautification effect on both Mandarin and English songs. Ablation study demonstrates that the expressiveness enhancer and generator-based accelerate method in ConTuner are effective.
FaceFilterSense: A Filter-Resistant Face Recognition and Facial Attribute Analysis Framework
Apr 12, 2024



With the advent of social media, fun selfie filters have come into tremendous mainstream use affecting the functioning of facial biometric systems as well as image recognition systems. These filters vary from beautification filters and Augmented Reality (AR)-based filters to filters that modify facial landmarks. Hence, there is a need to assess the impact of such filters on the performance of existing face recognition systems. The limitation associated with existing solutions is that these solutions focus more on the beautification filters. However, the current AR-based filters and filters which distort facial key points are in vogue recently and make the faces highly unrecognizable even to the naked eye. Also, the filters considered are mostly obsolete with limited variations. To mitigate these limitations, we aim to perform a holistic impact analysis of the latest filters and propose an user recognition model with the filtered images. We have utilized a benchmark dataset for baseline images, and applied the latest filters over them to generate a beautified/filtered dataset. Next, we have introduced a model FaceFilterNet for beautified user recognition. In this framework, we also utilize our model to comment on various attributes of the person including age, gender, and ethnicity. In addition, we have also presented a filter-wise impact analysis on face recognition, age estimation, gender, and ethnicity prediction. The proposed method affirms the efficacy of our dataset with an accuracy of 87.25% and an optimal accuracy for facial attribute analysis.
Sketch Beautification: Learning Part Beautification and Structure Refinement for Sketches of Man-made Objects
Jun 09, 2023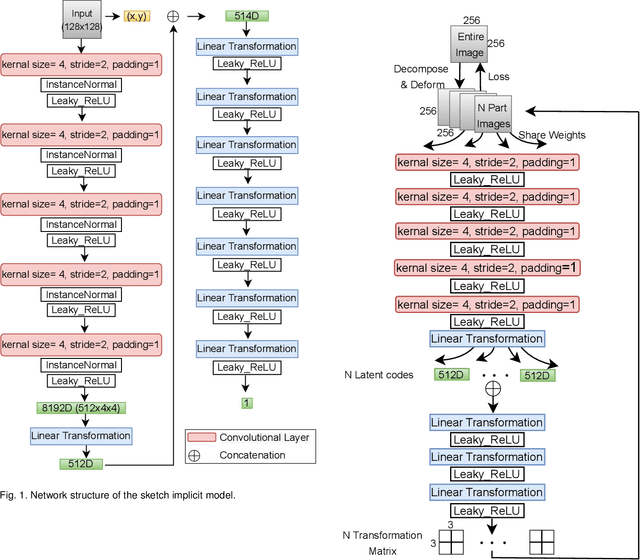
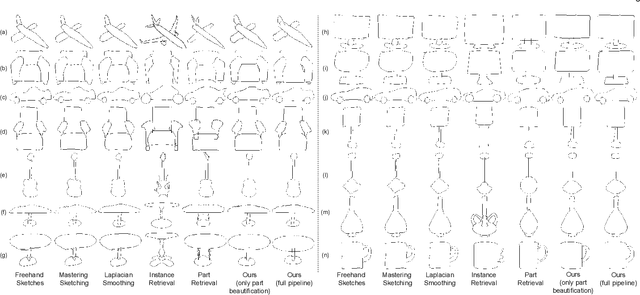
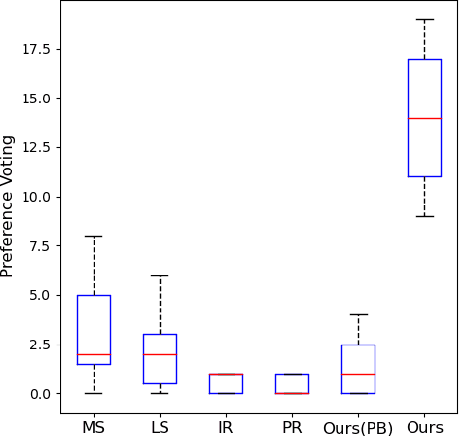
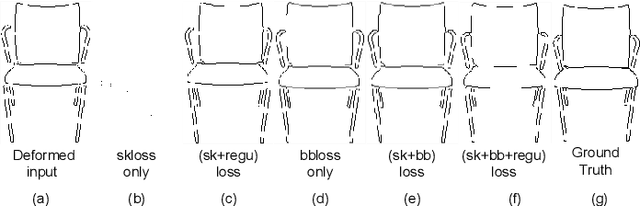
We present a novel freehand sketch beautification method, which takes as input a freely drawn sketch of a man-made object and automatically beautifies it both geometrically and structurally. Beautifying a sketch is challenging because of its highly abstract and heavily diverse drawing manner. Existing methods are usually confined to the distribution of their limited training samples and thus cannot beautify freely drawn sketches with rich variations. To address this challenge, we adopt a divide-and-combine strategy. Specifically, we first parse an input sketch into semantic components, beautify individual components by a learned part beautification module based on part-level implicit manifolds, and then reassemble the beautified components through a structure beautification module. With this strategy, our method can go beyond the training samples and handle novel freehand sketches. We demonstrate the effectiveness of our system with extensive experiments and a perceptive study.
Sampling and Ranking for Digital Ink Generation on a tight computational budget
Jun 02, 2023

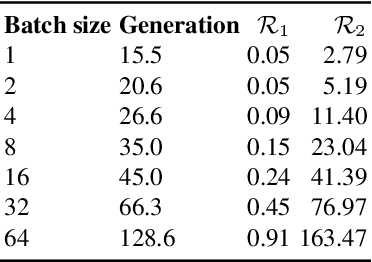

Digital ink (online handwriting) generation has a number of potential applications for creating user-visible content, such as handwriting autocompletion, spelling correction, and beautification. Writing is personal and usually the processing is done on-device. Ink generative models thus need to produce high quality content quickly, in a resource constrained environment. In this work, we study ways to maximize the quality of the output of a trained digital ink generative model, while staying within an inference time budget. We use and compare the effect of multiple sampling and ranking techniques, in the first ablation study of its kind in the digital ink domain. We confirm our findings on multiple datasets - writing in English and Vietnamese, as well as mathematical formulas - using two model types and two common ink data representations. In all combinations, we report a meaningful improvement in the recognizability of the synthetic inks, in some cases more than halving the character error rate metric, and describe a way to select the optimal combination of sampling and ranking techniques for any given computational budget.
EasyPortrait -- Face Parsing and Portrait Segmentation Dataset
May 02, 2023Recently, due to COVID-19 and the growing demand for remote work, video conferencing apps have become especially widespread. The most valuable features of video chats are real-time background removal and face beautification. While solving these tasks, computer vision researchers face the problem of having relevant data for the training stage. There is no large dataset with high-quality labeled and diverse images of people in front of a laptop or smartphone camera to train a lightweight model without additional approaches. To boost the progress in this area, we provide a new image dataset, EasyPortrait, for portrait segmentation and face parsing tasks. It contains 20,000 primarily indoor photos of 8,377 unique users, and fine-grained segmentation masks separated into 9 classes. Images are collected and labeled from crowdsourcing platforms. Unlike most face parsing datasets, in EasyPortrait, the beard is not considered part of the skin mask, and the inside area of the mouth is separated from the teeth. These features allow using EasyPortrait for skin enhancement and teeth whitening tasks. This paper describes the pipeline for creating a large-scale and clean image segmentation dataset using crowdsourcing platforms without additional synthetic data. Moreover, we trained several models on EasyPortrait and showed experimental results. Proposed dataset and trained models are publicly available.
Has the Virtualization of the Face Changed Facial Perception? A Study of the Impact of Augmented Reality on Facial Perception
Mar 01, 2023



Augmented reality and other photo editing filters are popular methods used to modify images, especially images of faces, posted online. Considering the important role of human facial perception in social communication, how does exposure to an increasing number of modified faces online affect human facial perception? In this paper we present the results of six surveys designed to measure familiarity with different styles of facial filters, perceived strangeness of faces edited with different facial filters, and ability to discern whether images are filtered or not. Our results indicate that faces filtered with photo editing filters that change the image color tones, modify facial structure, or add facial beautification tend to be perceived similarly to unmodified faces; however, faces filtered with augmented reality filters (\textit{i.e.,} filters that overlay digital objects) are perceived differently from unmodified faces. We also found that responses differed based on different survey question phrasings, indicating that the shift in facial perception due to the prevalence of filtered images is noisy to detect. A better understanding of shifts in facial perception caused by facial filters will help us build online spaces more responsibly and could inform the training of more accurate and equitable facial recognition models, especially those trained with human psychophysical annotations.
FreeEnricher: Enriching Face Landmarks without Additional Cost
Dec 19, 2022



Recent years have witnessed significant growth of face alignment. Though dense facial landmark is highly demanded in various scenarios, e.g., cosmetic medicine and facial beautification, most works only consider sparse face alignment. To address this problem, we present a framework that can enrich landmark density by existing sparse landmark datasets, e.g., 300W with 68 points and WFLW with 98 points. Firstly, we observe that the local patches along each semantic contour are highly similar in appearance. Then, we propose a weakly-supervised idea of learning the refinement ability on original sparse landmarks and adapting this ability to enriched dense landmarks. Meanwhile, several operators are devised and organized together to implement the idea. Finally, the trained model is applied as a plug-and-play module to the existing face alignment networks. To evaluate our method, we manually label the dense landmarks on 300W testset. Our method yields state-of-the-art accuracy not only in newly-constructed dense 300W testset but also in the original sparse 300W and WFLW testsets without additional cost.