 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeEnricher: Enriching Face Landmarks without Additional Cost
Dec 19, 2022



Recent years have witnessed significant growth of face alignment. Though dense facial landmark is highly demanded in various scenarios, e.g., cosmetic medicine and facial beautification, most works only consider sparse face alignment. To address this problem, we present a framework that can enrich landmark density by existing sparse landmark datasets, e.g., 300W with 68 points and WFLW with 98 points. Firstly, we observe that the local patches along each semantic contour are highly similar in appearance. Then, we propose a weakly-supervised idea of learning the refinement ability on original sparse landmarks and adapting this ability to enriched dense landmarks. Meanwhile, several operators are devised and organized together to implement the idea. Finally, the trained model is applied as a plug-and-play module to the existing face alignment networks. To evaluate our method, we manually label the dense landmarks on 300W testset. Our method yields state-of-the-art accuracy not only in newly-constructed dense 300W testset but also in the original sparse 300W and WFLW testsets without additional cost.
MPS-NeRF: Generalizable 3D Human Rendering from Multiview Images
Mar 31, 2022
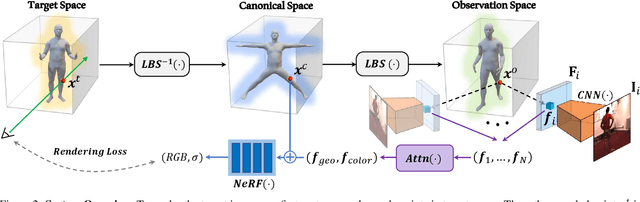


There has been rapid progress recently on 3D human rendering, including novel view synthesis and pose animation, based on the advances of neural radiance fields (NeRF). However, most existing methods focus on person-specific training and their training typically requires multi-view videos. This paper deals with a new challenging task -- rendering novel views and novel poses for a person unseen in training, using only multiview images as input. For this task, we propose a simple yet effective method to train a generalizable NeRF with multiview images as conditional input. The key ingredient is a dedicated representation combining a canonical NeRF and a volume deformation scheme. Using a canonical space enables our method to learn shared properties of human and easily generalize to different people. Volume deformation is used to connect the canonical space with input and target images and query image features for radiance and density prediction. We leverage the parametric 3D human model fitted on the input images to derive the deformation, which works quite well in practice when combined with our canonical NeRF. The experiments on both real and synthetic data with the novel view synthesis and pose animation tasks collectively demonstrate the efficacy of our method.
ADNet: Leveraging Error-Bias Towards Normal Direction in Face Alignment
Sep 13, 2021



The recent progress of CNN has dramatically improved face alignment performance. However, few works have paid attention to the error-bias with respect to error distribution of facial landmarks. In this paper, we investigate the error-bias issue in face alignment, where the distributions of landmark errors tend to spread along the tangent line to landmark curves. This error-bias is not trivial since it is closely connected to the ambiguous landmark labeling task. Inspired by this observation, we seek a way to leverage the error-bias property for better convergence of CNN model. To this end, we propose anisotropic direction loss (ADL) and anisotropic attention module (AAM) for coordinate and heatmap regression, respectively. ADL imposes strong binding force in normal direction for each landmark point on facial boundaries. On the other hand, AAM is an attention module which can get anisotropic attention mask focusing on the region of point and its local edge connected by adjacent points, it has a stronger response in tangent than in normal, which means relaxed constraints in the tangent. These two methods work in a complementary manner to learn both facial structures and texture details. Finally, we integrate them into an optimized end-to-end training pipeline named ADNet. Our ADNet achieves state-of-the-art results on 300W, WFLW and COFW datasets, which demonstrates the effectiveness and robustness.
Video Frame Interpolation by Plug-and-Play Deep Locally Linear Embedding
Jul 04, 2018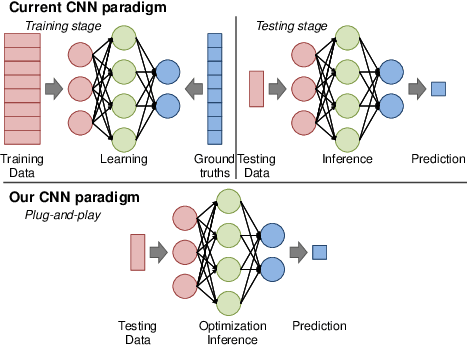
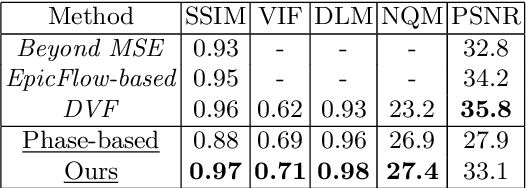
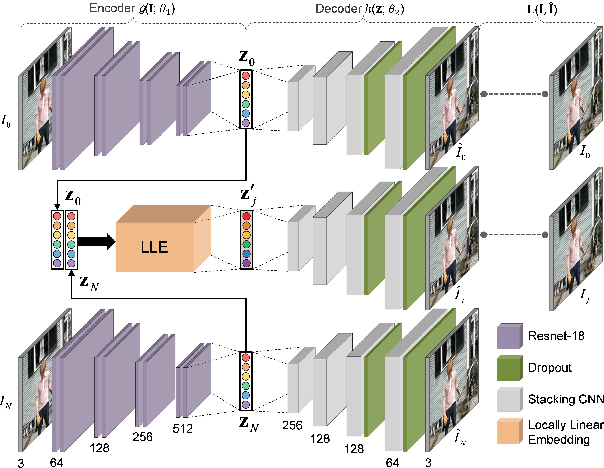
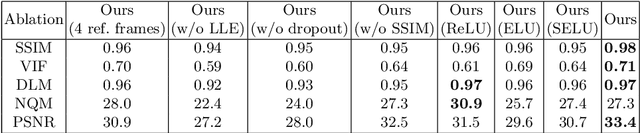
We propose a generative framework which takes on the video frame interpolation problem. Our framework, which we call Deep Locally Linear Embedding (DeepLLE), is powered by a deep convolutional neural network (CNN) while it can be used instantly like conventional models. DeepLLE fits an auto-encoding CNN to a set of several consecutive frames and embeds a linearity constraint on the latent codes so that new frames can be generated by interpolating new latent codes. Different from the current deep learning paradigm which requires training on large datasets, DeepLLE works in a plug-and-play and unsupervised manner, and is able to generate an arbitrary number of frames. Thorough experiments demonstrate that without bells and whistles, our method is highly competitive among current state-of-the-art models.