 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Label Denoising for Weakly-Supervised Audio-Visual Video Parsing
Dec 27, 2024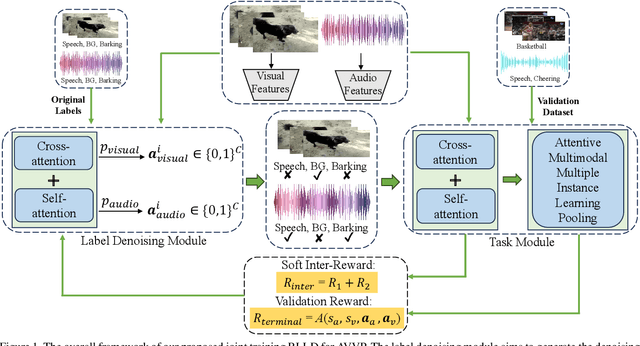
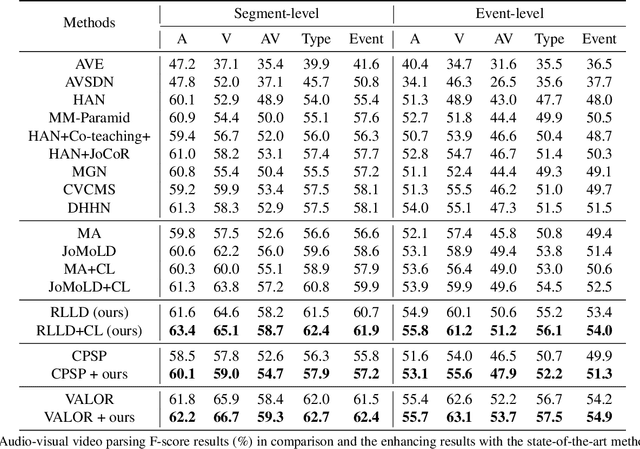
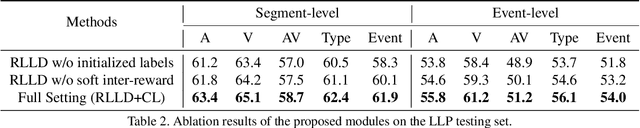
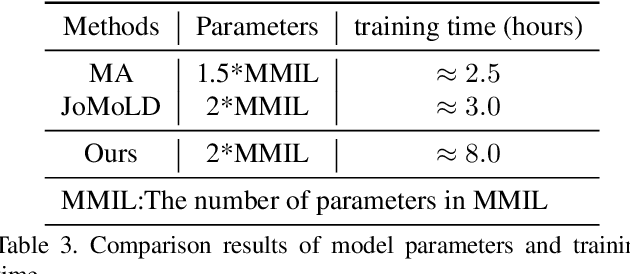
Audio-visual video parsing (AVVP) aims to recognize audio and visual event labels with precise temporal boundaries, which is quite challenging since audio or visual modality might include only one event label with only the overall video labels available. Existing label denoising models often treat the denoising process as a separate preprocessing step, leading to a disconnect between label denoising and AVVP tasks. To bridge this gap, we present a novel joint reinforcement learning-based label denoising approach (RLLD). This approach enables simultaneous training of both label denoising and video parsing models through a joint optimization strategy. We introduce a novel AVVP-validation and soft inter-reward feedback mechanism that directly guides the learning of label denoising policy. Extensive experiments on AVVP tasks demonstrate the superior performance of our proposed method compared to label denoising techniques. Furthermore, by incorporating our label denoising method into other AVVP models, we find that it can further enhance parsing results.
Sketch Beautification: Learning Part Beautification and Structure Refinement for Sketches of Man-made Objects
Jun 09, 2023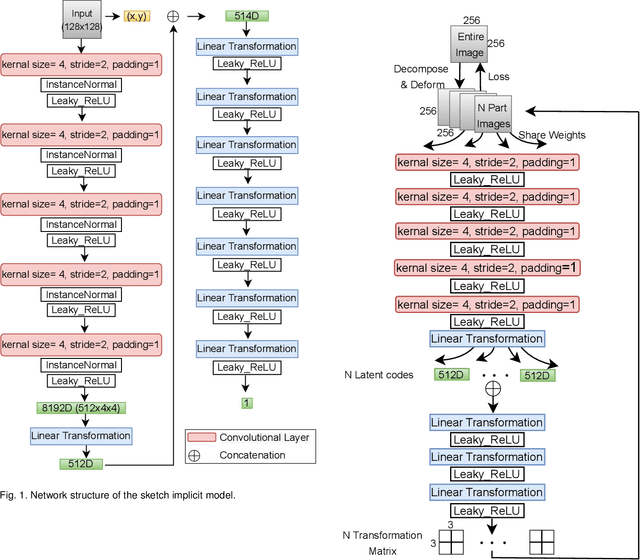
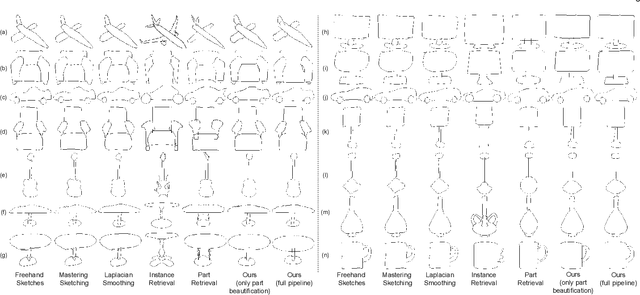
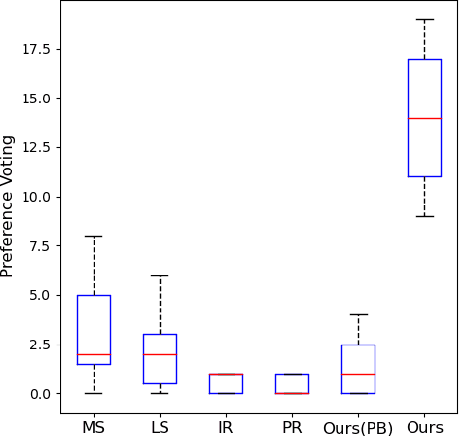
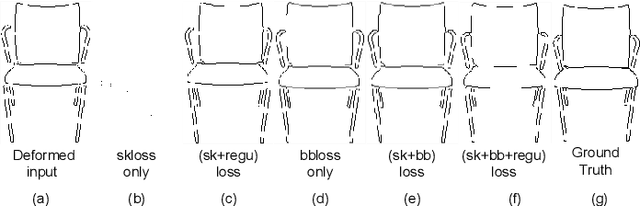
We present a novel freehand sketch beautification method, which takes as input a freely drawn sketch of a man-made object and automatically beautifies it both geometrically and structurally. Beautifying a sketch is challenging because of its highly abstract and heavily diverse drawing manner. Existing methods are usually confined to the distribution of their limited training samples and thus cannot beautify freely drawn sketches with rich variations. To address this challenge, we adopt a divide-and-combine strategy. Specifically, we first parse an input sketch into semantic components, beautify individual components by a learned part beautification module based on part-level implicit manifolds, and then reassemble the beautified components through a structure beautification module. With this strategy, our method can go beyond the training samples and handle novel freehand sketches. We demonstrate the effectiveness of our system with extensive experiments and a perceptive study.
Sketch2Stress: Sketching with Structural Stress Awareness
Jun 09, 2023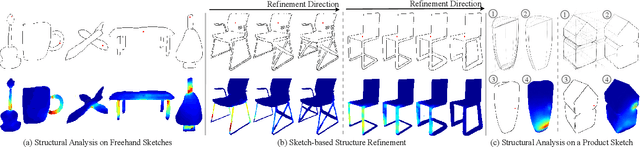
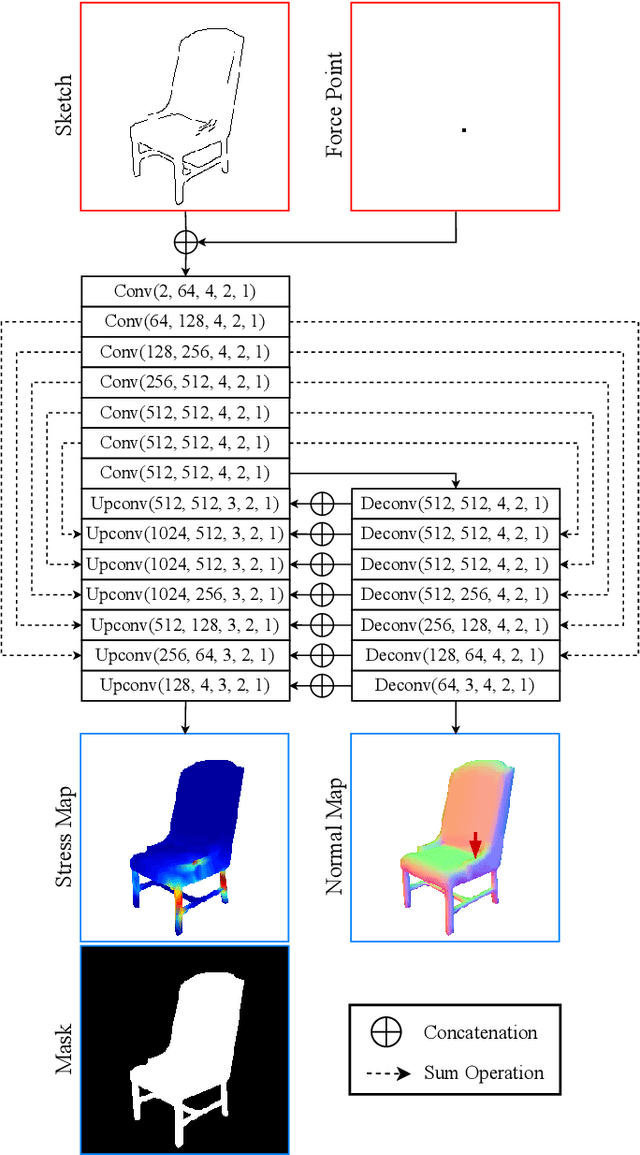


In the process of product design and digital fabrication, the structural analysis of a designed prototype is a fundamental and essential step. However, such a step is usually invisible or inaccessible to designers at the early sketching phase. This limits the user's ability to consider a shape's physical properties and structural soundness. To bridge this gap, we introduce a novel approach Sketch2Stress that allows users to perform structural analysis of desired objects at the sketching stage. This method takes as input a 2D freehand sketch and one or multiple locations of user-assigned external forces. With the specially-designed two-branch generative-adversarial framework, it automatically predicts a normal map and a corresponding structural stress map distributed over the user-sketched underlying object. In this way, our method empowers designers to easily examine the stress sustained everywhere and identify potential problematic regions of their sketched object. Furthermore, combined with the predicted normal map, users are able to conduct a region-wise structural analysis efficiently by aggregating the stress effects of multiple forces in the same direction. Finally, we demonstrate the effectiveness and practicality of our system with extensive experiments and user studies.
SketchHairSalon: Deep Sketch-based Hair Image Synthesis
Sep 21, 2021
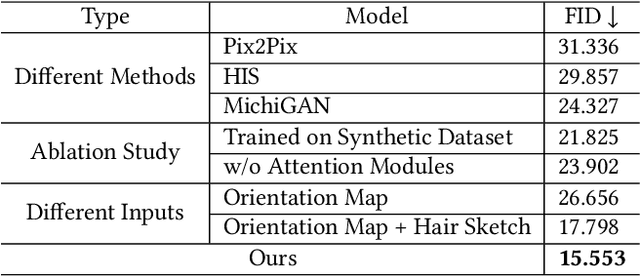
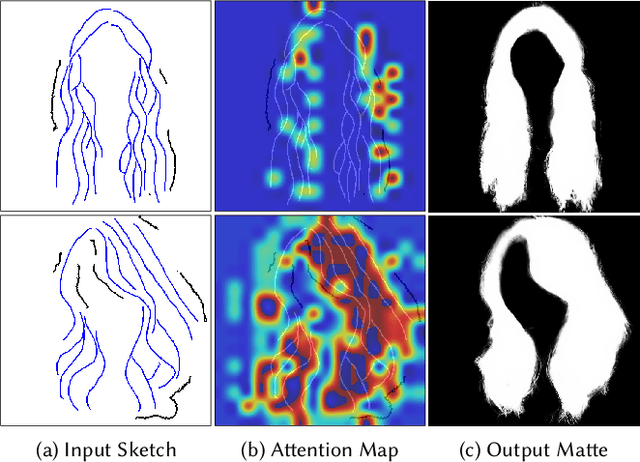
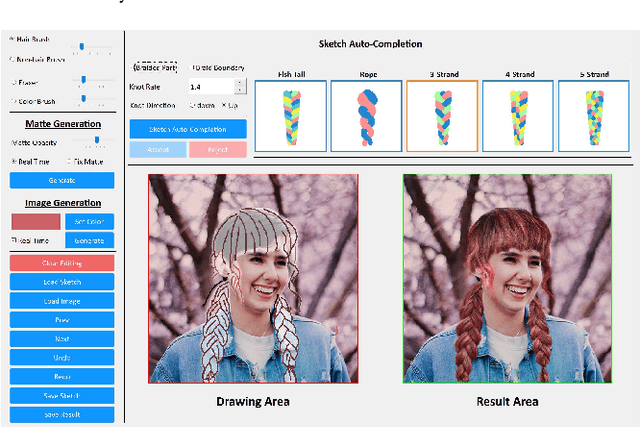
Recent deep generative models allow real-time generation of hair images from sketch inputs. Existing solutions often require a user-provided binary mask to specify a target hair shape. This not only costs users extra labor but also fails to capture complicated hair boundaries. Those solutions usually encode hair structures via orientation maps, which, however, are not very effective to encode complex structures. We observe that colored hair sketches already implicitly define target hair shapes as well as hair appearance and are more flexible to depict hair structures than orientation maps. Based on these observations, we present SketchHairSalon, a two-stage framework for generating realistic hair images directly from freehand sketches depicting desired hair structure and appearance. At the first stage, we train a network to predict a hair matte from an input hair sketch, with an optional set of non-hair strokes. At the second stage, another network is trained to synthesize the structure and appearance of hair images from the input sketch and the generated matte. To make the networks in the two stages aware of long-term dependency of strokes, we apply self-attention modules to them. To train these networks, we present a new dataset containing thousands of annotated hair sketch-image pairs and corresponding hair mattes. Two efficient methods for sketch completion are proposed to automatically complete repetitive braided parts and hair strokes, respectively, thus reducing the workload of users. Based on the trained networks and the two sketch completion strategies, we build an intuitive interface to allow even novice users to design visually pleasing hair images exhibiting various hair structures and appearance via freehand sketches. The qualitative and quantitative evaluations show the advantages of the proposed system over the existing or alternative solutions.
SketchDesc: Learning Local Sketch Descriptors for Multi-view Correspondence
Jan 17, 2020

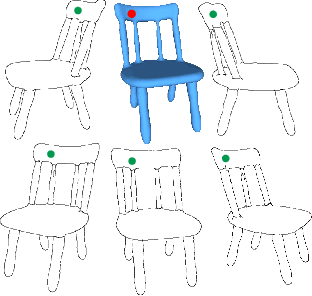
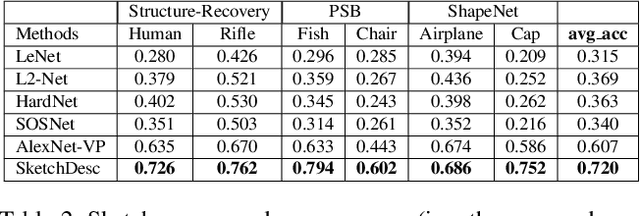
In this paper, we study the problem of multi-view sketch correspondence, where we take as input multiple freehand sketches with different views of the same object and predict semantic correspondence among the sketches. This problem is challenging, since visual features of corresponding points at different views can be very different. To this end, we take a deep learning approach and learn a novel local sketch descriptor from data. We contribute a training dataset by generating the pixel-level correspondence for the multi-view line drawings synthesized from 3D shapes. To handle the sparsity and ambiguity of sketches, we design a novel multi-branch neural network that integrates a patch-based representation and a multi-scale strategy to learn the \pixelLevel correspondence among multi-view sketches. We demonstrate the effectiveness of our proposed approach with extensive experiments on hand-drawn sketches, and multi-view line drawings rendered from multiple 3D shape datasets.