 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchHairSalon: Deep Sketch-based Hair Image Synthesis
Paper and Code

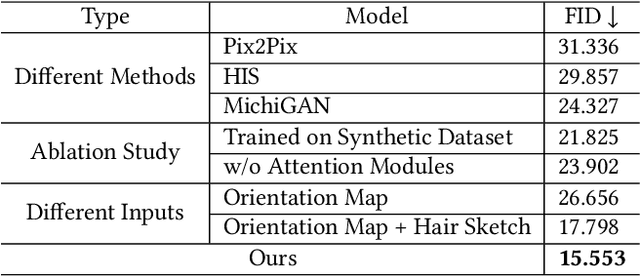
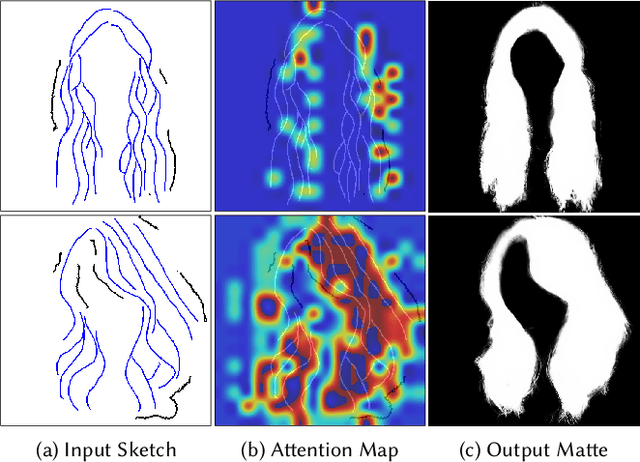
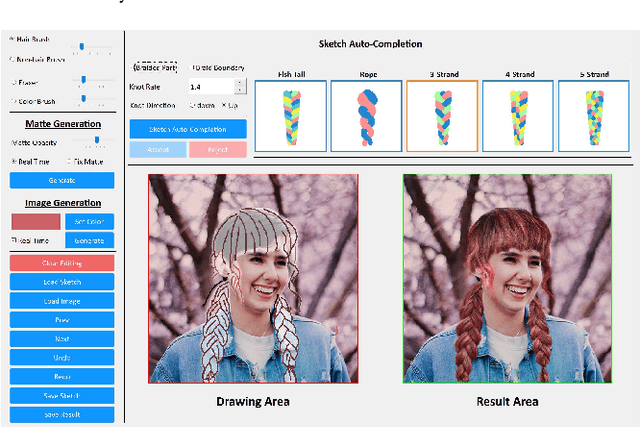
Recent deep generative models allow real-time generation of hair images from sketch inputs. Existing solutions often require a user-provided binary mask to specify a target hair shape. This not only costs users extra labor but also fails to capture complicated hair boundaries. Those solutions usually encode hair structures via orientation maps, which, however, are not very effective to encode complex structures. We observe that colored hair sketches already implicitly define target hair shapes as well as hair appearance and are more flexible to depict hair structures than orientation maps. Based on these observations, we present SketchHairSalon, a two-stage framework for generating realistic hair images directly from freehand sketches depicting desired hair structure and appearance. At the first stage, we train a network to predict a hair matte from an input hair sketch, with an optional set of non-hair strokes. At the second stage, another network is trained to synthesize the structure and appearance of hair images from the input sketch and the generated matte. To make the networks in the two stages aware of long-term dependency of strokes, we apply self-attention modules to them. To train these networks, we present a new dataset containing thousands of annotated hair sketch-image pairs and corresponding hair mattes. Two efficient methods for sketch completion are proposed to automatically complete repetitive braided parts and hair strokes, respectively, thus reducing the workload of users. Based on the trained networks and the two sketch completion strategies, we build an intuitive interface to allow even novice users to design visually pleasing hair images exhibiting various hair structures and appearance via freehand sketches. The qualitative and quantitative evaluations show the advantages of the proposed system over the existing or alternative solutions.