 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossing the Reality Gap in Tactile-Based Learning
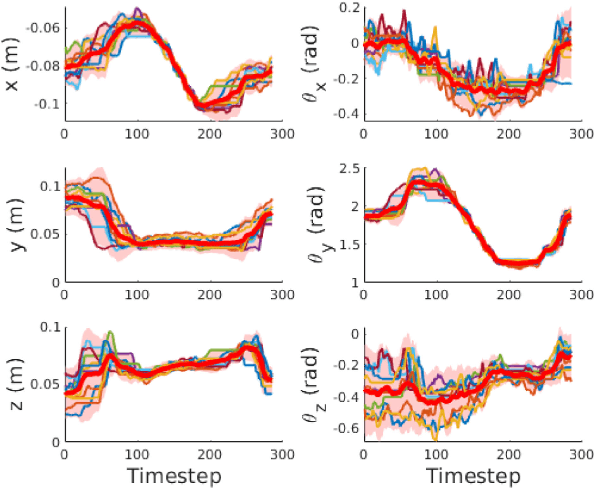
May 23, 2023Tactile sensors are believed to be essential in robotic manipulation, and prior works often rely on experts to reason the sensor feedback and design a controller. With the recent advancement in data-driven approaches, complicated manipulation can be realised, but an accurate and efficient tactile simulation is necessary for policy training. To this end, we present an approach to model a commonly used pressure sensor array in simulation and to train a tactile-based manipulation policy with sim-to-real transfer in mind. Each taxel in our model is represented as a mass-spring-damper system, in which the parameters are iteratively identified as plausible ranges. This allows a policy to be trained with domain randomisation which improves its robustness to different environments. Then, we introduce encoders to further align the critical tactile features in a latent space. Finally, our experiments answer questions on tactile-based manipulation, tactile modelling and sim-to-real performance.
TacGNN:Learning Tactile-based In-hand Manipulation with a Blind Robot
Apr 03, 2023



In this paper, we propose a novel framework for tactile-based dexterous manipulation learning with a blind anthropomorphic robotic hand, i.e. without visual sensing. First, object-related states were extracted from the raw tactile signals by a graph-based perception model - TacGNN. The resulting tactile features were then utilized in the policy learning of an in-hand manipulation task in the second stage. This method was examined by a Baoding ball task - simultaneously manipulating two spheres around each other by 180 degrees in hand. We conducted experiments on object states prediction and in-hand manipulation using a reinforcement learning algorithm (PPO). Results show that TacGNN is effective in predicting object-related states during manipulation by decreasing the RMSE of prediction to 0.096cm comparing to other methods, such as MLP, CNN, and GCN. Finally, the robot hand could finish an in-hand manipulation task solely relying on the robotic own perception - tactile sensing and proprioception. In addition, our methods are tested on three tasks with different difficulty levels and transferred to the real robot without further training.
Egocentric Human Trajectory Forecasting with a Wearable Camera and Multi-Modal Fusion
Nov 04, 2021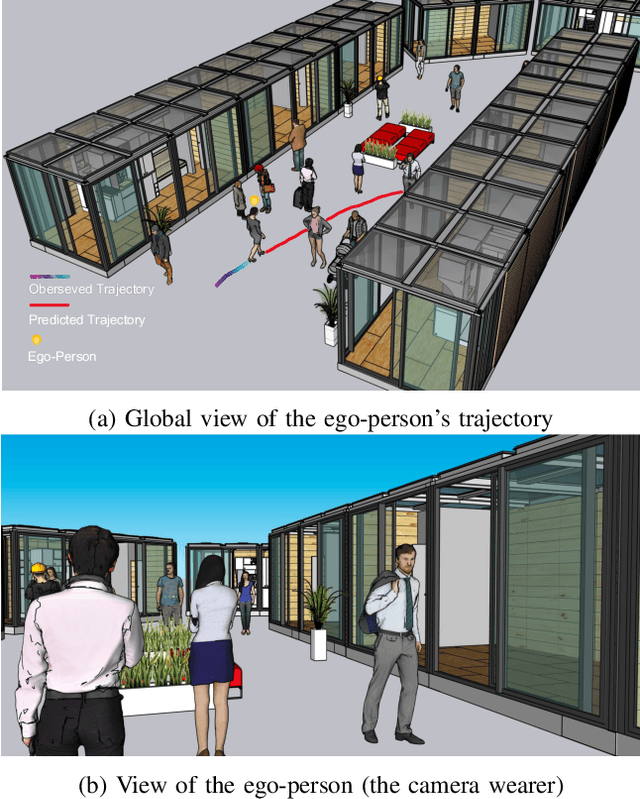

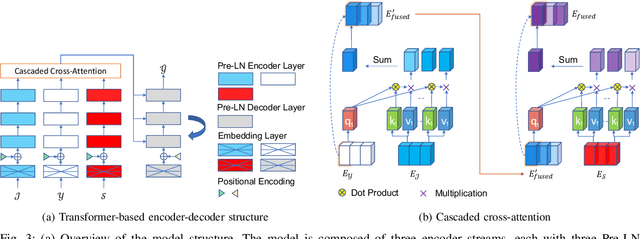

In this paper, we address the problem of forecasting the trajectory of an egocentric camera wearer (ego-person) in crowded spaces. The trajectory forecasting ability learned from the data of different camera wearers walking around in the real world can be transferred to assist visually impaired people in navigation, as well as to instill human navigation behaviours in mobile robots, enabling better human-robot interactions. To this end, a novel egocentric human trajectory forecasting dataset was constructed, containing real trajectories of people navigating in crowded spaces wearing a camera, as well as extracted rich contextual data. We extract and utilize three different modalities to forecast the trajectory of the camera wearer, i.e., his/her past trajectory, the past trajectories of nearby people, and the environment such as the scene semantics or the depth of the scene. A Transformer-based encoder-decoder neural network model, integrated with a novel cascaded cross-attention mechanism that fuses multiple modalities, has been designed to predict the future trajectory of the camera wearer. Extensive experiments have been conducted, and the results have shown that our model outperforms the state-of-the-art methods in egocentric human trajectory forecasting.
Dual-arm Coordinated Manipulation for Object Twisting with Human Intelligence
Aug 26, 2021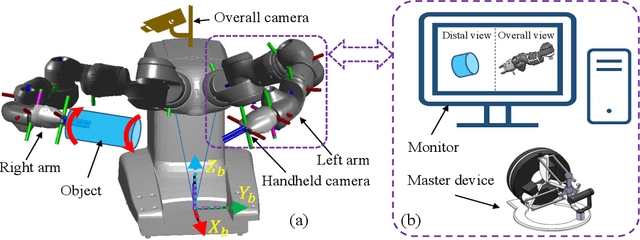

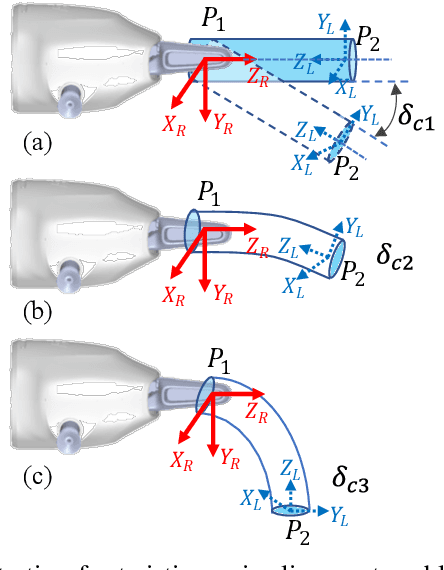
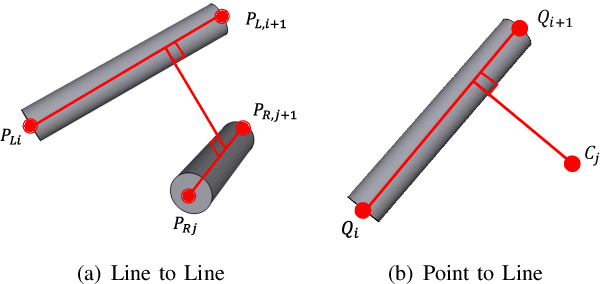
Robotic dual-arm twisting is a common but very challenging task in both industrial production and daily services, as it often requires dexterous collaboration, a large scale of end-effector rotating, and good adaptivity for object manipulation. Meanwhile, safety and efficiency are preliminary concerns for robotic dual-arm coordinated manipulation. Thus, the normally adopted fully automated task execution approaches based on environmental perception and motion planning techniques are still inadequate and problematic for the arduous twisting tasks. To this end, this paper presents a novel strategy of the dual-arm coordinated control for twisting manipulation based on the combination of optimized motion planning for one arm and real-time telecontrol with human intelligence for the other. The analysis and simulation results showed it can achieve collision and singularity free for dual arms with enhanced dexterity, safety, and efficiency.
Sim-to-Real Transfer for Robotic Manipulation with Tactile Sensory
Feb 28, 2021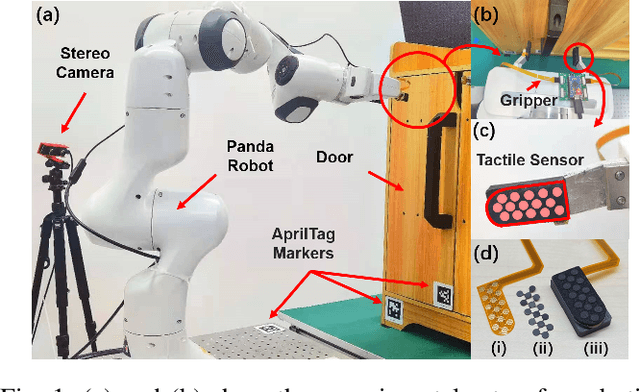
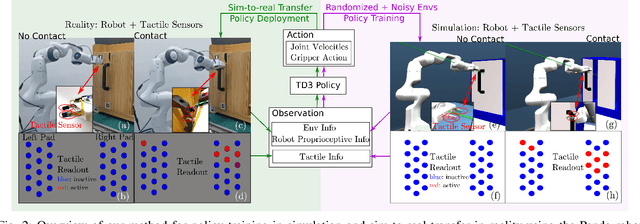
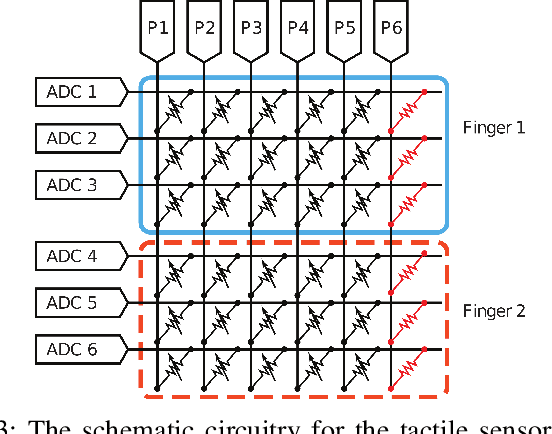
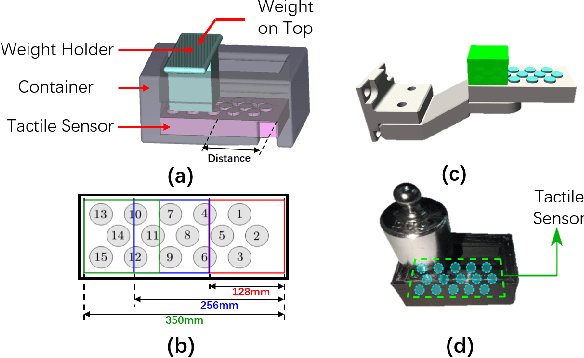
Reinforcement Learning (RL) methods have been widely applied for robotic manipulations via sim-to-real transfer, typically with proprioceptive and visual information. However, the incorporation of tactile sensing into RL for contact-rich tasks lacks investigation. In this paper, we model a tactile sensor in simulation and study the effects of its feedback in RL-based robotic control via a zero-shot sim-to-real approach with domain randomization. We demonstrate that learning and controlling with feedback from tactile sensor arrays at the gripper, both in simulation and reality, can enhance grasping stability, which leads to a significant improvement in robotic manipulation performance for a door opening task. In real-world experiments, the door open angle was increased by 45% on average for transferred policies with tactile sensing over those without it.
DROID: Minimizing the Reality Gap using Single-Shot Human Demonstration
Feb 23, 2021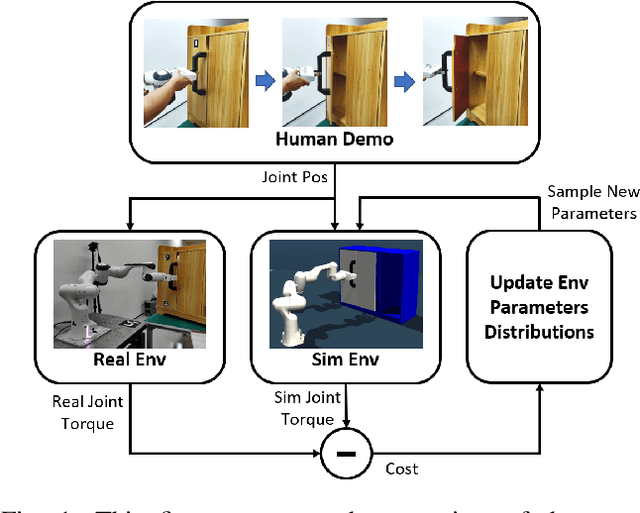



Reinforcement learning (RL) has demonstrated great success in the past several years. However, most of the scenarios focus on simulated environments. One of the main challenges of transferring the policy learned in a simulated environment to real world, is the discrepancy between the dynamics of the two environments. In prior works, Domain Randomization (DR) has been used to address the reality gap for both robotic locomotion and manipulation tasks. In this paper, we propose Domain Randomization Optimization IDentification (DROID), a novel framework to exploit single-shot human demonstration for identifying the simulator's distribution of dynamics parameters, and apply it to training a policy on a door opening task. Our results show that the proposed framework can identify the difference in dynamics between the simulated and the real worlds, and thus improve policy transfer by optimizing the simulator's randomization ranges. We further illustrate that based on these same identified parameters, our method can generalize the learned policy to different but related tasks.
Constrained-Space Optimization and Reinforcement Learning for Complex Tasks
Apr 01, 2020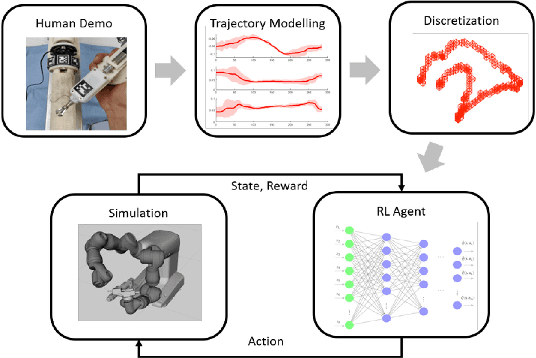

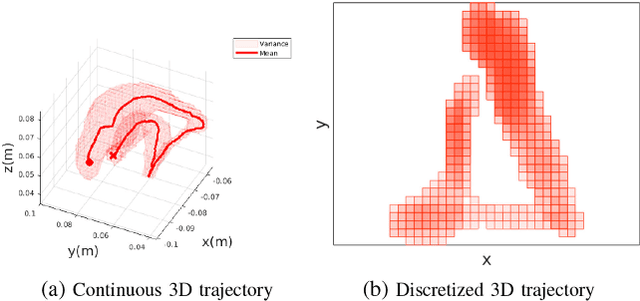
Learning from Demonstration is increasingly used for transferring operator manipulation skills to robots. In practice, it is important to cater for limited data and imperfect human demonstrations, as well as underlying safety constraints. This paper presents a constrained-space optimization and reinforcement learning scheme for managing complex tasks. Through interactions within the constrained space, the reinforcement learning agent is trained to optimize the manipulation skills according to a defined reward function. After learning, the optimal policy is derived from the well-trained reinforcement learning agent, which is then implemented to guide the robot to conduct tasks that are similar to the experts' demonstrations. The effectiveness of the proposed method is verified with a robotic suturing task, demonstrating that the learned policy outperformed the experts' demonstrations in terms of the smoothness of the joint motion and end-effector trajectories, as well as the overall task completion time.
* Accepted for publication in RA-Letters and at ICRA 2020