 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgocentric Human Trajectory Forecasting with a Wearable Camera and Multi-Modal Fusion
Paper and Code
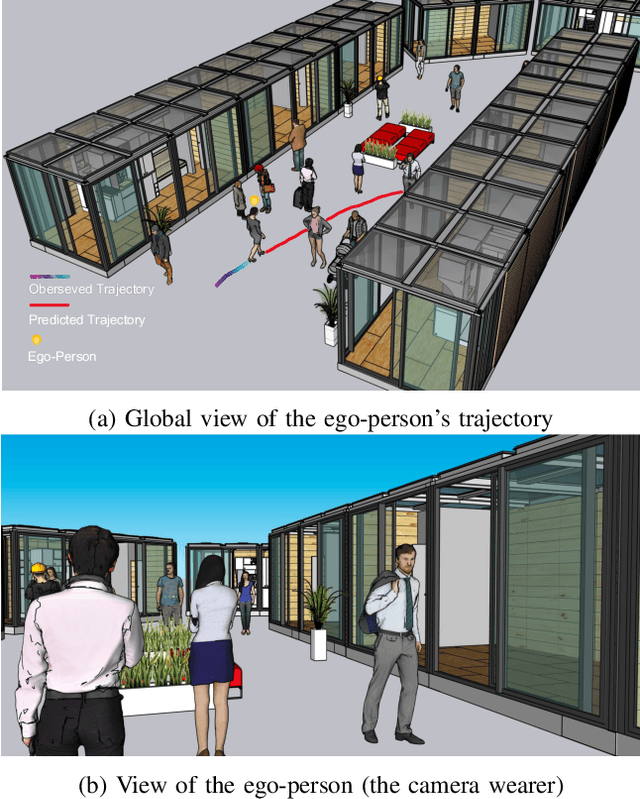

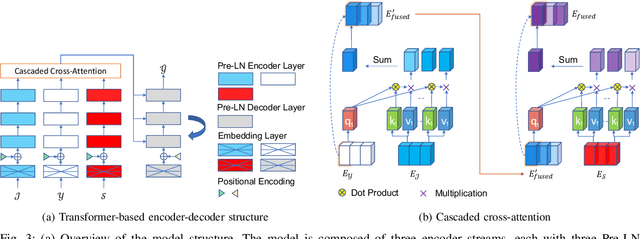

In this paper, we address the problem of forecasting the trajectory of an egocentric camera wearer (ego-person) in crowded spaces. The trajectory forecasting ability learned from the data of different camera wearers walking around in the real world can be transferred to assist visually impaired people in navigation, as well as to instill human navigation behaviours in mobile robots, enabling better human-robot interactions. To this end, a novel egocentric human trajectory forecasting dataset was constructed, containing real trajectories of people navigating in crowded spaces wearing a camera, as well as extracted rich contextual data. We extract and utilize three different modalities to forecast the trajectory of the camera wearer, i.e., his/her past trajectory, the past trajectories of nearby people, and the environment such as the scene semantics or the depth of the scene. A Transformer-based encoder-decoder neural network model, integrated with a novel cascaded cross-attention mechanism that fuses multiple modalities, has been designed to predict the future trajectory of the camera wearer. Extensive experiments have been conducted, and the results have shown that our model outperforms the state-of-the-art methods in egocentric human trajectory forecasting.