 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-arm Coordinated Manipulation for Object Twisting with Human Intelligence
Aug 26, 2021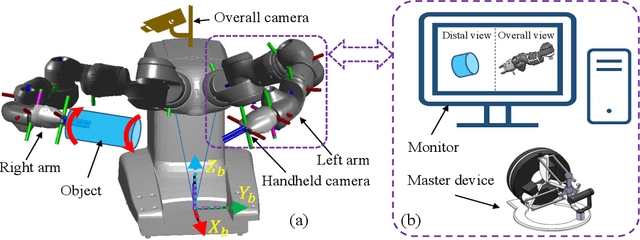

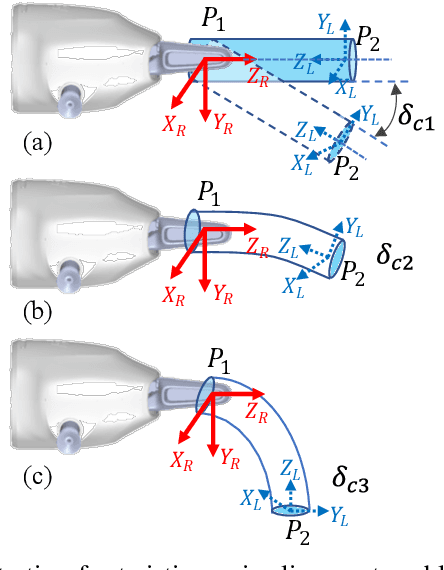
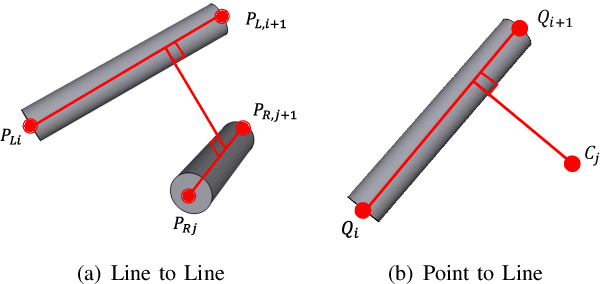
Robotic dual-arm twisting is a common but very challenging task in both industrial production and daily services, as it often requires dexterous collaboration, a large scale of end-effector rotating, and good adaptivity for object manipulation. Meanwhile, safety and efficiency are preliminary concerns for robotic dual-arm coordinated manipulation. Thus, the normally adopted fully automated task execution approaches based on environmental perception and motion planning techniques are still inadequate and problematic for the arduous twisting tasks. To this end, this paper presents a novel strategy of the dual-arm coordinated control for twisting manipulation based on the combination of optimized motion planning for one arm and real-time telecontrol with human intelligence for the other. The analysis and simulation results showed it can achieve collision and singularity free for dual arms with enhanced dexterity, safety, and efficiency.
Multiple-Source Adaptation with Domain Classifiers
Aug 25, 2020
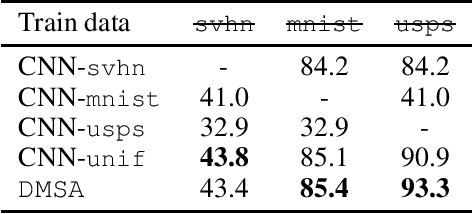

We consider the multiple-source adaptation (MSA) problem and improve a previously proposed MSA solution, where accurate density estimation per domain is required to obtain favorable learning guarantees. In this work, we replace the difficult task of density estimation per domain with a much easier task of domain classification, and show that the two solutions are equivalent given the true densities and domain classifier, yet the newer approach benefits from more favorable guarantees when densities and domain classifier are estimated from finite samples. Our experiments with real-world applications demonstrate that the new discriminative MSA solution outperforms the previous solution with density estimation, as well as other domain adaptation baselines.
Adaptive Region-Based Active Learning
Feb 18, 2020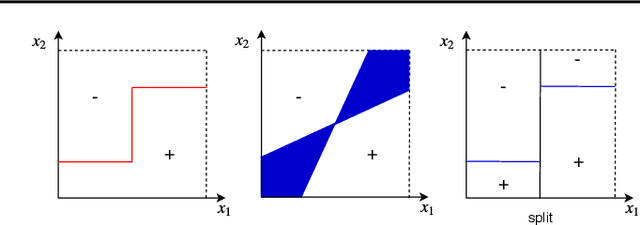
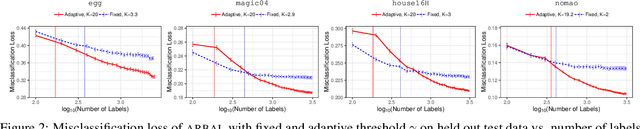
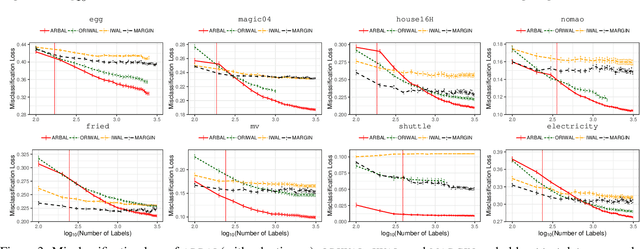
We present a new active learning algorithm that adaptively partitions the input space into a finite number of regions, and subsequently seeks a distinct predictor for each region, both phases actively requesting labels. We prove theoretical guarantees for both the generalization error and the label complexity of our algorithm, and analyze the number of regions defined by the algorithm under some mild assumptions. We also report the results of an extensive suite of experiments on several real-world datasets demonstrating substantial empirical benefits over existing single-region and non-adaptive region-based active learning baselines.
Learning GANs and Ensembles Using Discrepancy
Nov 06, 2019
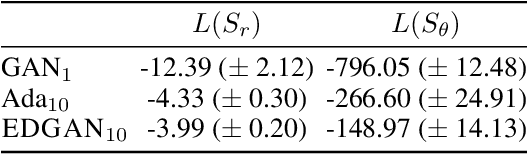

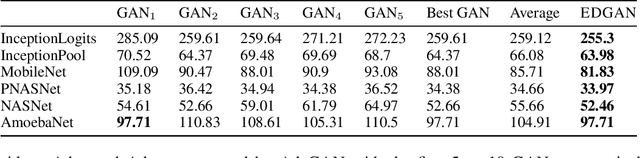
Generative adversarial networks (GANs) generate data based on minimizing a divergence between two distributions. The choice of that divergence is therefore critical. We argue that the divergence must take into account the hypothesis set and the loss function used in a subsequent learning task, where the data generated by a GAN serves for training. Taking that structural information into account is also important to derive generalization guarantees. Thus, we propose to use the discrepancy measure, which was originally introduced for the closely related problem of domain adaptation and which precisely takes into account the hypothesis set and the loss function. We show that discrepancy admits favorable properties for training GANs and prove explicit generalization guarantees. We present efficient algorithms using discrepancy for two tasks: training a GAN directly, namely DGAN, and mixing previously trained generative models, namely EDGAN. Our experiments on toy examples and several benchmark datasets show that DGAN is competitive with other GANs and that EDGAN outperforms existing GAN ensembles, such as AdaGAN.
Fitting a deeply-nested hierarchical model to a large book review dataset using a moment-based estimator
Jun 01, 2018

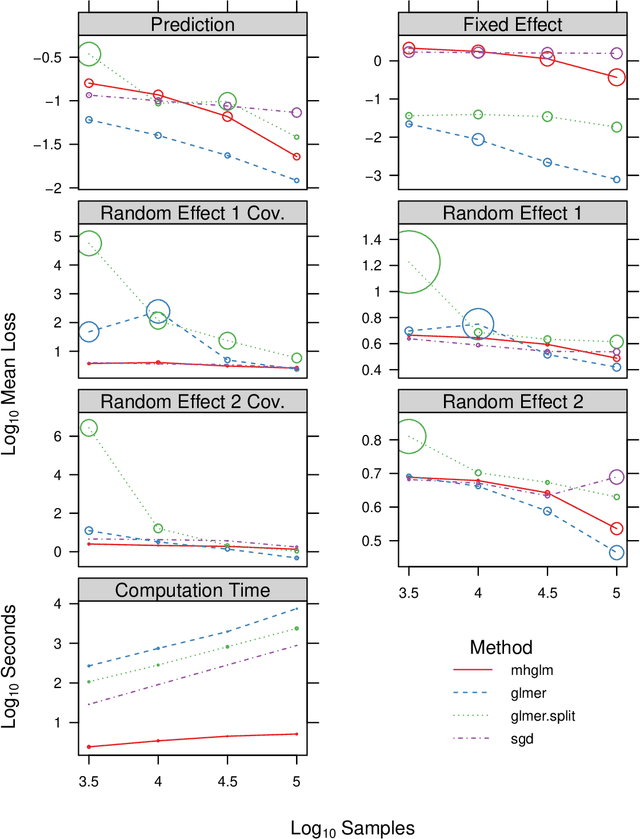
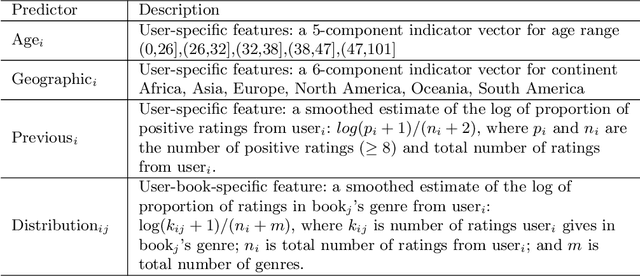
We consider a particular instance of a common problem in recommender systems: using a database of book reviews to inform user-targeted recommendations. In our dataset, books are categorized into genres and sub-genres. To exploit this nested taxonomy, we use a hierarchical model that enables information pooling across across similar items at many levels within the genre hierarchy. The main challenge in deploying this model is computational: the data sizes are large, and fitting the model at scale using off-the-shelf maximum likelihood procedures is prohibitive. To get around this computational bottleneck, we extend a moment-based fitting procedure proposed for fitting single-level hierarchical models to the general case of arbitrarily deep hierarchies. This extension is an order of magnetite faster than standard maximum likelihood procedures. The fitting method can be deployed beyond recommender systems to general contexts with deeply-nested hierarchical generalized linear mixed models.
Algorithms and Theory for Multiple-Source Adaptation
May 20, 2018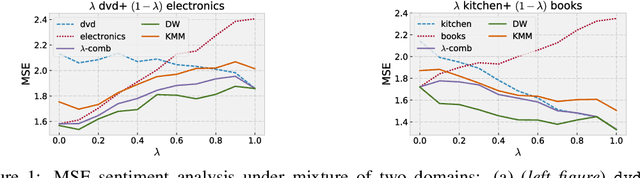

This work includes a number of novel contributions for the multiple-source adaptation problem. We present new normalized solutions with strong theoretical guarantees for the cross-entropy loss and other similar losses. We also provide new guarantees that hold in the case where the conditional probabilities for the source domains are distinct. Moreover, we give new algorithms for determining the distribution-weighted combination solution for the cross-entropy loss and other losses. We report the results of a series of experiments with real-world datasets. We find that our algorithm outperforms competing approaches by producing a single robust model that performs well on any target mixture distribution. Altogether, our theory, algorithms, and empirical results provide a full solution for the multiple-source adaptation problem with very practical benefits.
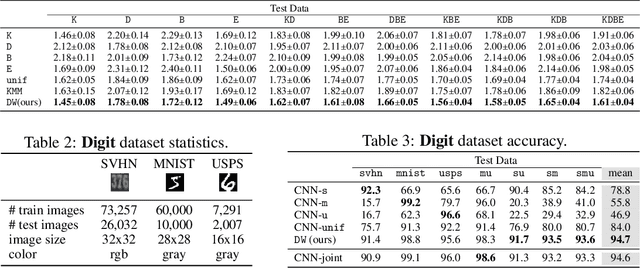
Multiple-Source Adaptation for Regression Problems
Nov 14, 2017

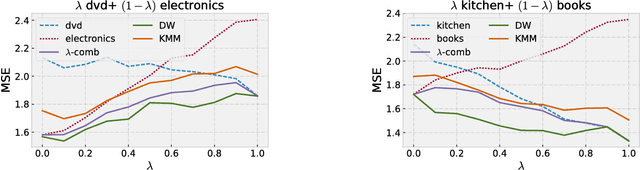
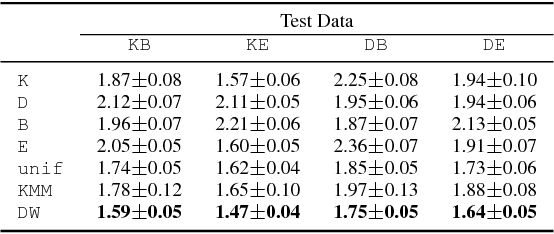
We present a detailed theoretical analysis of the problem of multiple-source adaptation in the general stochastic scenario, extending known results that assume a single target labeling function. Our results cover a more realistic scenario and show the existence of a single robust predictor accurate for \emph{any} target mixture of the source distributions. Moreover, we present an efficient and practical optimization solution to determine the robust predictor in the important case of squared loss, by casting the problem as an instance of DC-programming. We report the results of experiments with both an artificial task and a sentiment analysis task. We find that our algorithm outperforms competing approaches by producing a single robust model that performs well on any target mixture distribution.