 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadarSim: Simulating Single-Chip Radar via Multimodal Neural Fields
May 25, 2026Radars are an ideal complement to cameras: both are inexpensive, solid-state sensors, with cameras offering fine angular resolution, while radars provide metric depth and robustness under adverse weather. However, radar data is more difficult to interpret than camera images and varies significantly between sensors, necessitating increased reliance on simulation for prototyping sensors and processing pipelines. Recent work treating radar reconstruction as a novel view synthesis problem has shown great promise in reconstructing radar-relevant geometry and simulating low-level radar data. However, such methods are constrained by the low spatial resolution of the underlying radar. To address this, we propose a unified differentiable renderer, RadarSim, which leverages the high angular resolution of RGB cameras to generate Doppler radar range images from a camera-initialized neural field. Using a novel data set of calibrated radar camera recordings from a custom hand-held rig, we demonstrate that RadarSim produces sharper geometry and Doppler range frames than radar-only reconstructions.
Towards Foundational Models for Single-Chip Radar
Sep 15, 2025mmWave radars are compact, inexpensive, and durable sensors that are robust to occlusions and work regardless of environmental conditions, such as weather and darkness. However, this comes at the cost of poor angular resolution, especially for inexpensive single-chip radars, which are typically used in automotive and indoor sensing applications. Although many have proposed learning-based methods to mitigate this weakness, no standardized foundational models or large datasets for the mmWave radar have emerged, and practitioners have largely trained task-specific models from scratch using relatively small datasets. In this paper, we collect (to our knowledge) the largest available raw radar dataset with 1M samples (29 hours) and train a foundational model for 4D single-chip radar, which can predict 3D occupancy and semantic segmentation with quality that is typically only possible with much higher resolution sensors. We demonstrate that our Generalizable Radar Transformer (GRT) generalizes across diverse settings, can be fine-tuned for different tasks, and shows logarithmic data scaling of 20\% per $10\times$ data. We also run extensive ablations on common design decisions, and find that using raw radar data significantly outperforms widely-used lossy representations, equivalent to a $10\times$ increase in training data. Finally, we roughly estimate that $\approx$100M samples (3000 hours) of data are required to fully exploit the potential of GRT.
Neural Inverse Rendering from Propagating Light
Jun 05, 2025We present the first system for physically based, neural inverse rendering from multi-viewpoint videos of propagating light. Our approach relies on a time-resolved extension of neural radiance caching -- a technique that accelerates inverse rendering by storing infinite-bounce radiance arriving at any point from any direction. The resulting model accurately accounts for direct and indirect light transport effects and, when applied to captured measurements from a flash lidar system, enables state-of-the-art 3D reconstruction in the presence of strong indirect light. Further, we demonstrate view synthesis of propagating light, automatic decomposition of captured measurements into direct and indirect components, as well as novel capabilities such as multi-view time-resolved relighting of captured scenes.
Time of the Flight of the Gaussians: Optimizing Depth Indirectly in Dynamic Radiance Fields
May 08, 2025We present a method to reconstruct dynamic scenes from monocular continuous-wave time-of-flight (C-ToF) cameras using raw sensor samples that achieves similar or better accuracy than neural volumetric approaches and is 100x faster. Quickly achieving high-fidelity dynamic 3D reconstruction from a single viewpoint is a significant challenge in computer vision. In C-ToF radiance field reconstruction, the property of interest-depth-is not directly measured, causing an additional challenge. This problem has a large and underappreciated impact upon the optimization when using a fast primitive-based scene representation like 3D Gaussian splatting, which is commonly used with multi-view data to produce satisfactory results and is brittle in its optimization otherwise. We incorporate two heuristics into the optimization to improve the accuracy of scene geometry represented by Gaussians. Experimental results show that our approach produces accurate reconstructions under constrained C-ToF sensing conditions, including for fast motions like swinging baseball bats. https://visual.cs.brown.edu/gftorf
Flash Cache: Reducing Bias in Radiance Cache Based Inverse Rendering
Sep 09, 2024State-of-the-art techniques for 3D reconstruction are largely based on volumetric scene representations, which require sampling multiple points to compute the color arriving along a ray. Using these representations for more general inverse rendering -- reconstructing geometry, materials, and lighting from observed images -- is challenging because recursively path-tracing such volumetric representations is expensive. Recent works alleviate this issue through the use of radiance caches: data structures that store the steady-state, infinite-bounce radiance arriving at any point from any direction. However, these solutions rely on approximations that introduce bias into the renderings and, more importantly, into the gradients used for optimization. We present a method that avoids these approximations while remaining computationally efficient. In particular, we leverage two techniques to reduce variance for unbiased estimators of the rendering equation: (1) an occlusion-aware importance sampler for incoming illumination and (2) a fast cache architecture that can be used as a control variate for the radiance from a high-quality, but more expensive, volumetric cache. We show that by removing these biases our approach improves the generality of radiance cache based inverse rendering, as well as increasing quality in the presence of challenging light transport effects such as specular reflections.
Implicit Neural Head Synthesis via Controllable Local Deformation Fields
Apr 21, 2023High-quality reconstruction of controllable 3D head avatars from 2D videos is highly desirable for virtual human applications in movies, games, and telepresence. Neural implicit fields provide a powerful representation to model 3D head avatars with personalized shape, expressions, and facial parts, e.g., hair and mouth interior, that go beyond the linear 3D morphable model (3DMM). However, existing methods do not model faces with fine-scale facial features, or local control of facial parts that extrapolate asymmetric expressions from monocular videos. Further, most condition only on 3DMM parameters with poor(er) locality, and resolve local features with a global neural field. We build on part-based implicit shape models that decompose a global deformation field into local ones. Our novel formulation models multiple implicit deformation fields with local semantic rig-like control via 3DMM-based parameters, and representative facial landmarks. Further, we propose a local control loss and attention mask mechanism that promote sparsity of each learned deformation field. Our formulation renders sharper locally controllable nonlinear deformations than previous implicit monocular approaches, especially mouth interior, asymmetric expressions, and facial details.
HyperReel: High-Fidelity 6-DoF Video with Ray-Conditioned Sampling
Jan 05, 2023Volumetric scene representations enable photorealistic view synthesis for static scenes and form the basis of several existing 6-DoF video techniques. However, the volume rendering procedures that drive these representations necessitate careful trade-offs in terms of quality, rendering speed, and memory efficiency. In particular, existing methods fail to simultaneously achieve real-time performance, small memory footprint, and high-quality rendering for challenging real-world scenes. To address these issues, we present HyperReel -- a novel 6-DoF video representation. The two core components of HyperReel are: (1) a ray-conditioned sample prediction network that enables high-fidelity, high frame rate rendering at high resolutions and (2) a compact and memory efficient dynamic volume representation. Our 6-DoF video pipeline achieves the best performance compared to prior and contemporary approaches in terms of visual quality with small memory requirements, while also rendering at up to 18 frames-per-second at megapixel resolution without any custom CUDA code.
Time-multiplexed Neural Holography: A flexible framework for holographic near-eye displays with fast heavily-quantized spatial light modulators
May 05, 2022
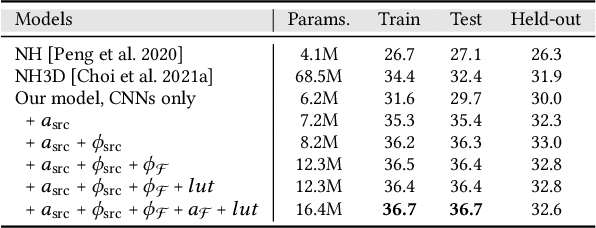
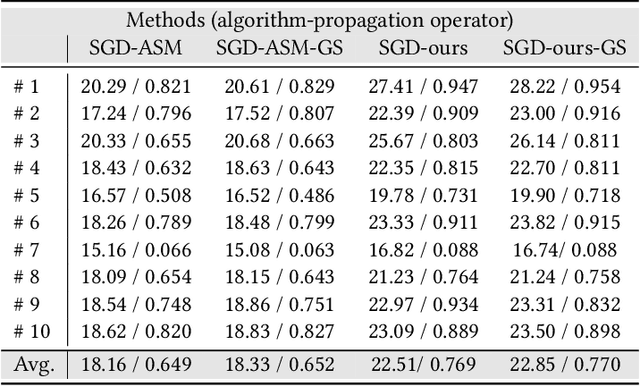

Holographic near-eye displays offer unprecedented capabilities for virtual and augmented reality systems, including perceptually important focus cues. Although artificial intelligence--driven algorithms for computer-generated holography (CGH) have recently made much progress in improving the image quality and synthesis efficiency of holograms, these algorithms are not directly applicable to emerging phase-only spatial light modulators (SLM) that are extremely fast but offer phase control with very limited precision. The speed of these SLMs offers time multiplexing capabilities, essentially enabling partially-coherent holographic display modes. Here we report advances in camera-calibrated wave propagation models for these types of holographic near-eye displays and we develop a CGH framework that robustly optimizes the heavily quantized phase patterns of fast SLMs. Our framework is flexible in supporting runtime supervision with different types of content, including 2D and 2.5D RGBD images, 3D focal stacks, and 4D light fields. Using our framework, we demonstrate state-of-the-art results for all of these scenarios in simulation and experiment.
Enhancing Speckle Statistics for Imaging inside Scattering Media
Mar 27, 2022

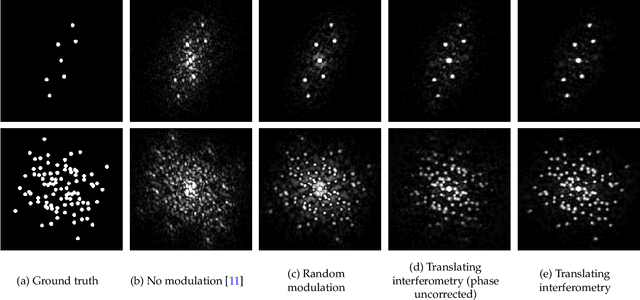
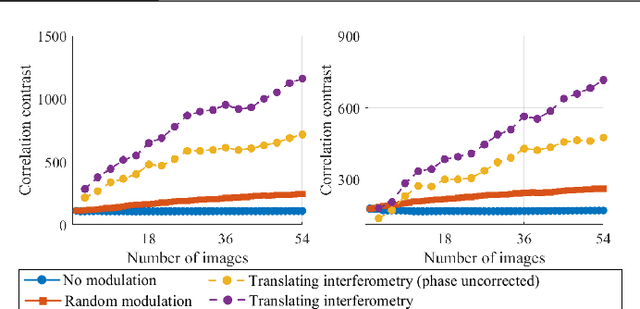
We exploit memory effect speckle correlations for the imaging of incoherent linear (single-photon) fluorescent sources behind scattering tissue. While memory effect-based imaging techniques have been heavily studied in the past, for thick scattering layers and complex illumination patterns these correlations are weak, limiting the practice applicability of the idea. In this work, we introduce a Spatial Light Modulator (SLM) between the tissue sample and the imaging sensor and capture multiple modulations of the speckle pattern. We show that by correctly designing the modulation pattern and the reconstruction algorithm we can greatly enhance statistical correlations in the data. We exploit this to demonstrate the reconstruction of mega-pixel wide fluorescent patterns behind scattering tissue.
TöRF: Time-of-Flight Radiance Fields for Dynamic Scene View Synthesis
Sep 30, 2021
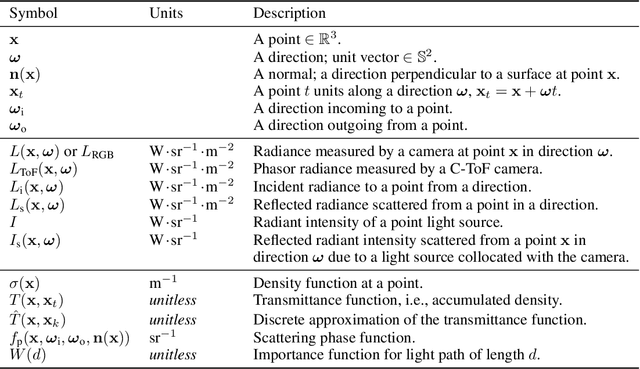
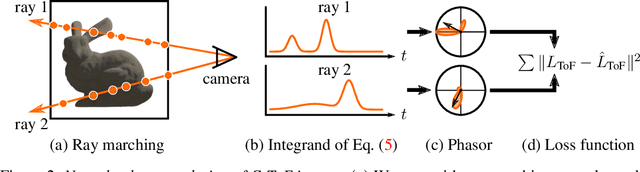
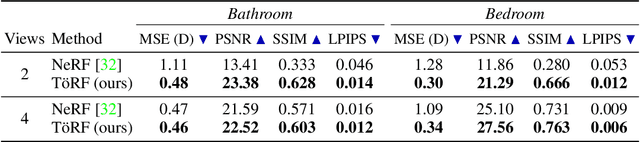
Neural networks can represent and accurately reconstruct radiance fields for static 3D scenes (e.g., NeRF). Several works extend these to dynamic scenes captured with monocular video, with promising performance. However, the monocular setting is known to be an under-constrained problem, and so methods rely on data-driven priors for reconstructing dynamic content. We replace these priors with measurements from a time-of-flight (ToF) camera, and introduce a neural representation based on an image formation model for continuous-wave ToF cameras. Instead of working with processed depth maps, we model the raw ToF sensor measurements to improve reconstruction quality and avoid issues with low reflectance regions, multi-path interference, and a sensor's limited unambiguous depth range. We show that this approach improves robustness of dynamic scene reconstruction to erroneous calibration and large motions, and discuss the benefits and limitations of integrating RGB+ToF sensors that are now available on modern smartphones.