 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAWN: Domain-Adaptive Weakly Supervised Nuclei Segmentation via Cross-Task Interactions
Apr 24, 2024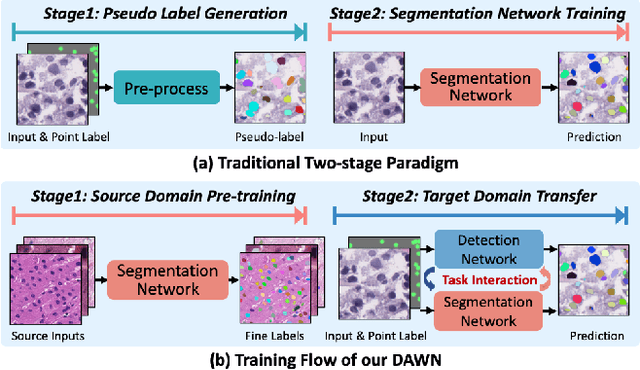
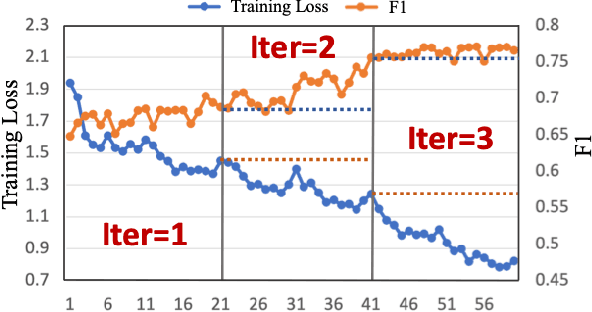

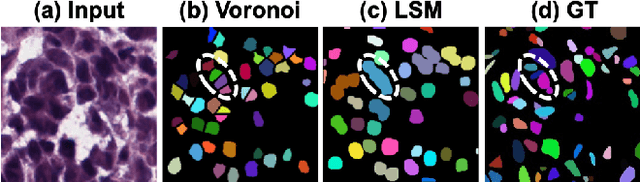
Weakly supervised segmentation methods have gained significant attention due to their ability to reduce the reliance on costly pixel-level annotations during model training. However, the current weakly supervised nuclei segmentation approaches typically follow a two-stage pseudo-label generation and network training process. The performance of the nuclei segmentation heavily relies on the quality of the generated pseudo-labels, thereby limiting its effectiveness. This paper introduces a novel domain-adaptive weakly supervised nuclei segmentation framework using cross-task interaction strategies to overcome the challenge of pseudo-label generation. Specifically, we utilize weakly annotated data to train an auxiliary detection task, which assists the domain adaptation of the segmentation network. To enhance the efficiency of domain adaptation, we design a consistent feature constraint module integrating prior knowledge from the source domain. Furthermore, we develop pseudo-label optimization and interactive training methods to improve the domain transfer capability. To validate the effectiveness of our proposed method, we conduct extensive comparative and ablation experiments on six datasets. The results demonstrate the superiority of our approach over existing weakly supervised approaches. Remarkably, our method achieves comparable or even better performance than fully supervised methods. Our code will be released in https://github.com/zhangye-zoe/DAWN.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024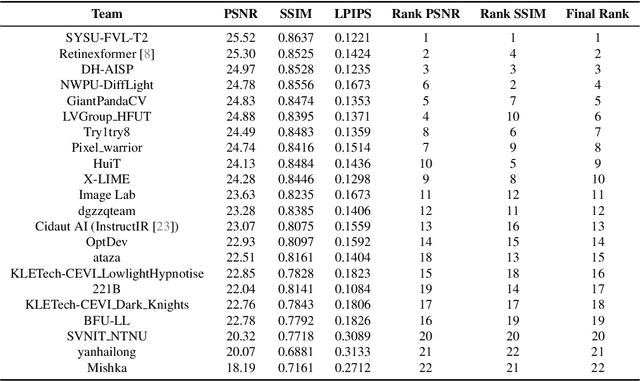

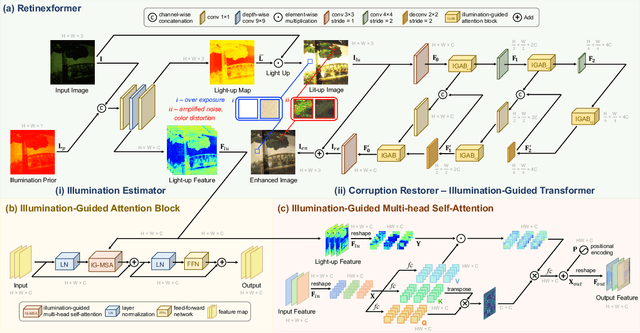

This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Boundary-aware Contrastive Learning for Semi-supervised Nuclei Instance Segmentation
Feb 07, 2024Semi-supervised segmentation methods have demonstrated promising results in natural scenarios, providing a solution to reduce dependency on manual annotation. However, these methods face significant challenges when directly applied to pathological images due to the subtle color differences between nuclei and tissues, as well as the significant morphological variations among nuclei. Consequently, the generated pseudo-labels often contain much noise, especially at the nuclei boundaries. To address the above problem, this paper proposes a boundary-aware contrastive learning network to denoise the boundary noise in a semi-supervised nuclei segmentation task. The model has two key designs: a low-resolution denoising (LRD) module and a cross-RoI contrastive learning (CRC) module. The LRD improves the smoothness of the nuclei boundary by pseudo-labels denoising, and the CRC enhances the discrimination between foreground and background by boundary feature contrastive learning. We conduct extensive experiments to demonstrate the superiority of our proposed method over existing semi-supervised instance segmentation methods.
HVTSurv: Hierarchical Vision Transformer for Patient-Level Survival Prediction from Whole Slide Image
Jun 30, 2023
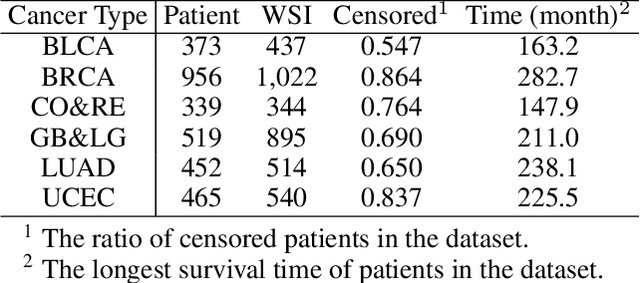
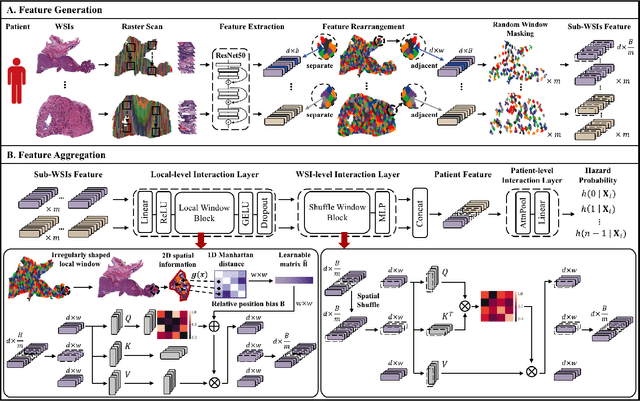
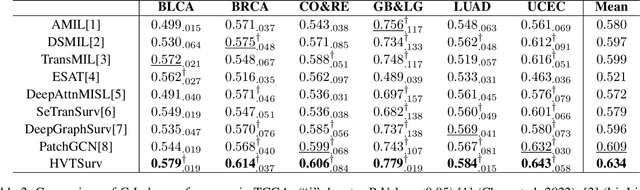
Survival prediction based on whole slide images (WSIs) is a challenging task for patient-level multiple instance learning (MIL). Due to the vast amount of data for a patient (one or multiple gigapixels WSIs) and the irregularly shaped property of WSI, it is difficult to fully explore spatial, contextual, and hierarchical interaction in the patient-level bag. Many studies adopt random sampling pre-processing strategy and WSI-level aggregation models, which inevitably lose critical prognostic information in the patient-level bag. In this work, we propose a hierarchical vision Transformer framework named HVTSurv, which can encode the local-level relative spatial information, strengthen WSI-level context-aware communication, and establish patient-level hierarchical interaction. Firstly, we design a feature pre-processing strategy, including feature rearrangement and random window masking. Then, we devise three layers to progressively obtain patient-level representation, including a local-level interaction layer adopting Manhattan distance, a WSI-level interaction layer employing spatial shuffle, and a patient-level interaction layer using attention pooling. Moreover, the design of hierarchical network helps the model become more computationally efficient. Finally, we validate HVTSurv with 3,104 patients and 3,752 WSIs across 6 cancer types from The Cancer Genome Atlas (TCGA). The average C-Index is 2.50-11.30% higher than all the prior weakly supervised methods over 6 TCGA datasets. Ablation study and attention visualization further verify the superiority of the proposed HVTSurv. Implementation is available at: https://github.com/szc19990412/HVTSurv.
Retinexformer: One-stage Retinex-based Transformer for Low-light Image Enhancement
Mar 12, 2023When enhancing low-light images, many deep learning algorithms are based on the Retinex theory. However, the Retinex model does not consider the corruptions hidden in the dark or introduced by the light-up process. Besides, these methods usually require a tedious multi-stage training pipeline and rely on convolutional neural networks, showing limitations in capturing long-range dependencies. In this paper, we formulate a simple yet principled One-stage Retinex-based Framework (ORF). ORF first estimates the illumination information to light up the low-light image and then restores the corruption to produce the enhanced image. We design an Illumination-Guided Transformer (IGT) that utilizes illumination representations to direct the modeling of non-local interactions of regions with different lighting conditions. By plugging IGT into ORF, we obtain our algorithm, Retinexformer. Comprehensive quantitative and qualitative experiments demonstrate that our Retinexformer significantly outperforms state-of-the-art methods on seven benchmarks. The user study and application on low-light object detection also reveal the latent practical values of our method. Codes and pre-trained models will be released.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Multiple Instance Learning with Mixed Supervision in Gleason Grading
Jun 26, 2022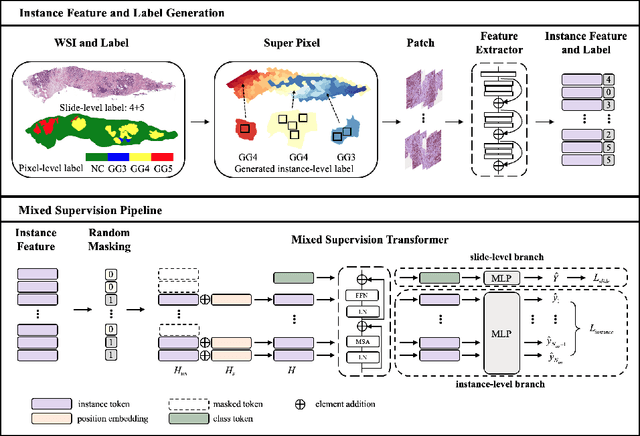
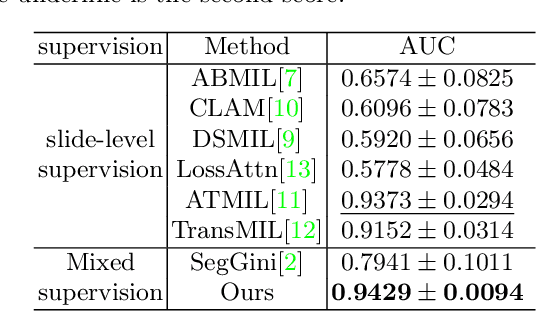

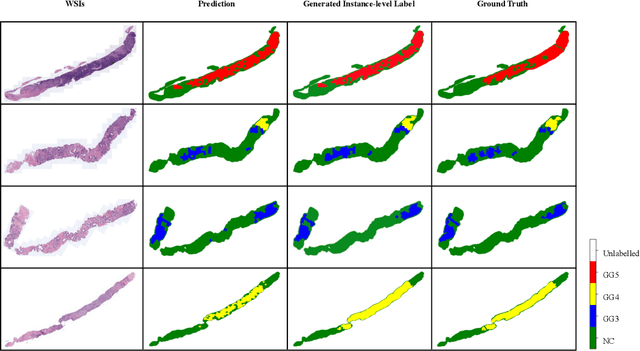
With the development of computational pathology, deep learning methods for Gleason grading through whole slide images (WSIs) have excellent prospects. Since the size of WSIs is extremely large, the image label usually contains only slide-level label or limited pixel-level labels. The current mainstream approach adopts multi-instance learning to predict Gleason grades. However, some methods only considering the slide-level label ignore the limited pixel-level labels containing rich local information. Furthermore, the method of additionally considering the pixel-level labels ignores the inaccuracy of pixel-level labels. To address these problems, we propose a mixed supervision Transformer based on the multiple instance learning framework. The model utilizes both slide-level label and instance-level labels to achieve more accurate Gleason grading at the slide level. The impact of inaccurate instance-level labels is further reduced by introducing an efficient random masking strategy in the mixed supervision training process. We achieve the state-of-the-art performance on the SICAPv2 dataset, and the visual analysis shows the accurate prediction results of instance level. The source code is available at https://github.com/bianhao123/Mixed_supervision.
TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classication
Jun 02, 2021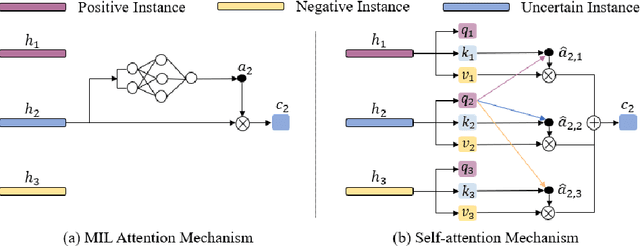
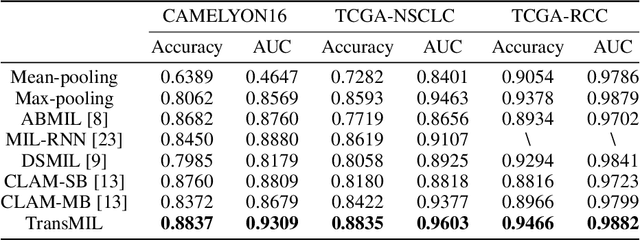

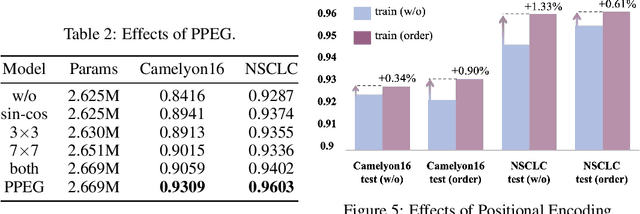
Multiple instance learning (MIL) is a powerful tool to solve the weakly supervised classification in whole slide image (WSI) based pathology diagnosis. However, the current MIL methods are usually based on independent and identical distribution hypothesis, thus neglect the correlation among different instances. To address this problem, we proposed a new framework, called correlated MIL, and provided a proof for convergence. Based on this framework, we devised a Transformer based MIL (TransMIL), which explored both morphological and spatial information. The proposed TransMIL can effectively deal with unbalanced/balanced and binary/multiple classification with great visualization and interpretability. We conducted various experiments for three different computational pathology problems and achieved better performance and faster convergence compared with state-of-the-art methods. The test AUC for the binary tumor classification can be up to 93.09% over CAMELYON16 dataset. And the AUC over the cancer subtypes classification can be up to 96.03% and 98.82% over TCGA-NSCLC dataset and TCGA-RCC dataset, respectively.