 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Diarization
Speaker diarization is the process of segmenting and clustering speech signals to identify different speakers in an audio recording.
Papers and Code
Mitigating Non-Target Speaker Bias in Guided Speaker Embedding
Jun 14, 2025Obtaining high-quality speaker embeddings in multi-speaker conditions is crucial for many applications. A recently proposed guided speaker embedding framework, which utilizes speech activities of target and non-target speakers as clues, drastically improved embeddings under severe overlap with small degradation in low-overlap cases. However, since extreme overlaps are rare in natural conversations, this degradation cannot be overlooked. This paper first reveals that the degradation is caused by the global-statistics-based modules, widely used in speaker embedding extractors, being overly sensitive to intervals containing only non-target speakers. As a countermeasure, we propose an extension of such modules that exploit the target speaker activity clues, to compute statistics from intervals where the target is active. The proposed method improves speaker verification performance in both low and high overlap ratios, and diarization performance on multiple datasets.
SeniorTalk: A Chinese Conversation Dataset with Rich Annotations for Super-Aged Seniors
Mar 20, 2025While voice technologies increasingly serve aging populations, current systems exhibit significant performance gaps due to inadequate training data capturing elderly-specific vocal characteristics like presbyphonia and dialectal variations. The limited data available on super-aged individuals in existing elderly speech datasets, coupled with overly simple recording styles and annotation dimensions, exacerbates this issue. To address the critical scarcity of speech data from individuals aged 75 and above, we introduce SeniorTalk, a carefully annotated Chinese spoken dialogue dataset. This dataset contains 55.53 hours of speech from 101 natural conversations involving 202 participants, ensuring a strategic balance across gender, region, and age. Through detailed annotation across multiple dimensions, it can support a wide range of speech tasks. We perform extensive experiments on speaker verification, speaker diarization, speech recognition, and speech editing tasks, offering crucial insights for the development of speech technologies targeting this age group.
Language Modelling for Speaker Diarization in Telephonic Interviews
Jan 28, 2025



The aim of this paper is to investigate the benefit of combining both language and acoustic modelling for speaker diarization. Although conventional systems only use acoustic features, in some scenarios linguistic data contain high discriminative speaker information, even more reliable than the acoustic ones. In this study we analyze how an appropriate fusion of both kind of features is able to obtain good results in these cases. The proposed system is based on an iterative algorithm where a LSTM network is used as a speaker classifier. The network is fed with character-level word embeddings and a GMM based acoustic score created with the output labels from previous iterations. The presented algorithm has been evaluated in a Call-Center database, which is composed of telephone interview audios. The combination of acoustic features and linguistic content shows a 84.29% improvement in terms of a word-level DER as compared to a HMM/VB baseline system. The results of this study confirms that linguistic content can be efficiently used for some speaker recognition tasks.
SCDiar: a streaming diarization system based on speaker change detection and speech recognition
Jan 28, 2025


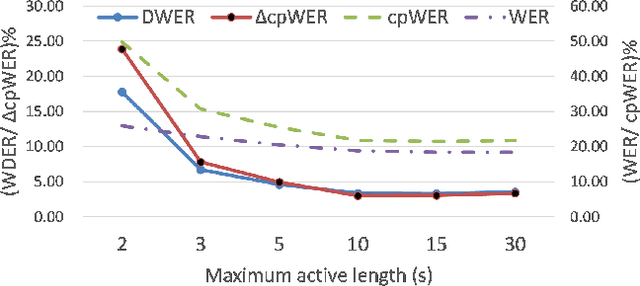
In hours-long meeting scenarios, real-time speech stream often struggles with achieving accurate speaker diarization, commonly leading to speaker identification and speaker count errors. To address this challenge, we propose SCDiar, a system that operates on speech segments, split at the token level by a speaker change detection (SCD) module. Building on these segments, we introduce several enhancements to efficiently select the best available segment for each speaker. These improvements lead to significant gains across various benchmarks. Notably, on real-world meeting data involving more than ten participants, SCDiar outperforms previous systems by up to 53.6\% in accuracy, substantially narrowing the performance gap between online and offline systems.
Afrispeech-Dialog: A Benchmark Dataset for Spontaneous English Conversations in Healthcare and Beyond
Feb 06, 2025Speech technologies are transforming interactions across various sectors, from healthcare to call centers and robots, yet their performance on African-accented conversations remains underexplored. We introduce Afrispeech-Dialog, a benchmark dataset of 50 simulated medical and non-medical African-accented English conversations, designed to evaluate automatic speech recognition (ASR) and related technologies. We assess state-of-the-art (SOTA) speaker diarization and ASR systems on long-form, accented speech, comparing their performance with native accents and discover a 10%+ performance degradation. Additionally, we explore medical conversation summarization capabilities of large language models (LLMs) to demonstrate the impact of ASR errors on downstream medical summaries, providing insights into the challenges and opportunities for speech technologies in the Global South. Our work highlights the need for more inclusive datasets to advance conversational AI in low-resource settings.
Playing with Voices: Tabletop Role-Playing Game Recordings as a Diarization Challenge
Feb 18, 2025This paper provides a proof of concept that audio of tabletop role-playing games (TTRPG) could serve as a challenge for diarization systems. TTRPGs are carried out mostly by conversation. Participants often alter their voices to indicate that they are talking as a fictional character. Audio processing systems are susceptible to voice conversion with or without technological assistance. TTRPG present a conversational phenomenon in which voice conversion is an inherent characteristic for an immersive gaming experience. This could make it more challenging for diarizers to pick the real speaker and determine that impersonating is just that. We present the creation of a small TTRPG audio dataset and compare it against the AMI and the ICSI corpus. The performance of two diarizers, pyannote.audio and wespeaker, were evaluated. We observed that TTRPGs' properties result in a higher confusion rate for both diarizers. Additionally, wespeaker strongly underestimates the number of speakers in the TTRPG audio files. We propose TTRPG audio as a promising challenge for diarization systems.
SEAL: Speaker Error Correction using Acoustic-conditioned Large Language Models
Jan 14, 2025



Speaker Diarization (SD) is a crucial component of modern end-to-end ASR pipelines. Traditional SD systems, which are typically audio-based and operate independently of ASR, often introduce speaker errors, particularly during speaker transitions and overlapping speech. Recently, language models including fine-tuned large language models (LLMs) have shown to be effective as a second-pass speaker error corrector by leveraging lexical context in the transcribed output. In this work, we introduce a novel acoustic conditioning approach to provide more fine-grained information from the acoustic diarizer to the LLM. We also show that a simpler constrained decoding strategy reduces LLM hallucinations, while avoiding complicated post-processing. Our approach significantly reduces the speaker error rates by 24-43% across Fisher, Callhome, and RT03-CTS datasets, compared to the first-pass Acoustic SD.
DiCoW: Diarization-Conditioned Whisper for Target Speaker Automatic Speech Recognition
Dec 30, 2024Speaker-attributed automatic speech recognition (ASR) in multi-speaker environments remains a significant challenge, particularly when systems conditioned on speaker embeddings fail to generalize to unseen speakers. In this work, we propose Diarization-Conditioned Whisper (DiCoW), a novel approach to target-speaker ASR that leverages speaker diarization outputs as conditioning information. DiCoW extends the pre-trained Whisper model by integrating diarization labels directly, eliminating reliance on speaker embeddings and reducing the need for extensive speaker-specific training data. Our method introduces frame-level diarization-dependent transformations (FDDT) and query-key biasing (QKb) techniques to refine the model's focus on target speakers while effectively handling overlapping speech. By leveraging diarization outputs as conditioning signals, DiCoW simplifies the workflow for multi-speaker ASR, improves generalization to unseen speakers and enables more reliable transcription in real-world multi-speaker recordings. Additionally, we explore the integration of a connectionist temporal classification (CTC) head to Whisper and demonstrate its ability to improve transcription efficiency through hybrid decoding. Notably, we show that our approach is not limited to Whisper; it also provides similar benefits when applied to the Branchformer model. We validate DiCoW on real-world datasets, including AMI and NOTSOFAR-1 from CHiME-8 challenge, as well as synthetic benchmarks such as Libri2Mix and LibriCSS, enabling direct comparisons with previous methods. Results demonstrate that DiCoW enhances the model's target-speaker ASR capabilities while maintaining Whisper's accuracy and robustness on single-speaker data.
Unsupervised Speech Segmentation: A General Approach Using Speech Language Models
Jan 07, 2025



In this paper, we introduce an unsupervised approach for Speech Segmentation, which builds on previously researched approaches, e.g., Speaker Diarization, while being applicable to an inclusive set of acoustic-semantic distinctions, paving a path towards a general Unsupervised Speech Segmentation approach. Unlike traditional speech and audio segmentation, which mainly focuses on spectral changes in the input signal, e.g., phone segmentation, our approach tries to segment the spoken utterance into chunks with differing acoustic-semantic styles, focusing on acoustic-semantic information that does not translate well into text, e.g., emotion or speaker. While most Speech Segmentation tasks only handle one style change, e.g., emotion diarization, our approach tries to handle multiple acoustic-semantic style changes. Leveraging recent advances in Speech Language Models (SLMs), we propose a simple unsupervised method to segment a given speech utterance. We empirically demonstrate the effectiveness of the proposed approach by considering several setups. Results suggest that the proposed method is superior to the evaluated baselines on boundary detection, segment purity, and over-segmentation. Code is available at https://github.com/avishaiElmakies/unsupervised_speech_segmentation_using_slm.
Universal Speaker Embedding Free Target Speaker Extraction and Personal Voice Activity Detection
Jan 07, 2025



Determining 'who spoke what and when' remains challenging in real-world applications. In typical scenarios, Speaker Diarization (SD) is employed to address the problem of 'who spoke when,' while Target Speaker Extraction (TSE) or Target Speaker Automatic Speech Recognition (TSASR) techniques are utilized to resolve the issue of 'who spoke what.' Although some works have achieved promising results by combining SD and TSE systems, inconsistencies remain between SD and TSE regarding both output inconsistency and scenario mismatch. To address these limitations, we propose a Universal Speaker Embedding Free Target Speaker Extraction and Personal Voice Activity Detection (USEF-TP) model that jointly performs TSE and Personal Voice Activity Detection (PVAD). USEF-TP leverages frame-level features obtained through a cross-attention mechanism as speaker-related features instead of using speaker embeddings as in traditional approaches. Additionally, a multi-task learning algorithm with a scenario-aware differentiated loss function is applied to ensure robust performance across various levels of speaker overlap. The experimental results show that our proposed USEF-TP model achieves superior performance in TSE and PVAD tasks on the LibriMix and SparseLibriMix datasets.