 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhu Building Dataset
Papers and Code
FOTBCD: A Large-Scale Building Change Detection Benchmark from French Orthophotos and Topographic Data
Jan 30, 2026We introduce FOTBCD, a large-scale building change detection dataset derived from authoritative French orthophotos and topographic building data provided by IGN France. Unlike existing benchmarks that are geographically constrained to single cities or limited regions, FOTBCD spans 28 departments across mainland France, with 25 used for training and three geographically disjoint departments held out for evaluation. The dataset covers diverse urban, suburban, and rural environments at 0.2m/pixel resolution. We publicly release FOTBCD-Binary, a dataset comprising approximately 28,000 before/after image pairs with pixel-wise binary building change masks, each associated with patch-level spatial metadata. The dataset is designed for large-scale benchmarking and evaluation under geographic domain shift, with validation and test samples drawn from held-out departments and manually verified to ensure label quality. In addition, we publicly release FOTBCD-Instances, a publicly available instance-level annotated subset comprising several thousand image pairs, which illustrates the complete annotation schema used in the full instance-level version of FOTBCD. Using a fixed reference baseline, we benchmark FOTBCD-Binary against LEVIR-CD+ and WHU-CD, providing strong empirical evidence that geographic diversity at the dataset level is associated with improved cross-domain generalization in building change detection.
SCANet: Split Coordinate Attention Network for Building Footprint Extraction
Jul 28, 2025Building footprint extraction holds immense significance in remote sensing image analysis and has great value in urban planning, land use, environmental protection and disaster assessment. Despite the progress made by conventional and deep learning approaches in this field, they continue to encounter significant challenges. This paper introduces a novel plug-and-play attention module, Split Coordinate Attention (SCA), which ingeniously captures spatially remote interactions by employing two spatial range of pooling kernels, strategically encoding each channel along x and y planes, and separately performs a series of split operations for each feature group, thus enabling more efficient semantic feature extraction. By inserting into a 2D CNN to form an effective SCANet, our SCANet outperforms recent SOTA methods on the public Wuhan University (WHU) Building Dataset and Massachusetts Building Dataset in terms of various metrics. Particularly SCANet achieves the best IoU, 91.61% and 75.49% for the two datasets. Our code is available at https://github.com/AiEson/SCANet
Precision Spatio-Temporal Feature Fusion for Robust Remote Sensing Change Detection
Jul 15, 2025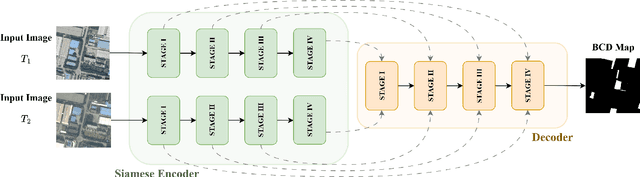
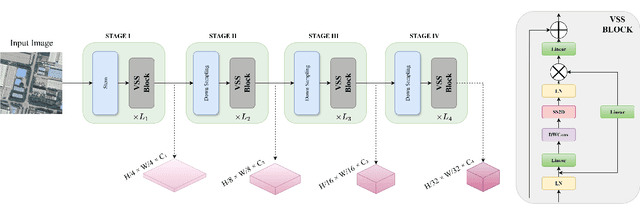
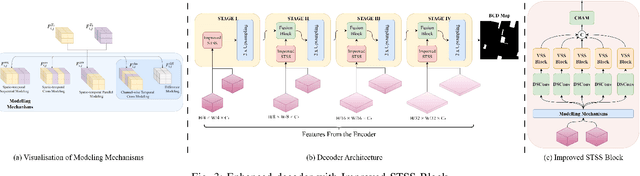

Remote sensing change detection is vital for monitoring environmental and urban transformations but faces challenges like manual feature extraction and sensitivity to noise. Traditional methods and early deep learning models, such as convolutional neural networks (CNNs), struggle to capture long-range dependencies and global context essential for accurate change detection in complex scenes. While Transformer-based models mitigate these issues, their computational complexity limits their applicability in high-resolution remote sensing. Building upon ChangeMamba architecture, which leverages state space models for efficient global context modeling, this paper proposes precision fusion blocks to capture channel-wise temporal variations and per-pixel differences for fine-grained change detection. An enhanced decoder pipeline, incorporating lightweight channel reduction mechanisms, preserves local details with minimal computational cost. Additionally, an optimized loss function combining Cross Entropy, Dice and Lovasz objectives addresses class imbalance and boosts Intersection-over-Union (IoU). Evaluations on SYSU-CD, LEVIR-CD+, and WHU-CD datasets demonstrate superior precision, recall, F1 score, IoU, and overall accuracy compared to state-of-the-art methods, highlighting the approach's robustness for remote sensing change detection. For complete transparency, the codes and pretrained models are accessible at https://github.com/Buddhi19/MambaCD.git
HiRes-FusedMIM: A High-Resolution RGB-DSM Pre-trained Model for Building-Level Remote Sensing Applications
Mar 24, 2025
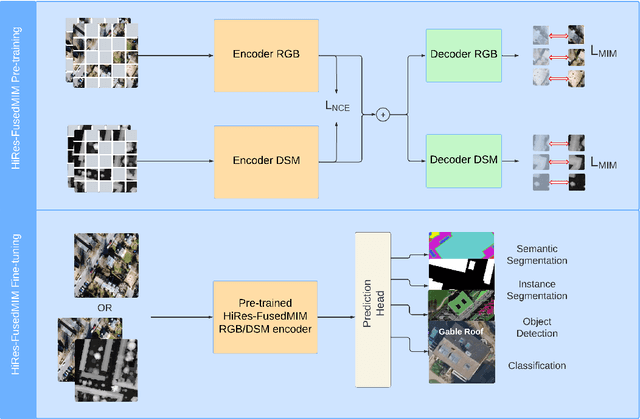
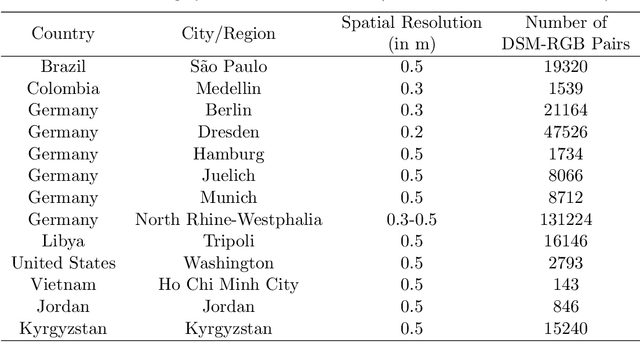

Recent advances in self-supervised learning have led to the development of foundation models that have significantly advanced performance in various computer vision tasks. However, despite their potential, these models often overlook the crucial role of high-resolution digital surface models (DSMs) in understanding urban environments, particularly for building-level analysis, which is essential for applications like digital twins. To address this gap, we introduce HiRes-FusedMIM, a novel pre-trained model specifically designed to leverage the rich information contained within high-resolution RGB and DSM data. HiRes-FusedMIM utilizes a dual-encoder simple masked image modeling (SimMIM) architecture with a multi-objective loss function that combines reconstruction and contrastive objectives, enabling it to learn powerful, joint representations from both modalities. We conducted a comprehensive evaluation of HiRes-FusedMIM on a diverse set of downstream tasks, including classification, semantic segmentation, and instance segmentation. Our results demonstrate that: 1) HiRes-FusedMIM outperforms previous state-of-the-art geospatial methods on several building-related datasets, including WHU Aerial and LoveDA, demonstrating its effectiveness in capturing and leveraging fine-grained building information; 2) Incorporating DSMs during pre-training consistently improves performance compared to using RGB data alone, highlighting the value of elevation information for building-level analysis; 3) The dual-encoder architecture of HiRes-FusedMIM, with separate encoders for RGB and DSM data, significantly outperforms a single-encoder model on the Vaihingen segmentation task, indicating the benefits of learning specialized representations for each modality. To facilitate further research and applications in this direction, we will publicly release the trained model weights.
SAM-Based Building Change Detection with Distribution-Aware Fourier Adaptation and Edge-Constrained Warping
Apr 17, 2025Building change detection remains challenging for urban development, disaster assessment, and military reconnaissance. While foundation models like Segment Anything Model (SAM) show strong segmentation capabilities, SAM is limited in the task of building change detection due to domain gap issues. Existing adapter-based fine-tuning approaches face challenges with imbalanced building distribution, resulting in poor detection of subtle changes and inaccurate edge extraction. Additionally, bi-temporal misalignment in change detection, typically addressed by optical flow, remains vulnerable to background noises. This affects the detection of building changes and compromises both detection accuracy and edge recognition. To tackle these challenges, we propose a new SAM-Based Network with Distribution-Aware Fourier Adaptation and Edge-Constrained Warping (FAEWNet) for building change detection. FAEWNet utilizes the SAM encoder to extract rich visual features from remote sensing images. To guide SAM in focusing on specific ground objects in remote sensing scenes, we propose a Distribution-Aware Fourier Aggregated Adapter to aggregate task-oriented changed information. This adapter not only effectively addresses the domain gap issue, but also pays attention to the distribution of changed buildings. Furthermore, to mitigate noise interference and misalignment in height offset estimation, we design a novel flow module that refines building edge extraction and enhances the perception of changed buildings. Our state-of-the-art results on the LEVIR-CD, S2Looking and WHU-CD datasets highlight the effectiveness of FAEWNet. The code is available at https://github.com/SUPERMAN123000/FAEWNet.
EA-3DGS: Efficient and Adaptive 3D Gaussians with Highly Enhanced Quality for outdoor scenes
May 16, 2025Efficient scene representations are essential for many real-world applications, especially those involving spatial measurement. Although current NeRF-based methods have achieved impressive results in reconstructing building-scale scenes, they still suffer from slow training and inference speeds due to time-consuming stochastic sampling. Recently, 3D Gaussian Splatting (3DGS) has demonstrated excellent performance with its high-quality rendering and real-time speed, especially for objects and small-scale scenes. However, in outdoor scenes, its point-based explicit representation lacks an effective adjustment mechanism, and the millions of Gaussian points required often lead to memory constraints during training. To address these challenges, we propose EA-3DGS, a high-quality real-time rendering method designed for outdoor scenes. First, we introduce a mesh structure to regulate the initialization of Gaussian components by leveraging an adaptive tetrahedral mesh that partitions the grid and initializes Gaussian components on each face, effectively capturing geometric structures in low-texture regions. Second, we propose an efficient Gaussian pruning strategy that evaluates each 3D Gaussian's contribution to the view and prunes accordingly. To retain geometry-critical Gaussian points, we also present a structure-aware densification strategy that densifies Gaussian points in low-curvature regions. Additionally, we employ vector quantization for parameter quantization of Gaussian components, significantly reducing disk space requirements with only a minimal impact on rendering quality. Extensive experiments on 13 scenes, including eight from four public datasets (MatrixCity-Aerial, Mill-19, Tanks \& Temples, WHU) and five self-collected scenes acquired through UAV photogrammetry measurement from SCUT-CA and plateau regions, further demonstrate the superiority of our method.
SRC-Net: Bi-Temporal Spatial Relationship Concerned Network for Change Detection
Jun 09, 2024



Change detection (CD) in remote sensing imagery is a crucial task with applications in environmental monitoring, urban development, and disaster management. CD involves utilizing bi-temporal images to identify changes over time. The bi-temporal spatial relationships between features at the same location at different times play a key role in this process. However, existing change detection networks often do not fully leverage these spatial relationships during bi-temporal feature extraction and fusion. In this work, we propose SRC-Net: a bi-temporal spatial relationship concerned network for CD. The proposed SRC-Net includes a Perception and Interaction Module that incorporates spatial relationships and establishes a cross-branch perception mechanism to enhance the precision and robustness of feature extraction. Additionally, a Patch-Mode joint Feature Fusion Module is introduced to address information loss in current methods. It considers different change modes and concerns about spatial relationships, resulting in more expressive fusion features. Furthermore, we construct a novel network using these two relationship concerned modules and conducted experiments on the LEVIR-CD and WHU Building datasets. The experimental results demonstrate that our network outperforms state-of-the-art (SOTA) methods while maintaining a modest parameter count. We believe our approach sets a new paradigm for change detection and will inspire further advancements in the field. The code and models are publicly available at https://github.com/Chnja/SRCNet.
RFL-CDNet: Towards Accurate Change Detection via Richer Feature Learning
Apr 27, 2024
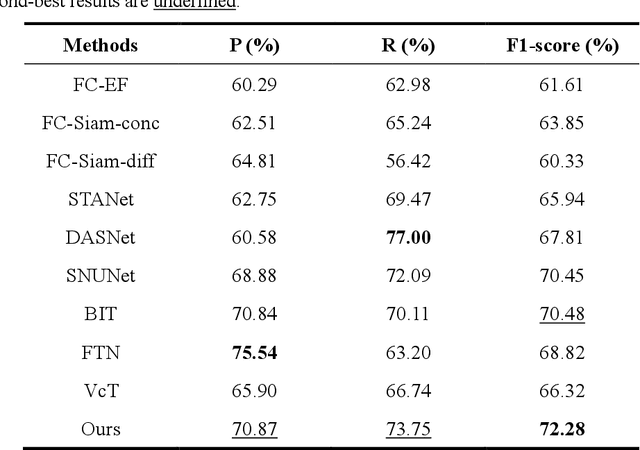
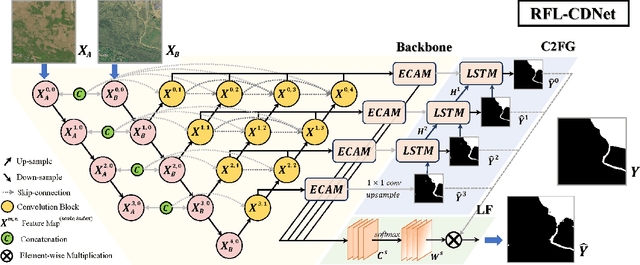
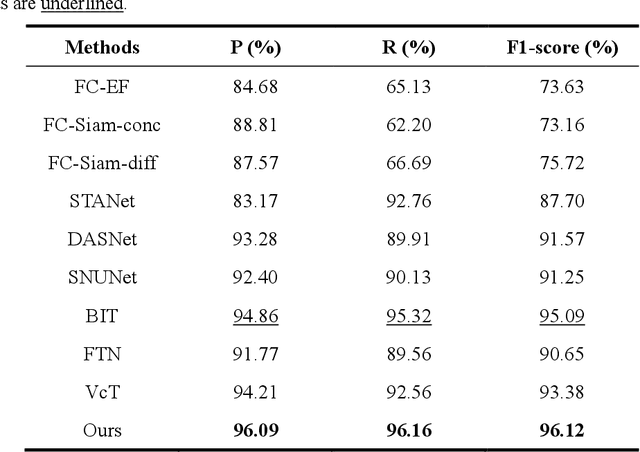
Change Detection is a crucial but extremely challenging task of remote sensing image analysis, and much progress has been made with the rapid development of deep learning. However, most existing deep learning-based change detection methods mainly focus on intricate feature extraction and multi-scale feature fusion, while ignoring the insufficient utilization of features in the intermediate stages, thus resulting in sub-optimal results. To this end, we propose a novel framework, named RFL-CDNet, that utilizes richer feature learning to boost change detection performance. Specifically, we first introduce deep multiple supervision to enhance intermediate representations, thus unleashing the potential of backbone feature extractor at each stage. Furthermore, we design the Coarse-To-Fine Guiding (C2FG) module and the Learnable Fusion (LF) module to further improve feature learning and obtain more discriminative feature representations. The C2FG module aims to seamlessly integrate the side prediction from the previous coarse-scale into the current fine-scale prediction in a coarse-to-fine manner, while LF module assumes that the contribution of each stage and each spatial location is independent, thus designing a learnable module to fuse multiple predictions. Experiments on several benchmark datasets show that our proposed RFL-CDNet achieves state-of-the-art performance on WHU cultivated land dataset and CDD dataset, and the second-best performance on WHU building dataset. The source code and models are publicly available at https://github.com/Hhaizee/RFL-CDNet.
BFA-YOLO: Balanced multiscale object detection network for multi-view building facade attachments detection
Sep 06, 2024

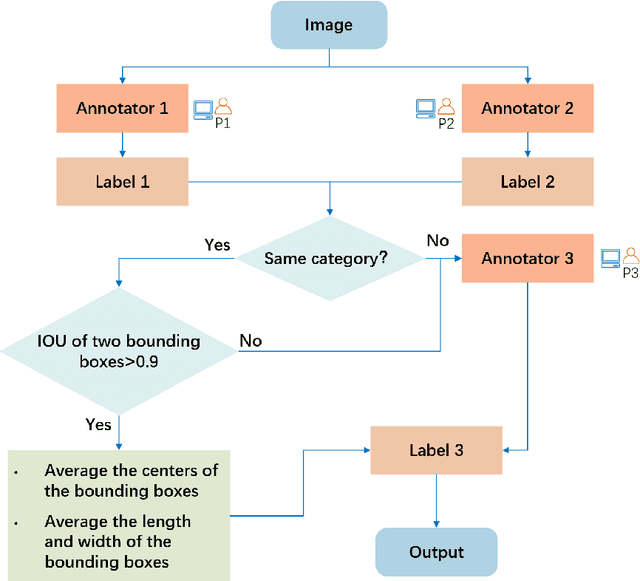

Detection of building facade attachments such as doors, windows, balconies, air conditioner units, billboards, and glass curtain walls plays a pivotal role in numerous applications. Building facade attachments detection aids in vbuilding information modeling (BIM) construction and meeting Level of Detail 3 (LOD3) standards. Yet, it faces challenges like uneven object distribution, small object detection difficulty, and background interference. To counter these, we propose BFA-YOLO, a model for detecting facade attachments in multi-view images. BFA-YOLO incorporates three novel innovations: the Feature Balanced Spindle Module (FBSM) for addressing uneven distribution, the Target Dynamic Alignment Task Detection Head (TDATH) aimed at improving small object detection, and the Position Memory Enhanced Self-Attention Mechanism (PMESA) to combat background interference, with each component specifically designed to solve its corresponding challenge. Detection efficacy of deep network models deeply depends on the dataset's characteristics. Existing open source datasets related to building facades are limited by their single perspective, small image pool, and incomplete category coverage. We propose a novel method for building facade attachments detection dataset construction and construct the BFA-3D dataset for facade attachments detection. The BFA-3D dataset features multi-view, accurate labels, diverse categories, and detailed classification. BFA-YOLO surpasses YOLOv8 by 1.8% and 2.9% in mAP@0.5 on the multi-view BFA-3D and street-view Facade-WHU datasets, respectively. These results underscore BFA-YOLO's superior performance in detecting facade attachments.
P2PFormer: A Primitive-to-polygon Method for Regular Building Contour Extraction from Remote Sensing Images
Jun 05, 2024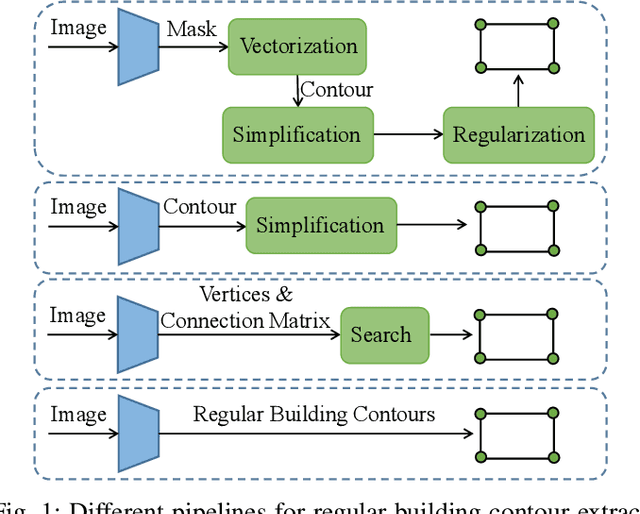



Extracting building contours from remote sensing imagery is a significant challenge due to buildings' complex and diverse shapes, occlusions, and noise. Existing methods often struggle with irregular contours, rounded corners, and redundancy points, necessitating extensive post-processing to produce regular polygonal building contours. To address these challenges, we introduce a novel, streamlined pipeline that generates regular building contours without post-processing. Our approach begins with the segmentation of generic geometric primitives (which can include vertices, lines, and corners), followed by the prediction of their sequence. This allows for the direct construction of regular building contours by sequentially connecting the segmented primitives. Building on this pipeline, we developed P2PFormer, which utilizes a transformer-based architecture to segment geometric primitives and predict their order. To enhance the segmentation of primitives, we introduce a unique representation called group queries. This representation comprises a set of queries and a singular query position, which improve the focus on multiple midpoints of primitives and their efficient linkage. Furthermore, we propose an innovative implicit update strategy for the query position embedding aimed at sharpening the focus of queries on the correct positions and, consequently, enhancing the quality of primitive segmentation. Our experiments demonstrate that P2PFormer achieves new state-of-the-art performance on the WHU, CrowdAI, and WHU-Mix datasets, surpassing the previous SOTA PolyWorld by a margin of 2.7 AP and 6.5 AP75 on the largest CrowdAI dataset. We intend to make the code and trained weights publicly available to promote their use and facilitate further research.