 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot Filling
Papers and Code
LLM-ForcedAligner: A Non-Autoregressive and Accurate LLM-Based Forced Aligner for Multilingual and Long-Form Speech
Jan 26, 2026Forced alignment (FA) predicts start and end timestamps for words or characters in speech, but existing methods are language-specific and prone to cumulative temporal shifts. The multilingual speech understanding and long-sequence processing abilities of speech large language models (SLLMs) make them promising for FA in multilingual, crosslingual, and long-form speech settings. However, directly applying the next-token prediction paradigm of SLLMs to FA results in hallucinations and slow inference. To bridge the gap, we propose LLM-ForcedAligner, reformulating FA as a slot-filling paradigm: timestamps are treated as discrete indices, and special timestamp tokens are inserted as slots into the transcript. Conditioned on the speech embeddings and the transcript with slots, the SLLM directly predicts the time indices at slots. During training, causal attention masking with non-shifted input and label sequences allows each slot to predict its own timestamp index based on itself and preceding context, with loss computed only at slot positions. Dynamic slot insertion enables FA at arbitrary positions. Moreover, non-autoregressive inference is supported, avoiding hallucinations and improving speed. Experiments across multilingual, crosslingual, and long-form speech scenarios show that LLM-ForcedAligner achieves a 69%~78% relative reduction in accumulated averaging shift compared with prior methods. The checkpoint and inference code will be released later.
Multi-Intent Spoken Language Understanding: Methods, Trends, and Challenges
Dec 12, 2025Multi-intent spoken language understanding (SLU) involves two tasks: multiple intent detection and slot filling, which jointly handle utterances containing more than one intent. Owing to this characteristic, which closely reflects real-world applications, the task has attracted increasing research attention, and substantial progress has been achieved. However, there remains a lack of a comprehensive and systematic review of existing studies on multi-intent SLU. To this end, this paper presents a survey of recent advances in multi-intent SLU. We provide an in-depth overview of previous research from two perspectives: decoding paradigms and modeling approaches. On this basis, we further compare the performance of representative models and analyze their strengths and limitations. Finally, we discuss the current challenges and outline promising directions for future research. We hope this survey will offer valuable insights and serve as a useful reference for advancing research in multi-intent SLU.
Slot Filling as a Reasoning Task for SpeechLLMs
Oct 22, 2025We propose integration of reasoning into speech large language models (speechLLMs) for the end-to-end slot-filling task. Inspired by the recent development of reasoning LLMs, we use a chain-of-thought framework to decompose the slot-filling task into multiple reasoning steps, create a reasoning dataset and apply the supervised fine-tuning strategy to a speechLLM. We distinguish between regular and reasoning speechLLMs and experiment with different types and sizes of LLMs as their text foundation models. We demonstrate performance improvements by introducing reasoning (intermediate) steps. However, we show that a reasoning textual LLM developed mainly for math, logic and coding domains might be inferior as a foundation model for a reasoning speechLLM. We further show that hybrid speechLLMs, built on a hybrid text foundation LLM and fine-tuned to preserve both direct and reasoning modes of operation, have better performance than those fine-tuned employing only one mode of operation.
Low-Altitude UAV Tracking via Sensing-Assisted Predictive Beamforming
Sep 16, 2025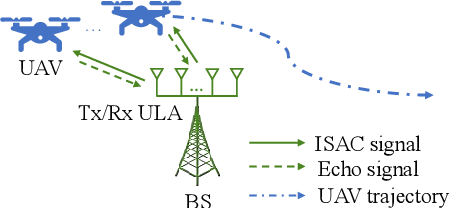
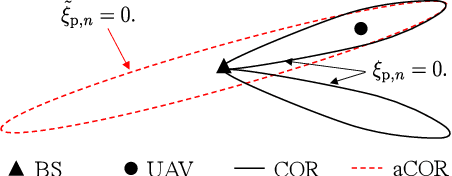
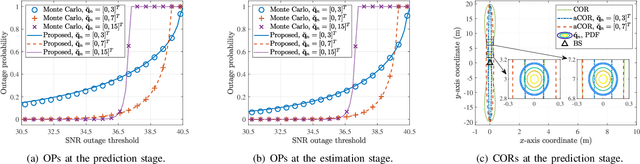
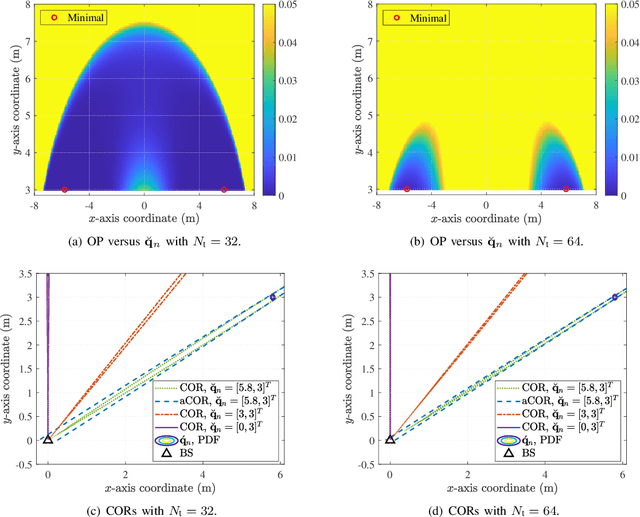
Sensing-assisted predictive beamforming, as one of the enabling technologies for emerging integrated sensing and communication (ISAC) paradigm, shows significant promise for enhancing various future unmanned aerial vehicle (UAV) applications. However, current works predominately emphasized on spectral efficiency enhancement, while the impact of such beamforming techniques on the communication reliability was largely unexplored and challenging to characterize. To fill this research gap and tackle this issue, this paper investigates outage capacity maximization for UAV tracking under the sensing-assisted predictive beamforming scheme. Specifically, a cellular-connected UAV tracking scheme is proposed leveraging extended Kalman filtering (EKF), where the predicted UAV trajectory, sensing duration ratio, and target constant received signal-to-noise ratio (SNR) are jointly optimized to maximize the outage capacity at each time slot. To address the implicit nature of the objective function, closed-form approximations of the outage probabilities (OPs) at both prediction and measurement stages of each time slot are proposed based on second-order Taylor expansions, providing an efficient and full characterization of outage capacity. Subsequently, an efficient algorithm is proposed based on a combination of bisection search and successive convex approximation (SCA) to address the non-convex optimization problem with guaranteed convergence. To further reduce computational complexity, a second efficient algorithm is developed based on alternating optimization (AO). Simulation results validate the accuracy of the derived OP approximations, the effectiveness of the proposed algorithms, and the significant outage capacity enhancement over various benchmarks, while also indicating a trade-off between decreasing path loss and enjoying wide beam coverage for outage capacity maximization.
Converting Annotated Clinical Cases into Structured Case Report Forms
Jun 13, 2025Case Report Forms (CRFs) are largely used in medical research as they ensure accuracy, reliability, and validity of results in clinical studies. However, publicly available, wellannotated CRF datasets are scarce, limiting the development of CRF slot filling systems able to fill in a CRF from clinical notes. To mitigate the scarcity of CRF datasets, we propose to take advantage of available datasets annotated for information extraction tasks and to convert them into structured CRFs. We present a semi-automatic conversion methodology, which has been applied to the E3C dataset in two languages (English and Italian), resulting in a new, high-quality dataset for CRF slot filling. Through several experiments on the created dataset, we report that slot filling achieves 59.7% for Italian and 67.3% for English on a closed Large Language Models (zero-shot) and worse performances on three families of open-source models, showing that filling CRFs is challenging even for recent state-of-the-art LLMs. We release the datest at https://huggingface.co/collections/NLP-FBK/e3c-to-crf-67b9844065460cbe42f80166
Invocable APIs derived from NL2SQL datasets for LLM Tool-Calling Evaluation
Jun 12, 2025Large language models (LLMs) are routinely deployed as agentic systems, with access to tools that interact with live environments to accomplish tasks. In enterprise deployments these systems need to interact with API collections that can be extremely large and complex, often backed by databases. In order to create datasets with such characteristics, we explore how existing NL2SQL (Natural Language to SQL query) datasets can be used to automatically create NL2API datasets. Specifically, this work describes a novel data generation pipeline that exploits the syntax of SQL queries to construct a functionally equivalent sequence of API calls. We apply this pipeline to one of the largest NL2SQL datasets, BIRD-SQL to create a collection of over 2500 APIs that can be served as invocable tools or REST-endpoints. We pair natural language queries from BIRD-SQL to ground-truth API sequences based on this API pool. We use this collection to study the performance of 10 public LLMs and find that all models struggle to determine the right set of tools (consisting of tasks of intent detection, sequencing with nested function calls, and slot-filling). We find that models have extremely low task completion rates (7-47 percent - depending on the dataset) which marginally improves to 50 percent when models are employed as ReACT agents that interact with the live API environment. The best task completion rates are far below what may be required for effective general-use tool-calling agents, suggesting substantial scope for improvement in current state-of-the-art tool-calling LLMs. We also conduct detailed ablation studies, such as assessing the impact of the number of tools available as well as the impact of tool and slot-name obfuscation. We compare the performance of models on the original SQL generation tasks and find that current models are sometimes able to exploit SQL better than APIs.
Interpretable and Robust Dialogue State Tracking via Natural Language Summarization with LLMs
Mar 11, 2025



This paper introduces a novel approach to Dialogue State Tracking (DST) that leverages Large Language Models (LLMs) to generate natural language descriptions of dialogue states, moving beyond traditional slot-value representations. Conventional DST methods struggle with open-domain dialogues and noisy inputs. Motivated by the generative capabilities of LLMs, our Natural Language DST (NL-DST) framework trains an LLM to directly synthesize human-readable state descriptions. We demonstrate through extensive experiments on MultiWOZ 2.1 and Taskmaster-1 datasets that NL-DST significantly outperforms rule-based and discriminative BERT-based DST baselines, as well as generative slot-filling GPT-2 DST models, in both Joint Goal Accuracy and Slot Accuracy. Ablation studies and human evaluations further validate the effectiveness of natural language state generation, highlighting its robustness to noise and enhanced interpretability. Our findings suggest that NL-DST offers a more flexible, accurate, and human-understandable approach to dialogue state tracking, paving the way for more robust and adaptable task-oriented dialogue systems.
Middle-Layer Representation Alignment for Cross-Lingual Transfer in Fine-Tuned LLMs
Feb 20, 2025While large language models demonstrate remarkable capabilities at task-specific applications through fine-tuning, extending these benefits across diverse languages is essential for broad accessibility. However, effective cross-lingual transfer is hindered by LLM performance gaps across languages and the scarcity of fine-tuning data in many languages. Through analysis of LLM internal representations from over 1,000+ language pairs, we discover that middle layers exhibit the strongest potential for cross-lingual alignment. Building on this finding, we propose a middle-layer alignment objective integrated into task-specific training. Our experiments on slot filling, machine translation, and structured text generation show consistent improvements in cross-lingual transfer, especially to lower-resource languages. The method is robust to the choice of alignment languages and generalizes to languages unseen during alignment. Furthermore, we show that separately trained alignment modules can be merged with existing task-specific modules, improving cross-lingual capabilities without full re-training. Our code is publicly available (https://github.com/dannigt/mid-align).
Constructions are Revealed in Word Distributions
Mar 08, 2025



Construction grammar posits that constructions (form-meaning pairings) are acquired through experience with language (the distributional learning hypothesis). But how much information about constructions does this distribution actually contain? Corpus-based analyses provide some answers, but text alone cannot answer counterfactual questions about what caused a particular word to occur. For that, we need computable models of the distribution over strings -- namely, pretrained language models (PLMs). Here we treat a RoBERTa model as a proxy for this distribution and hypothesize that constructions will be revealed within it as patterns of statistical affinity. We support this hypothesis experimentally: many constructions are robustly distinguished, including (i) hard cases where semantically distinct constructions are superficially similar, as well as (ii) schematic constructions, whose "slots" can be filled by abstract word classes. Despite this success, we also provide qualitative evidence that statistical affinity alone may be insufficient to identify all constructions from text. Thus, statistical affinity is likely an important, but partial, signal available to learners.
Improving Dialectal Slot and Intent Detection with Auxiliary Tasks: A Multi-Dialectal Bavarian Case Study
Jan 07, 2025



Reliable slot and intent detection (SID) is crucial in natural language understanding for applications like digital assistants. Encoder-only transformer models fine-tuned on high-resource languages generally perform well on SID. However, they struggle with dialectal data, where no standardized form exists and training data is scarce and costly to produce. We explore zero-shot transfer learning for SID, focusing on multiple Bavarian dialects, for which we release a new dataset for the Munich dialect. We evaluate models trained on auxiliary tasks in Bavarian, and compare joint multi-task learning with intermediate-task training. We also compare three types of auxiliary tasks: token-level syntactic tasks, named entity recognition (NER), and language modelling. We find that the included auxiliary tasks have a more positive effect on slot filling than intent classification (with NER having the most positive effect), and that intermediate-task training yields more consistent performance gains. Our best-performing approach improves intent classification performance on Bavarian dialects by 5.1 and slot filling F1 by 8.4 percentage points.