 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelativistic GAN
Papers and Code
Data relativistic uncertainty framework for low-illumination anime scenery image enhancement
Dec 26, 2025By contrast with the prevailing works of low-light enhancement in natural images and videos, this study copes with the low-illumination quality degradation in anime scenery images to bridge the domain gap. For such an underexplored enhancement task, we first curate images from various sources and construct an unpaired anime scenery dataset with diverse environments and illumination conditions to address the data scarcity. To exploit the power of uncertainty information inherent with the diverse illumination conditions, we propose a Data Relativistic Uncertainty (DRU) framework, motivated by the idea from Relativistic GAN. By analogy with the wave-particle duality of light, our framework interpretably defines and quantifies the illumination uncertainty of dark/bright samples, which is leveraged to dynamically adjust the objective functions to recalibrate the model learning under data uncertainty. Extensive experiments demonstrate the effectiveness of DRU framework by training several versions of EnlightenGANs, yielding superior perceptual and aesthetic qualities beyond the state-of-the-art methods that are incapable of learning from data uncertainty perspective. We hope our framework can expose a novel paradigm of data-centric learning for potential visual and language domains. Code is available.
Potential and challenges of generative adversarial networks for super-resolution in 4D Flow MRI
Aug 20, 20254D Flow Magnetic Resonance Imaging (4D Flow MRI) enables non-invasive quantification of blood flow and hemodynamic parameters. However, its clinical application is limited by low spatial resolution and noise, particularly affecting near-wall velocity measurements. Machine learning-based super-resolution has shown promise in addressing these limitations, but challenges remain, not least in recovering near-wall velocities. Generative adversarial networks (GANs) offer a compelling solution, having demonstrated strong capabilities in restoring sharp boundaries in non-medical super-resolution tasks. Yet, their application in 4D Flow MRI remains unexplored, with implementation challenged by known issues such as training instability and non-convergence. In this study, we investigate GAN-based super-resolution in 4D Flow MRI. Training and validation were conducted using patient-specific cerebrovascular in-silico models, converted into synthetic images via an MR-true reconstruction pipeline. A dedicated GAN architecture was implemented and evaluated across three adversarial loss functions: Vanilla, Relativistic, and Wasserstein. Our results demonstrate that the proposed GAN improved near-wall velocity recovery compared to a non-adversarial reference (vNRMSE: 6.9% vs. 9.6%); however, that implementation specifics are critical for stable network training. While Vanilla and Relativistic GANs proved unstable compared to generator-only training (vNRMSE: 8.1% and 7.8% vs. 7.2%), a Wasserstein GAN demonstrated optimal stability and incremental improvement (vNRMSE: 6.9% vs. 7.2%). The Wasserstein GAN further outperformed the generator-only baseline at low SNR (vNRMSE: 8.7% vs. 10.7%). These findings highlight the potential of GAN-based super-resolution in enhancing 4D Flow MRI, particularly in challenging cerebrovascular regions, while emphasizing the need for careful selection of adversarial strategies.
The GAN is dead; long live the GAN! A Modern GAN Baseline
Jan 09, 2025
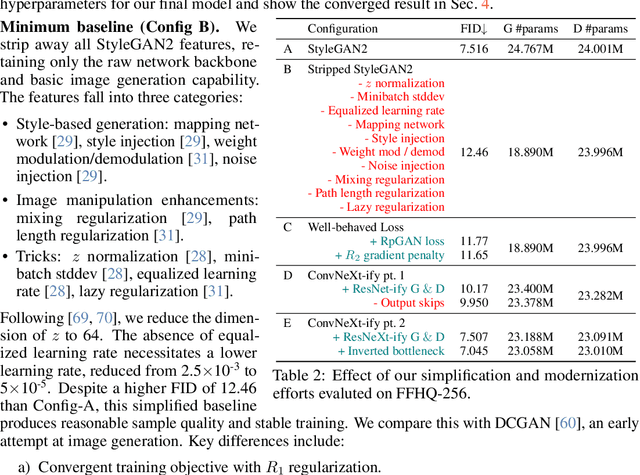


There is a widely-spread claim that GANs are difficult to train, and GAN architectures in the literature are littered with empirical tricks. We provide evidence against this claim and build a modern GAN baseline in a more principled manner. First, we derive a well-behaved regularized relativistic GAN loss that addresses issues of mode dropping and non-convergence that were previously tackled via a bag of ad-hoc tricks. We analyze our loss mathematically and prove that it admits local convergence guarantees, unlike most existing relativistic losses. Second, our new loss allows us to discard all ad-hoc tricks and replace outdated backbones used in common GANs with modern architectures. Using StyleGAN2 as an example, we present a roadmap of simplification and modernization that results in a new minimalist baseline -- R3GAN. Despite being simple, our approach surpasses StyleGAN2 on FFHQ, ImageNet, CIFAR, and Stacked MNIST datasets, and compares favorably against state-of-the-art GANs and diffusion models.
MMT-BERT: Chord-aware Symbolic Music Generation Based on Multitrack Music Transformer and MusicBERT
Sep 02, 2024We propose a novel symbolic music representation and Generative Adversarial Network (GAN) framework specially designed for symbolic multitrack music generation. The main theme of symbolic music generation primarily encompasses the preprocessing of music data and the implementation of a deep learning framework. Current techniques dedicated to symbolic music generation generally encounter two significant challenges: training data's lack of information about chords and scales and the requirement of specially designed model architecture adapted to the unique format of symbolic music representation. In this paper, we solve the above problems by introducing new symbolic music representation with MusicLang chord analysis model. We propose our MMT-BERT architecture adapting to the representation. To build a robust multitrack music generator, we fine-tune a pre-trained MusicBERT model to serve as the discriminator, and incorporate relativistic standard loss. This approach, supported by the in-depth understanding of symbolic music encoded within MusicBERT, fortifies the consonance and humanity of music generated by our method. Experimental results demonstrate the effectiveness of our approach which strictly follows the state-of-the-art methods.
Toward using GANs in astrophysical Monte-Carlo simulations
Feb 16, 2024

Accurate modelling of spectra produced by X-ray sources requires the use of Monte-Carlo simulations. These simulations need to evaluate physical processes, such as those occurring in accretion processes around compact objects by sampling a number of different probability distributions. This is computationally time-consuming and could be sped up if replaced by neural networks. We demonstrate, on an example of the Maxwell-J\"uttner distribution that describes the speed of relativistic electrons, that the generative adversarial network (GAN) is capable of statistically replicating the distribution. The average value of the Kolmogorov-Smirnov test is 0.5 for samples generated by the neural network, showing that the generated distribution cannot be distinguished from the true distribution.
ComGAN: Toward GANs Exploiting Multiple Samples
Apr 24, 2023In this paper, we propose ComGAN(ComparativeGAN) which allows the generator in GANs to refer to the semantics of comparative samples(e.g. real data) by comparison. ComGAN generalizes relativistic GANs by using arbitrary architecture and mostly outperforms relativistic GANs in simple input-concatenation architecture. To train the discriminator in ComGAN, we also propose equality regularization, which fits the discriminator to a neutral label for equally real or fake samples. Equality regularization highly boosts the performance of ComGAN including WGAN while being exceptionally simple compared to existing regularizations. Finally, we generalize comparative samples fixed to real data in relativistic GANs toward fake data and show that such objectives are sound in both theory and practice. Our experiments demonstrate superior performances of ComGAN and equality regularization, achieving the best FIDs in 7 out of 8 cases of different losses and data against ordinary GANs and relativistic GANs.
A Three-Player GAN for Super-Resolution in Magnetic Resonance Imaging
Mar 24, 2023Learning based single image super resolution (SISR) task is well investigated in 2D images. However, SISR for 3D Magnetics Resonance Images (MRI) is more challenging compared to 2D, mainly due to the increased number of neural network parameters, the larger memory requirement and the limited amount of available training data. Current SISR methods for 3D volumetric images are based on Generative Adversarial Networks (GANs), especially Wasserstein GANs due to their training stability. Other common architectures in the 2D domain, e.g. transformer models, require large amounts of training data and are therefore not suitable for the limited 3D data. However, Wasserstein GANs can be problematic because they may not converge to a global optimum and thus produce blurry results. Here, we propose a new method for 3D SR based on the GAN framework. Specifically, we use instance noise to balance the GAN training. Furthermore, we use a relativistic GAN loss function and an updating feature extractor during the training process. We show that our method produces highly accurate results. We also show that we need very few training samples. In particular, we need less than 30 samples instead of thousands of training samples that are typically required in previous studies. Finally, we show improved out-of-sample results produced by our model.
An Empirical Study on GANs with Margin Cosine Loss and Relativistic Discriminator
Oct 22, 2021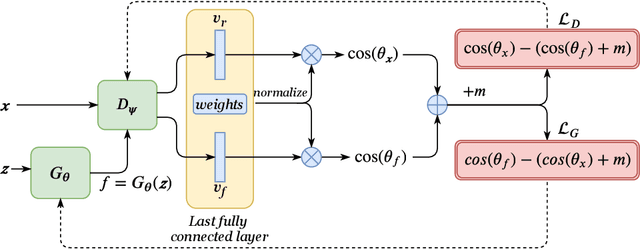
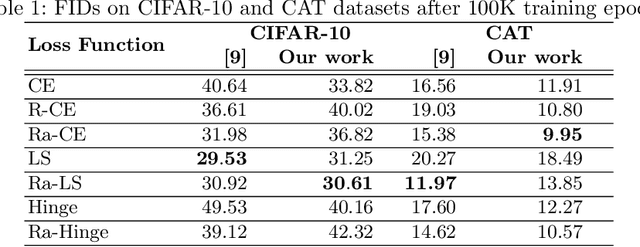
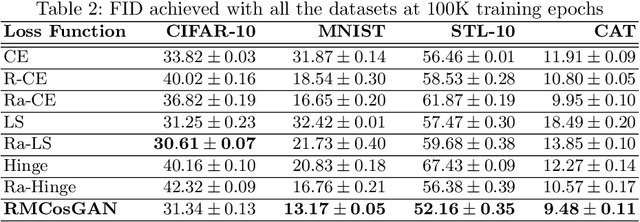
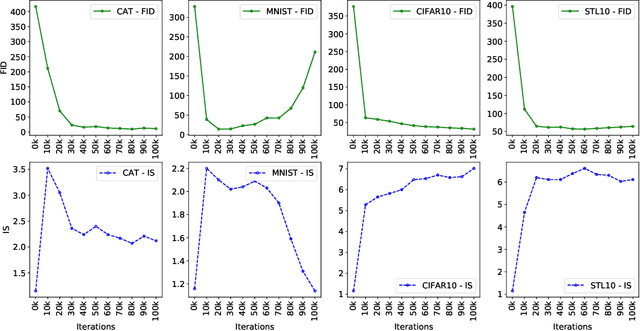
Generative Adversarial Networks (GANs) have emerged as useful generative models, which are capable of implicitly learning data distributions of arbitrarily complex dimensions. However, the training of GANs is empirically well-known for being highly unstable and sensitive. The loss functions of both the discriminator and generator concerning their parameters tend to oscillate wildly during training. Different loss functions have been proposed to stabilize the training and improve the quality of images generated. In this paper, we perform an empirical study on the impact of several loss functions on the performance of standard GAN models, Deep Convolutional Generative Adversarial Networks (DCGANs). We introduce a new improvement that employs a relativistic discriminator to replace the classical deterministic discriminator in DCGANs and implement a margin cosine loss function for both the generator and discriminator. This results in a novel loss function, namely Relativistic Margin Cosine Loss (RMCosGAN). We carry out extensive experiments with four datasets: CIFAR-$10$, MNIST, STL-$10$, and CAT. We compare RMCosGAN performance with existing loss functions based on two metrics: Frechet inception distance and inception score. The experimental results show that RMCosGAN outperforms the existing ones and significantly improves the quality of images generated.
Improve GAN-based Neural Vocoder using Pointwise Relativistic LeastSquare GAN
Mar 29, 2021
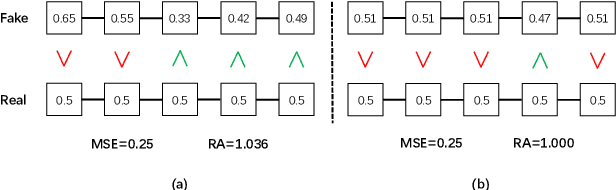
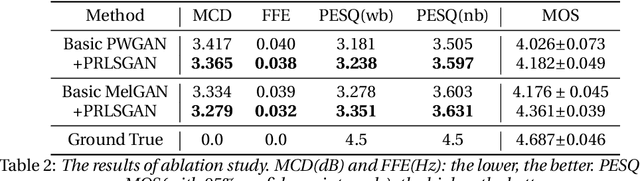
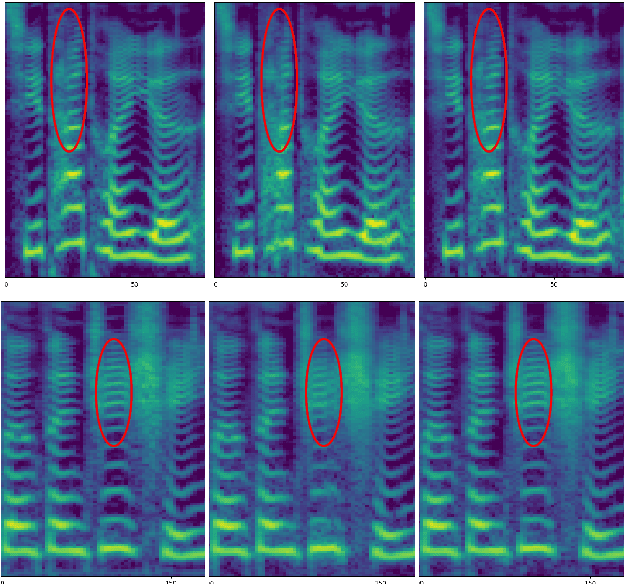
GAN-based neural vocoders, such as Parallel WaveGAN and MelGAN have attracted great interest due to their lightweight and parallel structures, enabling them to generate high fidelity waveform in a real-time manner. In this paper, inspired by Relativistic GAN, we introduce a novel variant of the LSGAN framework under the context of waveform synthesis, named Pointwise Relativistic LSGAN (PRLSGAN). In this approach, we take the truism score distribution into consideration and combine the original MSE loss with the proposed pointwise relative discrepancy loss to increase the difficulty of the generator to fool the discriminator, leading to improved generation quality. Moreover, PRLSGAN is a general-purposed framework that can be combined with any GAN-based neural vocoder to enhance its generation quality. Experiments have shown a consistent performance boost based on Parallel WaveGAN and MelGAN, demonstrating the effectiveness and strong generalization ability of our proposed PRLSGAN neural vocoders.
CRD-CGAN: Category-Consistent and Relativistic Constraints for Diverse Text-to-Image Generation
Jul 28, 2021
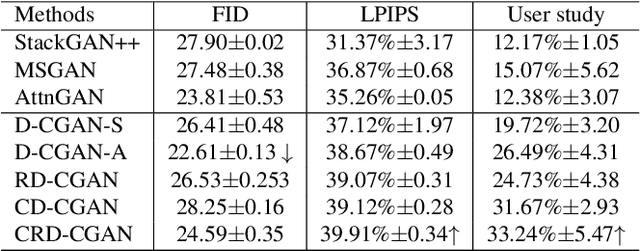


Generating photo-realistic images from a text description is a challenging problem in computer vision. Previous works have shown promising performance to generate synthetic images conditional on text by Generative Adversarial Networks (GANs). In this paper, we focus on the category-consistent and relativistic diverse constraints to optimize the diversity of synthetic images. Based on those constraints, a category-consistent and relativistic diverse conditional GAN (CRD-CGAN) is proposed to synthesize $K$ photo-realistic images simultaneously. We use the attention loss and diversity loss to improve the sensitivity of the GAN to word attention and noises. Then, we employ the relativistic conditional loss to estimate the probability of relatively real or fake for synthetic images, which can improve the performance of basic conditional loss. Finally, we introduce a category-consistent loss to alleviate the over-category issues between K synthetic images. We evaluate our approach using the Birds-200-2011, Oxford-102 flower and MSCOCO 2014 datasets, and the extensive experiments demonstrate superiority of the proposed method in comparison with state-of-the-art methods in terms of photorealistic and diversity of the generated synthetic images.