 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyn2F: An Asynchronous Federated Learning Framework with Bidirectional Model Aggregation
Mar 03, 2024



In federated learning, the models can be trained synchronously or asynchronously. Many research works have focused on developing an aggregation method for the server to aggregate multiple local models into the global model with improved performance. They ignore the heterogeneity of the training workers, which causes the delay in the training of the local models, leading to the obsolete information issue. In this paper, we design and develop Asyn2F, an Asynchronous Federated learning Framework with bidirectional model aggregation. By bidirectional model aggregation, Asyn2F, on one hand, allows the server to asynchronously aggregate multiple local models and results in a new global model. On the other hand, it allows the training workers to aggregate the new version of the global model into the local model, which is being trained even in the middle of a training epoch. We develop Asyn2F considering the practical implementation requirements such as using cloud services for model storage and message queuing protocols for communications. Extensive experiments with different datasets show that the models trained by Asyn2F achieve higher performance compared to the state-of-the-art techniques. The experiments also demonstrate the effectiveness, practicality, and scalability of Asyn2F, making it ready for deployment in real scenarios.
An Empirical Study on GANs with Margin Cosine Loss and Relativistic Discriminator
Oct 22, 2021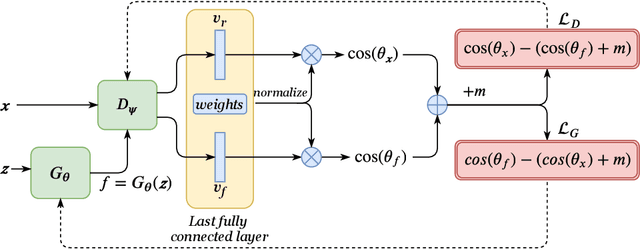
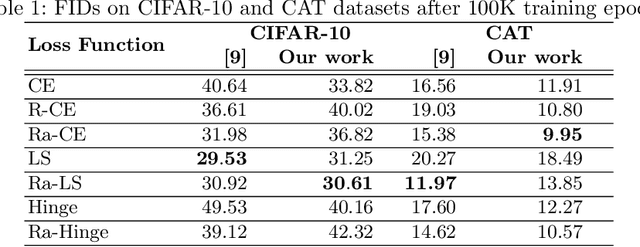
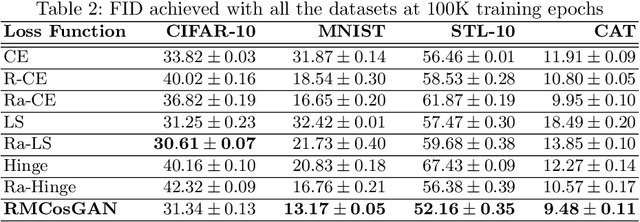
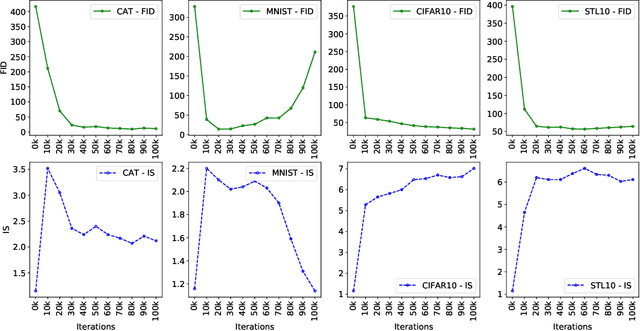
Generative Adversarial Networks (GANs) have emerged as useful generative models, which are capable of implicitly learning data distributions of arbitrarily complex dimensions. However, the training of GANs is empirically well-known for being highly unstable and sensitive. The loss functions of both the discriminator and generator concerning their parameters tend to oscillate wildly during training. Different loss functions have been proposed to stabilize the training and improve the quality of images generated. In this paper, we perform an empirical study on the impact of several loss functions on the performance of standard GAN models, Deep Convolutional Generative Adversarial Networks (DCGANs). We introduce a new improvement that employs a relativistic discriminator to replace the classical deterministic discriminator in DCGANs and implement a margin cosine loss function for both the generator and discriminator. This results in a novel loss function, namely Relativistic Margin Cosine Loss (RMCosGAN). We carry out extensive experiments with four datasets: CIFAR-$10$, MNIST, STL-$10$, and CAT. We compare RMCosGAN performance with existing loss functions based on two metrics: Frechet inception distance and inception score. The experimental results show that RMCosGAN outperforms the existing ones and significantly improves the quality of images generated.
A Federated Learning Framework for Privacy-preserving and Parallel Training
Jan 22, 2020


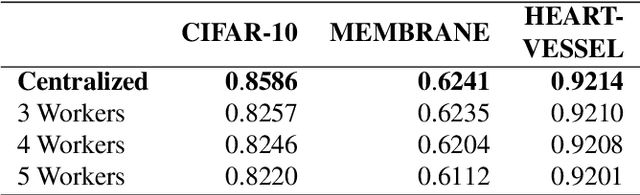
The deployment of such deep learning in practice has been hurdled by two issues: the computational cost of model training and the privacy issue of training data such as medical or healthcare records. The large size of both learning models and datasets incurs a massive computational cost, requiring efficient approaches to speed up the training phase. While parallel and distributed learning can address the issue of computational overhead, preserving the privacy of training data and intermediate results (e.g., gradients) remains a hard problem. Enabling parallel training of deep learning models on distributed datasets while preserving data privacy is even more complex and challenging. In this paper, we develop and implement FEDF, a distributed deep learning framework for privacy-preserving and parallel training. The framework allows a model to be learned on multiple geographically-distributed training datasets (which may belong to different owners) while do not reveal any information of each dataset as well as the intermediate results. We formally prove the convergence of the learning model when training with the developed framework and its privacy-preserving property. We carry out extensive experiments to evaluate the performance of the framework in terms of speedup ratio, the approximation to the upper-bound performance (when training centrally) and communication overhead between the master and training workers. The results show that the developed framework achieves a speedup of up to 9x compared to the centralized training approach and maintaining the performance approximation of the models within 4.5% of the centrally-trained models. The proposed framework also significantly reduces the amount of data exchanged between the master and training workers by up to 34% compared to existing work.