 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Federated Learning Framework for Privacy-preserving and Parallel Training
Jan 22, 2020


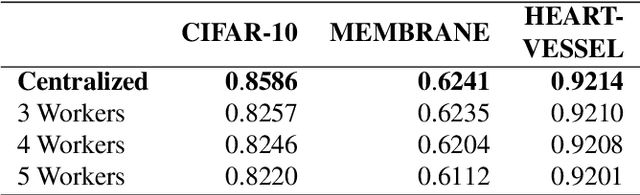
The deployment of such deep learning in practice has been hurdled by two issues: the computational cost of model training and the privacy issue of training data such as medical or healthcare records. The large size of both learning models and datasets incurs a massive computational cost, requiring efficient approaches to speed up the training phase. While parallel and distributed learning can address the issue of computational overhead, preserving the privacy of training data and intermediate results (e.g., gradients) remains a hard problem. Enabling parallel training of deep learning models on distributed datasets while preserving data privacy is even more complex and challenging. In this paper, we develop and implement FEDF, a distributed deep learning framework for privacy-preserving and parallel training. The framework allows a model to be learned on multiple geographically-distributed training datasets (which may belong to different owners) while do not reveal any information of each dataset as well as the intermediate results. We formally prove the convergence of the learning model when training with the developed framework and its privacy-preserving property. We carry out extensive experiments to evaluate the performance of the framework in terms of speedup ratio, the approximation to the upper-bound performance (when training centrally) and communication overhead between the master and training workers. The results show that the developed framework achieves a speedup of up to 9x compared to the centralized training approach and maintaining the performance approximation of the models within 4.5% of the centrally-trained models. The proposed framework also significantly reduces the amount of data exchanged between the master and training workers by up to 34% compared to existing work.