 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Suicidal Risk on Social Media: A Hybrid Model
May 26, 2025Suicidal thoughts and behaviors are increasingly recognized as a critical societal concern, highlighting the urgent need for effective tools to enable early detection of suicidal risk. In this work, we develop robust machine learning models that leverage Reddit posts to automatically classify them into four distinct levels of suicide risk severity. We frame this as a multi-class classification task and propose a RoBERTa-TF-IDF-PCA Hybrid model, integrating the deep contextual embeddings from Robustly Optimized BERT Approach (RoBERTa), a state-of-the-art deep learning transformer model, with the statistical term-weighting of TF-IDF, further compressed with PCA, to boost the accuracy and reliability of suicide risk assessment. To address data imbalance and overfitting, we explore various data resampling techniques and data augmentation strategies to enhance model generalization. Additionally, we compare our model's performance against that of using RoBERTa only, the BERT model and other traditional machine learning classifiers. Experimental results demonstrate that the hybrid model can achieve improved performance, giving a best weighted $F_{1}$ score of 0.7512.
Predicting Performances of Mutual Funds using Deep Learning and Ensemble Techniques
Sep 18, 2022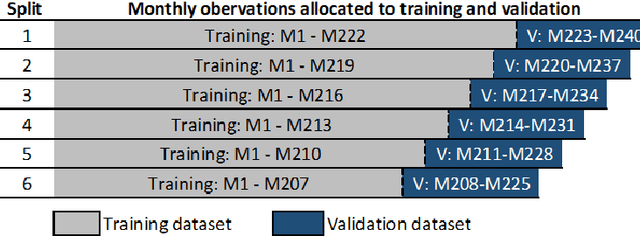
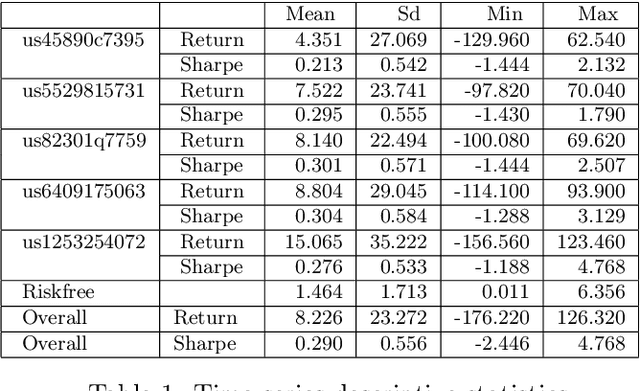

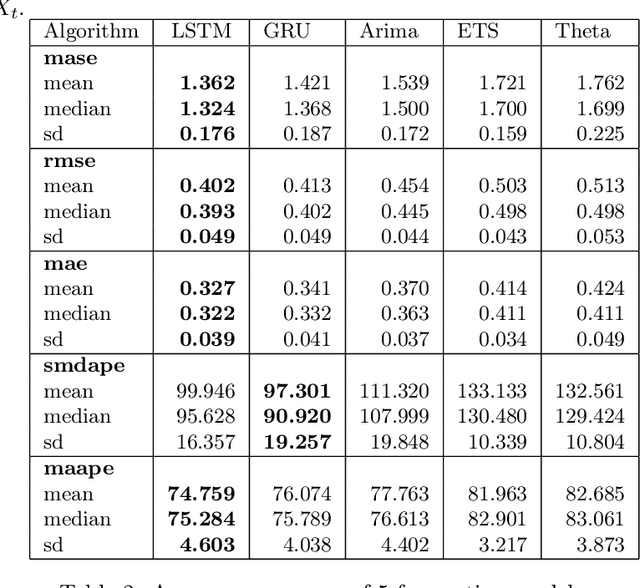
Predicting fund performance is beneficial to both investors and fund managers, and yet is a challenging task. In this paper, we have tested whether deep learning models can predict fund performance more accurately than traditional statistical techniques. Fund performance is typically evaluated by the Sharpe ratio, which represents the risk-adjusted performance to ensure meaningful comparability across funds. We calculated the annualised Sharpe ratios based on the monthly returns time series data for more than 600 open-end mutual funds investing in listed large-cap equities in the United States. We find that long short-term memory (LSTM) and gated recurrent units (GRUs) deep learning methods, both trained with modern Bayesian optimization, provide higher accuracy in forecasting funds' Sharpe ratios than traditional statistical ones. An ensemble method, which combines forecasts from LSTM and GRUs, achieves the best performance of all models. There is evidence to say that deep learning and ensembling offer promising solutions in addressing the challenge of fund performance forecasting.
A Federated Learning Framework for Privacy-preserving and Parallel Training
Jan 22, 2020


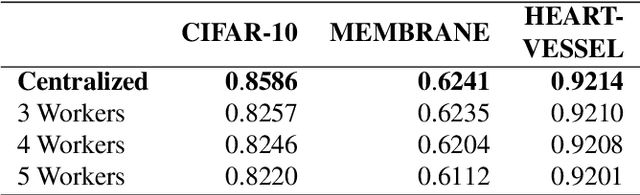
The deployment of such deep learning in practice has been hurdled by two issues: the computational cost of model training and the privacy issue of training data such as medical or healthcare records. The large size of both learning models and datasets incurs a massive computational cost, requiring efficient approaches to speed up the training phase. While parallel and distributed learning can address the issue of computational overhead, preserving the privacy of training data and intermediate results (e.g., gradients) remains a hard problem. Enabling parallel training of deep learning models on distributed datasets while preserving data privacy is even more complex and challenging. In this paper, we develop and implement FEDF, a distributed deep learning framework for privacy-preserving and parallel training. The framework allows a model to be learned on multiple geographically-distributed training datasets (which may belong to different owners) while do not reveal any information of each dataset as well as the intermediate results. We formally prove the convergence of the learning model when training with the developed framework and its privacy-preserving property. We carry out extensive experiments to evaluate the performance of the framework in terms of speedup ratio, the approximation to the upper-bound performance (when training centrally) and communication overhead between the master and training workers. The results show that the developed framework achieves a speedup of up to 9x compared to the centralized training approach and maintaining the performance approximation of the models within 4.5% of the centrally-trained models. The proposed framework also significantly reduces the amount of data exchanged between the master and training workers by up to 34% compared to existing work.