 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Text Classification
Multilingual text classification is the process of categorizing text documents in multiple languages into predefined categories.
Papers and Code
MOSLD-Bench: Multilingual Open-Set Learning and Discovery Benchmark for Text Categorization
Jan 19, 2026Open-set learning and discovery (OSLD) is a challenging machine learning task in which samples from new (unknown) classes can appear at test time. It can be seen as a generalization of zero-shot learning, where the new classes are not known a priori, hence involving the active discovery of new classes. While zero-shot learning has been extensively studied in text classification, especially with the emergence of pre-trained language models, open-set learning and discovery is a comparatively new setup for the text domain. To this end, we introduce the first multilingual open-set learning and discovery (MOSLD) benchmark for text categorization by topic, comprising 960K data samples across 12 languages. To construct the benchmark, we (i) rearrange existing datasets and (ii) collect new data samples from the news domain. Moreover, we propose a novel framework for the OSLD task, which integrates multiple stages to continuously discover and learn new classes. We evaluate several language models, including our own, to obtain results that can be used as reference for future work. We release our benchmark at https://github.com/Adriana19Valentina/MOSLD-Bench.
BYOL: Bring Your Own Language Into LLMs
Jan 15, 2026Large Language Models (LLMs) exhibit strong multilingual capabilities, yet remain fundamentally constrained by the severe imbalance in global language resources. While over 7,000 languages are spoken worldwide, only a small subset (fewer than 100) has sufficient digital presence to meaningfully influence modern LLM training. This disparity leads to systematic underperformance, cultural misalignment, and limited accessibility for speakers of low-resource and extreme-low-resource languages. To address this gap, we introduce Bring Your Own Language (BYOL), a unified framework for scalable, language-aware LLM development tailored to each language's digital footprint. BYOL begins with a language resource classification that maps languages into four tiers (Extreme-Low, Low, Mid, High) using curated web-scale corpora, and uses this classification to select the appropriate integration pathway. For low-resource languages, we propose a full-stack data refinement and expansion pipeline that combines corpus cleaning, synthetic text generation, continual pretraining, and supervised finetuning. Applied to Chichewa and Maori, this pipeline yields language-specific LLMs that achieve approximately 12 percent average improvement over strong multilingual baselines across 12 benchmarks, while preserving English and multilingual capabilities via weight-space model merging. For extreme-low-resource languages, we introduce a translation-mediated inclusion pathway, and show on Inuktitut that a tailored machine translation system improves over a commercial baseline by 4 BLEU, enabling high-accuracy LLM access when direct language modeling is infeasible. Finally, we release human-translated versions of the Global MMLU-Lite benchmark in Chichewa, Maori, and Inuktitut, and make our codebase and models publicly available at https://github.com/microsoft/byol .
VoxCog: Towards End-to-End Multilingual Cognitive Impairment Classification through Dialectal Knowledge
Jan 12, 2026In this work, we present a novel perspective on cognitive impairment classification from speech by integrating speech foundation models that explicitly recognize speech dialects. Our motivation is based on the observation that individuals with Alzheimer's Disease (AD) or mild cognitive impairment (MCI) often produce measurable speech characteristics, such as slower articulation rate and lengthened sounds, in a manner similar to dialectal phonetic variations seen in speech. Building on this idea, we introduce VoxCog, an end-to-end framework that uses pre-trained dialect models to detect AD or MCI without relying on additional modalities such as text or images. Through experiments on multiple multilingual datasets for AD and MCI detection, we demonstrate that model initialization with a dialect classifier on top of speech foundation models consistently improves the predictive performance of AD or MCI. Our trained models yield similar or often better performance compared to previous approaches that ensembled several computational methods using different signal modalities. Particularly, our end-to-end speech-based model achieves 87.5% and 85.9% accuracy on the ADReSS 2020 challenge and ADReSSo 2021 challenge test sets, outperforming existing solutions that use multimodal ensemble-based computation or LLMs.
Qalb: Largest State-of-the-Art Urdu Large Language Model for 230M Speakers with Systematic Continued Pre-training
Jan 13, 2026Despite remarkable progress in large language models, Urdu-a language spoken by over 230 million people-remains critically underrepresented in modern NLP systems. Existing multilingual models demonstrate poor performance on Urdu-specific tasks, struggling with the language's complex morphology, right-to-left Nastaliq script, and rich literary traditions. Even the base LLaMA-3.1 8B-Instruct model shows limited capability in generating fluent, contextually appropriate Urdu text. We introduce Qalb, an Urdu language model developed through a two-stage approach: continued pre-training followed by supervised fine-tuning. Starting from LLaMA 3.1 8B, we perform continued pre-training on a dataset of 1.97 billion tokens. This corpus comprises 1.84 billion tokens of diverse Urdu text-spanning news archives, classical and contemporary literature, government documents, and social media-combined with 140 million tokens of English Wikipedia data to prevent catastrophic forgetting. We then fine-tune the resulting model on the Alif Urdu-instruct dataset. Through extensive evaluation on Urdu-specific benchmarks, Qalb demonstrates substantial improvements, achieving a weighted average score of 90.34 and outperforming the previous state-of-the-art Alif-1.0-Instruct model (87.1) by 3.24 points, while also surpassing the base LLaMA-3.1 8B-Instruct model by 44.64 points. Qalb achieves state-of-the-art performance with comprehensive evaluation across seven diverse tasks including Classification, Sentiment Analysis, and Reasoning. Our results demonstrate that continued pre-training on diverse, high-quality language data, combined with targeted instruction fine-tuning, effectively adapts foundation models to low-resource languages.
X-MuTeST: A Multilingual Benchmark for Explainable Hate Speech Detection and A Novel LLM-consulted Explanation Framework
Jan 06, 2026Hate speech detection on social media faces challenges in both accuracy and explainability, especially for underexplored Indic languages. We propose a novel explainability-guided training framework, X-MuTeST (eXplainable Multilingual haTe Speech deTection), for hate speech detection that combines high-level semantic reasoning from large language models (LLMs) with traditional attention-enhancing techniques. We extend this research to Hindi and Telugu alongside English by providing benchmark human-annotated rationales for each word to justify the assigned class label. The X-MuTeST explainability method computes the difference between the prediction probabilities of the original text and those of unigrams, bigrams, and trigrams. Final explanations are computed as the union between LLM explanations and X-MuTeST explanations. We show that leveraging human rationales during training enhances both classification performance and explainability. Moreover, combining human rationales with our explainability method to refine the model attention yields further improvements. We evaluate explainability using Plausibility metrics such as Token-F1 and IOU-F1 and Faithfulness metrics such as Comprehensiveness and Sufficiency. By focusing on under-resourced languages, our work advances hate speech detection across diverse linguistic contexts. Our dataset includes token-level rationale annotations for 6,004 Hindi, 4,492 Telugu, and 6,334 English samples. Data and code are available on https://github.com/ziarehman30/X-MuTeST
* Accepted in the proceedings of AAAI 2026
Low-Resource, High-Impact: Building Corpora for Inclusive Language Technologies
Dec 16, 2025This tutorial (https://tum-nlp.github.io/low-resource-tutorial) is designed for NLP practitioners, researchers, and developers working with multilingual and low-resource languages who seek to create more equitable and socially impactful language technologies. Participants will walk away with a practical toolkit for building end-to-end NLP pipelines for underrepresented languages -- from data collection and web crawling to parallel sentence mining, machine translation, and downstream applications such as text classification and multimodal reasoning. The tutorial presents strategies for tackling the challenges of data scarcity and cultural variance, offering hands-on methods and modeling frameworks. We will focus on fair, reproducible, and community-informed development approaches, grounded in real-world scenarios. We will showcase a diverse set of use cases covering over 10 languages from different language families and geopolitical contexts, including both digitally resource-rich and severely underrepresented languages.
Correcting Mean Bias in Text Embeddings: A Refined Renormalization with Training-Free Improvements on MMTEB
Nov 14, 2025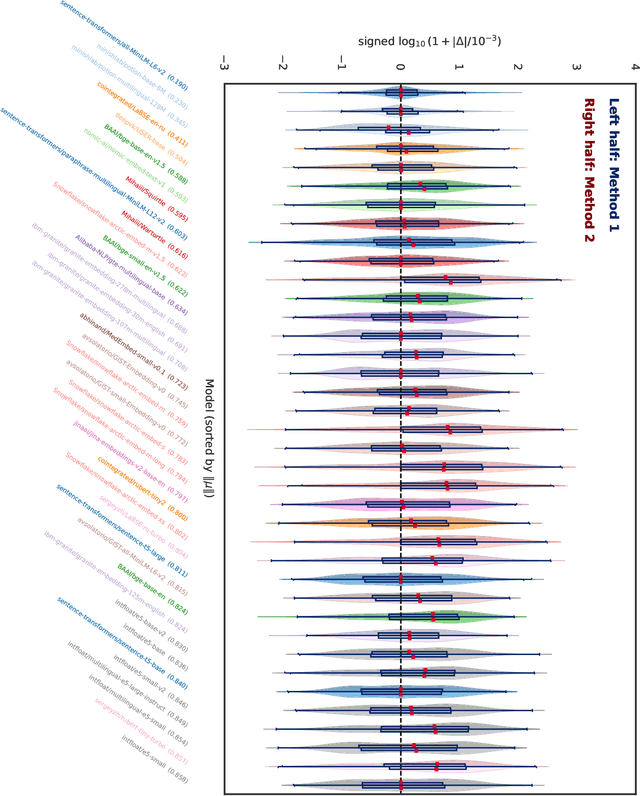
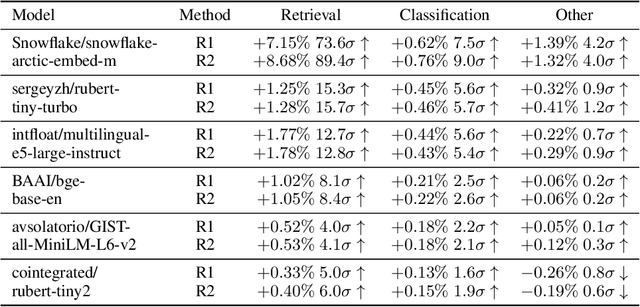
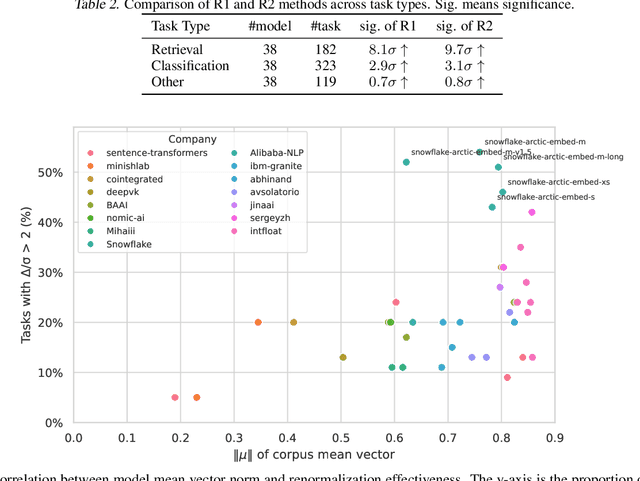
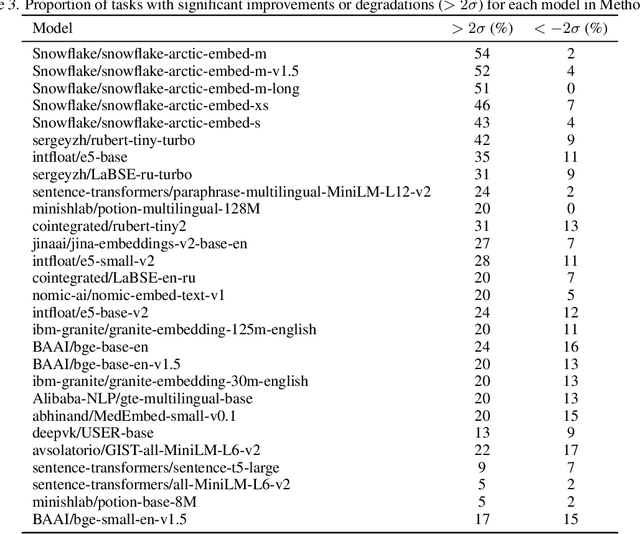
We find that current text embedding models produce outputs with a consistent bias, i.e., each embedding vector $e$ can be decomposed as $\tilde{e} + μ$, where $μ$ is almost identical across all sentences. We propose a plug-and-play, training-free and lightweight solution called Renormalization. Through extensive experiments, we show that renormalization consistently and statistically significantly improves the performance of existing models on the Massive Multilingual Text Embedding Benchmark (MMTEB). In particular, across 38 models, renormalization improves performance by 9.7 $σ$ on retrieval tasks, 3.1 $σ$ on classification tasks, and 0.8 $σ$ on other types of tasks. Renormalization has two variants: directly subtracting $μ$ from $e$, or subtracting the projection of $e$ onto $μ$. We theoretically predict that the latter performs better, and our experiments confirm this prediction.
Llama-Embed-Nemotron-8B: A Universal Text Embedding Model for Multilingual and Cross-Lingual Tasks
Nov 10, 2025We introduce llama-embed-nemotron-8b, an open-weights text embedding model that achieves state-of-the-art performance on the Multilingual Massive Text Embedding Benchmark (MMTEB) leaderboard as of October 21, 2025. While recent models show strong performance, their training data or methodologies are often not fully disclosed. We aim to address this by developing a fully open-source model, publicly releasing its weights and detailed ablation studies, and planning to share the curated training datasets. Our model demonstrates superior performance across all major embedding tasks -- including retrieval, classification and semantic textual similarity (STS) -- and excels in challenging multilingual scenarios, such as low-resource languages and cross-lingual setups. This state-of-the-art performance is driven by a novel data mix of 16.1 million query-document pairs, split between 7.7 million samples from public datasets and 8.4 million synthetically generated examples from various open-weight LLMs. One of our key contributions is a detailed ablation study analyzing core design choices, including a comparison of contrastive loss implementations, an evaluation of synthetic data generation (SDG) strategies, and the impact of model merging. The llama-embed-nemotron-8b is an instruction-aware model, supporting user-defined instructions to enhance performance for specific use-cases. This combination of top-tier performance, broad applicability, and user-driven flexibility enables it to serve as a universal text embedding solution.
BUSTED at AraGenEval Shared Task: A Comparative Study of Transformer-Based Models for Arabic AI-Generated Text Detection
Oct 23, 2025This paper details our submission to the Ara- GenEval Shared Task on Arabic AI-generated text detection, where our team, BUSTED, se- cured 5th place. We investigated the effec- tiveness of three pre-trained transformer mod- els: AraELECTRA, CAMeLBERT, and XLM- RoBERTa. Our approach involved fine-tuning each model on the provided dataset for a binary classification task. Our findings revealed a sur- prising result: the multilingual XLM-RoBERTa model achieved the highest performance with an F1 score of 0.7701, outperforming the spe- cialized Arabic models. This work underscores the complexities of AI-generated text detection and highlights the strong generalization capa- bilities of multilingual models.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.