 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalization In Video Forgery
Papers and Code
Mining Forgery Traces from Reconstruction Error: A Weakly Supervised Framework for Multimodal Deepfake Temporal Localization
Jan 29, 2026Modern deepfakes have evolved into localized and intermittent manipulations that require fine-grained temporal localization. The prohibitive cost of frame-level annotation makes weakly supervised methods a practical necessity, which rely only on video-level labels. To this end, we propose Reconstruction-based Temporal Deepfake Localization (RT-DeepLoc), a weakly supervised temporal forgery localization framework that identifies forgeries via reconstruction errors. Our framework uses a Masked Autoencoder (MAE) trained exclusively on authentic data to learn its intrinsic spatiotemporal patterns; this allows the model to produce significant reconstruction discrepancies for forged segments, effectively providing the missing fine-grained cues for localization. To robustly leverage these indicators, we introduce a novel Asymmetric Intra-video Contrastive Loss (AICL). By focusing on the compactness of authentic features guided by these reconstruction cues, AICL establishes a stable decision boundary that enhances local discrimination while preserving generalization to unseen forgeries. Extensive experiments on large-scale datasets, including LAV-DF, demonstrate that RT-DeepLoc achieves state-of-the-art performance in weakly-supervised temporal forgery localization.
DDNet: A Dual-Stream Graph Learning and Disentanglement Framework for Temporal Forgery Localization
Jan 05, 2026The rapid evolution of AIGC technology enables misleading viewers by tampering mere small segments within a video, rendering video-level detection inaccurate and unpersuasive. Consequently, temporal forgery localization (TFL), which aims to precisely pinpoint tampered segments, becomes critical. However, existing methods are often constrained by \emph{local view}, failing to capture global anomalies. To address this, we propose a \underline{d}ual-stream graph learning and \underline{d}isentanglement framework for temporal forgery localization (DDNet). By coordinating a \emph{Temporal Distance Stream} for local artifacts and a \emph{Semantic Content Stream} for long-range connections, DDNet prevents global cues from being drowned out by local smoothness. Furthermore, we introduce Trace Disentanglement and Adaptation (TDA) to isolate generic forgery fingerprints, alongside Cross-Level Feature Embedding (CLFE) to construct a robust feature foundation via deep fusion of hierarchical features. Experiments on ForgeryNet and TVIL benchmarks demonstrate that our method outperforms state-of-the-art approaches by approximately 9\% in AP@0.95, with significant improvements in cross-domain robustness.
Towards Robust DeepFake Detection under Unstable Face Sequences: Adaptive Sparse Graph Embedding with Order-Free Representation and Explicit Laplacian Spectral Prior
Dec 08, 2025Ensuring the authenticity of video content remains challenging as DeepFake generation becomes increasingly realistic and robust against detection. Most existing detectors implicitly assume temporally consistent and clean facial sequences, an assumption that rarely holds in real-world scenarios where compression artifacts, occlusions, and adversarial attacks destabilize face detection and often lead to invalid or misdetected faces. To address these challenges, we propose a Laplacian-Regularized Graph Convolutional Network (LR-GCN) that robustly detects DeepFakes from noisy or unordered face sequences, while being trained only on clean facial data. Our method constructs an Order-Free Temporal Graph Embedding (OF-TGE) that organizes frame-wise CNN features into an adaptive sparse graph based on semantic affinities. Unlike traditional methods constrained by strict temporal continuity, OF-TGE captures intrinsic feature consistency across frames, making it resilient to shuffled, missing, or heavily corrupted inputs. We further impose a dual-level sparsity mechanism on both graph structure and node features to suppress the influence of invalid faces. Crucially, we introduce an explicit Graph Laplacian Spectral Prior that acts as a high-pass operator in the graph spectral domain, highlighting structural anomalies and forgery artifacts, which are then consolidated by a low-pass GCN aggregation. This sequential design effectively realizes a task-driven spectral band-pass mechanism that suppresses background information and random noise while preserving manipulation cues. Extensive experiments on FF++, Celeb-DFv2, and DFDC demonstrate that LR-GCN achieves state-of-the-art performance and significantly improved robustness under severe global and local disruptions, including missing faces, occlusions, and adversarially perturbed face detections.
Toward Real-world Text Image Forgery Localization: Structured and Interpretable Data Synthesis
Nov 16, 2025Existing Text Image Forgery Localization (T-IFL) methods often suffer from poor generalization due to the limited scale of real-world datasets and the distribution gap caused by synthetic data that fails to capture the complexity of real-world tampering. To tackle this issue, we propose Fourier Series-based Tampering Synthesis (FSTS), a structured and interpretable framework for synthesizing tampered text images. FSTS first collects 16,750 real-world tampering instances from five representative tampering types, using a structured pipeline that records human-performed editing traces via multi-format logs (e.g., video, PSD, and editing logs). By analyzing these collected parameters and identifying recurring behavioral patterns at both individual and population levels, we formulate a hierarchical modeling framework. Specifically, each individual tampering parameter is represented as a compact combination of basis operation-parameter configurations, while the population-level distribution is constructed by aggregating these behaviors. Since this formulation draws inspiration from the Fourier series, it enables an interpretable approximation using basis functions and their learned weights. By sampling from this modeled distribution, FSTS synthesizes diverse and realistic training data that better reflect real-world forgery traces. Extensive experiments across four evaluation protocols demonstrate that models trained with FSTS data achieve significantly improved generalization on real-world datasets. Dataset is available at \href{https://github.com/ZeqinYu/FSTS}{Project Page}.
Multi-modal Deepfake Detection and Localization with FPN-Transformer
Nov 11, 2025The rapid advancement of generative adversarial networks (GANs) and diffusion models has enabled the creation of highly realistic deepfake content, posing significant threats to digital trust across audio-visual domains. While unimodal detection methods have shown progress in identifying synthetic media, their inability to leverage cross-modal correlations and precisely localize forged segments limits their practicality against sophisticated, fine-grained manipulations. To address this, we introduce a multi-modal deepfake detection and localization framework based on a Feature Pyramid-Transformer (FPN-Transformer), addressing critical gaps in cross-modal generalization and temporal boundary regression. The proposed approach utilizes pre-trained self-supervised models (WavLM for audio, CLIP for video) to extract hierarchical temporal features. A multi-scale feature pyramid is constructed through R-TLM blocks with localized attention mechanisms, enabling joint analysis of cross-context temporal dependencies. The dual-branch prediction head simultaneously predicts forgery probabilities and refines temporal offsets of manipulated segments, achieving frame-level localization precision. We evaluate our approach on the test set of the IJCAI'25 DDL-AV benchmark, showing a good performance with a final score of 0.7535 for cross-modal deepfake detection and localization in challenging environments. Experimental results confirm the effectiveness of our approach and provide a novel way for generalized deepfake detection. Our code is available at https://github.com/Zig-HS/MM-DDL
SpeechForensics: Audio-Visual Speech Representation Learning for Face Forgery Detection
Aug 13, 2025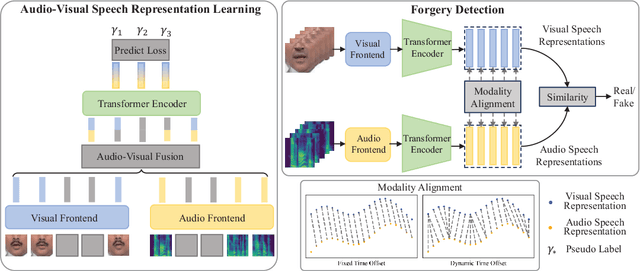
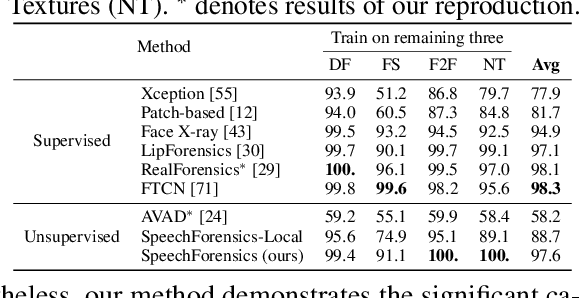
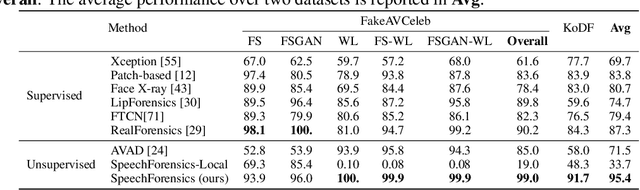
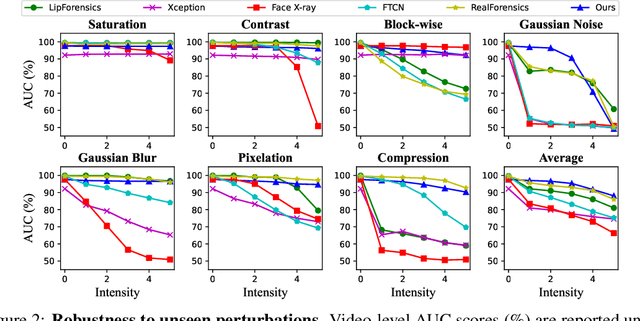
Detection of face forgery videos remains a formidable challenge in the field of digital forensics, especially the generalization to unseen datasets and common perturbations. In this paper, we tackle this issue by leveraging the synergy between audio and visual speech elements, embarking on a novel approach through audio-visual speech representation learning. Our work is motivated by the finding that audio signals, enriched with speech content, can provide precise information effectively reflecting facial movements. To this end, we first learn precise audio-visual speech representations on real videos via a self-supervised masked prediction task, which encodes both local and global semantic information simultaneously. Then, the derived model is directly transferred to the forgery detection task. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods in terms of cross-dataset generalization and robustness, without the participation of any fake video in model training. Code is available at https://github.com/Eleven4AI/SpeechForensics.
* Accepted by NeurIPS 2024
A Multimodal Deviation Perceiving Framework for Weakly-Supervised Temporal Forgery Localization
Jul 22, 2025Current researches on Deepfake forensics often treat detection as a classification task or temporal forgery localization problem, which are usually restrictive, time-consuming, and challenging to scale for large datasets. To resolve these issues, we present a multimodal deviation perceiving framework for weakly-supervised temporal forgery localization (MDP), which aims to identify temporal partial forged segments using only video-level annotations. The MDP proposes a novel multimodal interaction mechanism (MI) and an extensible deviation perceiving loss to perceive multimodal deviation, which achieves the refined start and end timestamps localization of forged segments. Specifically, MI introduces a temporal property preserving cross-modal attention to measure the relevance between the visual and audio modalities in the probabilistic embedding space. It could identify the inter-modality deviation and construct comprehensive video features for temporal forgery localization. To explore further temporal deviation for weakly-supervised learning, an extensible deviation perceiving loss has been proposed, aiming at enlarging the deviation of adjacent segments of the forged samples and reducing that of genuine samples. Extensive experiments demonstrate the effectiveness of the proposed framework and achieve comparable results to fully-supervised approaches in several evaluation metrics.
Context-aware TFL: A Universal Context-aware Contrastive Learning Framework for Temporal Forgery Localization
Jun 10, 2025Most research efforts in the multimedia forensics domain have focused on detecting forgery audio-visual content and reached sound achievements. However, these works only consider deepfake detection as a classification task and ignore the case where partial segments of the video are tampered with. Temporal forgery localization (TFL) of small fake audio-visual clips embedded in real videos is still challenging and more in line with realistic application scenarios. To resolve this issue, we propose a universal context-aware contrastive learning framework (UniCaCLF) for TFL. Our approach leverages supervised contrastive learning to discover and identify forged instants by means of anomaly detection, allowing for the precise localization of temporal forged segments. To this end, we propose a novel context-aware perception layer that utilizes a heterogeneous activation operation and an adaptive context updater to construct a context-aware contrastive objective, which enhances the discriminability of forged instant features by contrasting them with genuine instant features in terms of their distances to the global context. An efficient context-aware contrastive coding is introduced to further push the limit of instant feature distinguishability between genuine and forged instants in a supervised sample-by-sample manner, suppressing the cross-sample influence to improve temporal forgery localization performance. Extensive experimental results over five public datasets demonstrate that our proposed UniCaCLF significantly outperforms the state-of-the-art competing algorithms.
Detecting Localized Deepfake Manipulations Using Action Unit-Guided Video Representations
Mar 28, 2025With rapid advancements in generative modeling, deepfake techniques are increasingly narrowing the gap between real and synthetic videos, raising serious privacy and security concerns. Beyond traditional face swapping and reenactment, an emerging trend in recent state-of-the-art deepfake generation methods involves localized edits such as subtle manipulations of specific facial features like raising eyebrows, altering eye shapes, or modifying mouth expressions. These fine-grained manipulations pose a significant challenge for existing detection models, which struggle to capture such localized variations. To the best of our knowledge, this work presents the first detection approach explicitly designed to generalize to localized edits in deepfake videos by leveraging spatiotemporal representations guided by facial action units. Our method leverages a cross-attention-based fusion of representations learned from pretext tasks like random masking and action unit detection, to create an embedding that effectively encodes subtle, localized changes. Comprehensive evaluations across multiple deepfake generation methods demonstrate that our approach, despite being trained solely on the traditional FF+ dataset, sets a new benchmark in detecting recent deepfake-generated videos with fine-grained local edits, achieving a $20\%$ improvement in accuracy over current state-of-the-art detection methods. Additionally, our method delivers competitive performance on standard datasets, highlighting its robustness and generalization across diverse types of local and global forgeries.
GLCF: A Global-Local Multimodal Coherence Analysis Framework for Talking Face Generation Detection
Dec 18, 2024



Talking face generation (TFG) allows for producing lifelike talking videos of any character using only facial images and accompanying text. Abuse of this technology could pose significant risks to society, creating the urgent need for research into corresponding detection methods. However, research in this field has been hindered by the lack of public datasets. In this paper, we construct the first large-scale multi-scenario talking face dataset (MSTF), which contains 22 audio and video forgery techniques, filling the gap of datasets in this field. The dataset covers 11 generation scenarios and more than 20 semantic scenarios, closer to the practical application scenario of TFG. Besides, we also propose a TFG detection framework, which leverages the analysis of both global and local coherence in the multimodal content of TFG videos. Therefore, a region-focused smoothness detection module (RSFDM) and a discrepancy capture-time frame aggregation module (DCTAM) are introduced to evaluate the global temporal coherence of TFG videos, aggregating multi-grained spatial information. Additionally, a visual-audio fusion module (V-AFM) is designed to evaluate audiovisual coherence within a localized temporal perspective. Comprehensive experiments demonstrate the reasonableness and challenges of our datasets, while also indicating the superiority of our proposed method compared to the state-of-the-art deepfake detection approaches.