 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Robust DeepFake Detection under Unstable Face Sequences: Adaptive Sparse Graph Embedding with Order-Free Representation and Explicit Laplacian Spectral Prior
Dec 08, 2025Ensuring the authenticity of video content remains challenging as DeepFake generation becomes increasingly realistic and robust against detection. Most existing detectors implicitly assume temporally consistent and clean facial sequences, an assumption that rarely holds in real-world scenarios where compression artifacts, occlusions, and adversarial attacks destabilize face detection and often lead to invalid or misdetected faces. To address these challenges, we propose a Laplacian-Regularized Graph Convolutional Network (LR-GCN) that robustly detects DeepFakes from noisy or unordered face sequences, while being trained only on clean facial data. Our method constructs an Order-Free Temporal Graph Embedding (OF-TGE) that organizes frame-wise CNN features into an adaptive sparse graph based on semantic affinities. Unlike traditional methods constrained by strict temporal continuity, OF-TGE captures intrinsic feature consistency across frames, making it resilient to shuffled, missing, or heavily corrupted inputs. We further impose a dual-level sparsity mechanism on both graph structure and node features to suppress the influence of invalid faces. Crucially, we introduce an explicit Graph Laplacian Spectral Prior that acts as a high-pass operator in the graph spectral domain, highlighting structural anomalies and forgery artifacts, which are then consolidated by a low-pass GCN aggregation. This sequential design effectively realizes a task-driven spectral band-pass mechanism that suppresses background information and random noise while preserving manipulation cues. Extensive experiments on FF++, Celeb-DFv2, and DFDC demonstrate that LR-GCN achieves state-of-the-art performance and significantly improved robustness under severe global and local disruptions, including missing faces, occlusions, and adversarially perturbed face detections.
GRACE: Graph-Regularized Attentive Convolutional Entanglement with Laplacian Smoothing for Robust DeepFake Video Detection
Jun 28, 2024As DeepFake video manipulation techniques escalate, posing profound threats, the urgent need to develop efficient detection strategies is underscored. However, one particular issue lies with facial images being mis-detected, often originating from degraded videos or adversarial attacks, leading to unexpected temporal artifacts that can undermine the efficacy of DeepFake video detection techniques. This paper introduces a novel method for robust DeepFake video detection, harnessing the power of the proposed Graph-Regularized Attentive Convolutional Entanglement (GRACE) based on the graph convolutional network with graph Laplacian to address the aforementioned challenges. First, conventional Convolution Neural Networks are deployed to perform spatiotemporal features for the entire video. Then, the spatial and temporal features are mutually entangled by constructing a graph with sparse constraint, enforcing essential features of valid face images in the noisy face sequences remaining, thus augmenting stability and performance for DeepFake video detection. Furthermore, the Graph Laplacian prior is proposed in the graph convolutional network to remove the noise pattern in the feature space to further improve the performance. Comprehensive experiments are conducted to illustrate that our proposed method delivers state-of-the-art performance in DeepFake video detection under noisy face sequences. The source code is available at https://github.com/ming053l/GRACE.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.
DRCT: Saving Image Super-resolution away from Information Bottleneck
Apr 15, 2024In recent years, Vision Transformer-based approaches for low-level vision tasks have achieved widespread success. Unlike CNN-based models, Transformers are more adept at capturing long-range dependencies, enabling the reconstruction of images utilizing non-local information. In the domain of super-resolution, Swin-transformer-based models have become mainstream due to their capability of global spatial information modeling and their shifting-window attention mechanism that facilitates the interchange of information between different windows. Many researchers have enhanced model performance by expanding the receptive fields or designing meticulous networks, yielding commendable results. However, we observed that it is a general phenomenon for the feature map intensity to be abruptly suppressed to small values towards the network's end. This implies an information bottleneck and a diminishment of spatial information, implicitly limiting the model's potential. To address this, we propose the Dense-residual-connected Transformer (DRCT), aimed at mitigating the loss of spatial information and stabilizing the information flow through dense-residual connections between layers, thereby unleashing the model's potential and saving the model away from information bottleneck. Experiment results indicate that our approach surpasses state-of-the-art methods on benchmark datasets and performs commendably at the NTIRE-2024 Image Super-Resolution (x4) Challenge. Our source code is available at https://github.com/ming053l/DRCT
NTIRE 2024 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 15, 2024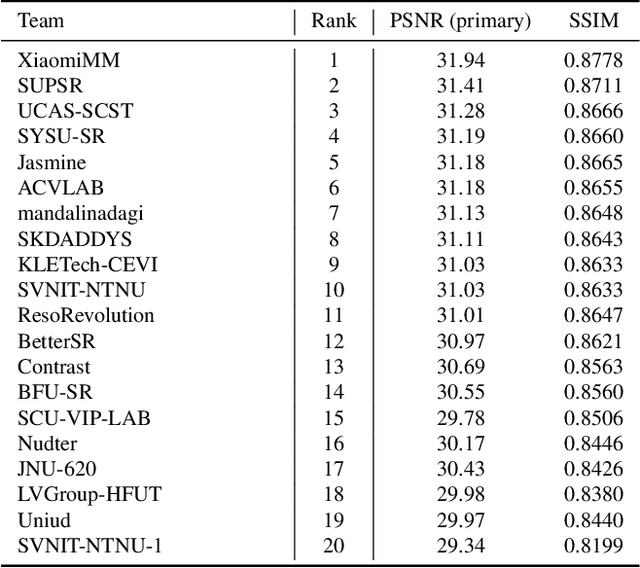
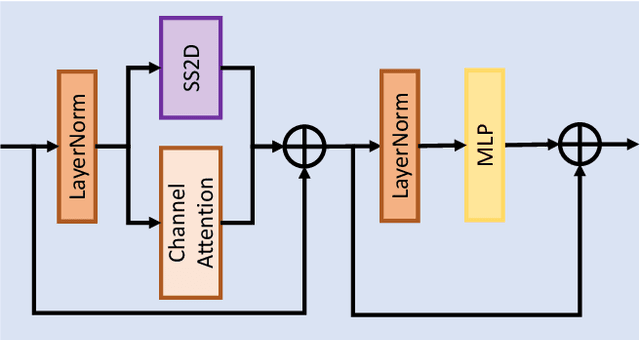
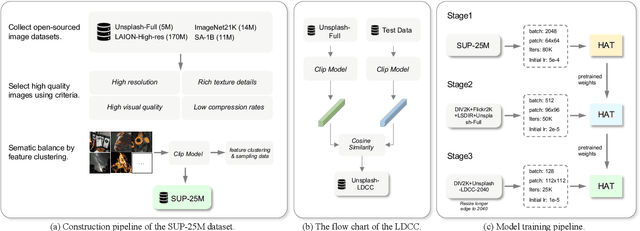
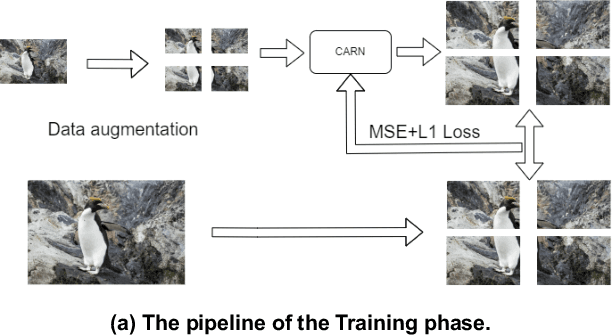
This paper reviews the NTIRE 2024 challenge on image super-resolution ($\times$4), highlighting the solutions proposed and the outcomes obtained. The challenge involves generating corresponding high-resolution (HR) images, magnified by a factor of four, from low-resolution (LR) inputs using prior information. The LR images originate from bicubic downsampling degradation. The aim of the challenge is to obtain designs/solutions with the most advanced SR performance, with no constraints on computational resources (e.g., model size and FLOPs) or training data. The track of this challenge assesses performance with the PSNR metric on the DIV2K testing dataset. The competition attracted 199 registrants, with 20 teams submitting valid entries. This collective endeavour not only pushes the boundaries of performance in single-image SR but also offers a comprehensive overview of current trends in this field.
A Closer Look at Spatial-Slice Features Learning for COVID-19 Detection
Apr 02, 2024



Conventional Computed Tomography (CT) imaging recognition faces two significant challenges: (1) There is often considerable variability in the resolution and size of each CT scan, necessitating strict requirements for the input size and adaptability of models. (2) CT-scan contains large number of out-of-distribution (OOD) slices. The crucial features may only be present in specific spatial regions and slices of the entire CT scan. How can we effectively figure out where these are located? To deal with this, we introduce an enhanced Spatial-Slice Feature Learning (SSFL++) framework specifically designed for CT scan. It aim to filter out a OOD data within whole CT scan, enabling our to select crucial spatial-slice for analysis by reducing 70% redundancy totally. Meanwhile, we proposed Kernel-Density-based slice Sampling (KDS) method to improve the stability when training and inference stage, therefore speeding up the rate of convergence and boosting performance. As a result, the experiments demonstrate the promising performance of our model using a simple EfficientNet-2D (E2D) model, even with only 1% of the training data. The efficacy of our approach has been validated on the COVID-19-CT-DB datasets provided by the DEF-AI-MIA workshop, in conjunction with CVPR 2024. Our source code will be made available.
Simple 2D Convolutional Neural Network-based Approach for COVID-19 Detection
Mar 17, 2024



This study explores the use of deep learning techniques for analyzing lung Computed Tomography (CT) images. Classic deep learning approaches face challenges with varying slice counts and resolutions in CT images, a diversity arising from the utilization of assorted scanning equipment. Typically, predictions are made on single slices which are then combined for a comprehensive outcome. Yet, this method does not incorporate learning features specific to each slice, leading to a compromise in effectiveness. To address these challenges, we propose an advanced Spatial-Slice Feature Learning (SSFL++) framework specifically tailored for CT scans. It aims to filter out out-of-distribution (OOD) data within the entire CT scan, allowing us to select essential spatial-slice features for analysis by reducing data redundancy by 70\%. Additionally, we introduce a Kernel-Density-based slice Sampling (KDS) method to enhance stability during training and inference phases, thereby accelerating convergence and enhancing overall performance. Remarkably, our experiments reveal that our model achieves promising results with a simple EfficientNet-2D (E2D) model. The effectiveness of our approach is confirmed on the COVID-19-CT-DB datasets provided by the DEF-AI-MIA workshop.