 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJpeg Artifact Removal
JPEG artifact removal is the process of reducing compression artifacts in images that result from JPEG compression.
Papers and Code
Deep Image Prior with L0 Gradient Regularizer for Image Smoothing
Jan 19, 2026Image smoothing is a fundamental image processing operation that preserves the underlying structure, such as strong edges and contours, and removes minor details and textures in an image. Many image smoothing algorithms rely on computing local window statistics or solving an optimization problem. Recent state-of-the-art methods leverage deep learning, but they require a carefully curated training dataset. Because constructing a proper training dataset for image smoothing is challenging, we propose DIP-$\ell_0$, a deep image prior framework that incorporates the $\ell_0$ gradient regularizer. This framework can perform high-quality image smoothing without any training data. To properly minimize the associated loss function that has the nonconvex, nonsmooth $\ell_0$ ``norm", we develop an alternating direction method of multipliers algorithm that utilizes an off-the-shelf $\ell_0$ gradient minimization solver. Numerical experiments demonstrate that the proposed DIP-$\ell_0$ outperforms many image smoothing algorithms in edge-preserving image smoothing and JPEG artifact removal.
SODiff: Semantic-Oriented Diffusion Model for JPEG Compression Artifacts Removal
Aug 10, 2025JPEG, as a widely used image compression standard, often introduces severe visual artifacts when achieving high compression ratios. Although existing deep learning-based restoration methods have made considerable progress, they often struggle to recover complex texture details, resulting in over-smoothed outputs. To overcome these limitations, we propose SODiff, a novel and efficient semantic-oriented one-step diffusion model for JPEG artifacts removal. Our core idea is that effective restoration hinges on providing semantic-oriented guidance to the pre-trained diffusion model, thereby fully leveraging its powerful generative prior. To this end, SODiff incorporates a semantic-aligned image prompt extractor (SAIPE). SAIPE extracts rich features from low-quality (LQ) images and projects them into an embedding space semantically aligned with that of the text encoder. Simultaneously, it preserves crucial information for faithful reconstruction. Furthermore, we propose a quality factor-aware time predictor that implicitly learns the compression quality factor (QF) of the LQ image and adaptively selects the optimal denoising start timestep for the diffusion process. Extensive experimental results show that our SODiff outperforms recent leading methods in both visual quality and quantitative metrics. Code is available at: https://github.com/frakenation/SODiff
Diffusion Image Prior
Mar 27, 2025Zero-shot image restoration (IR) methods based on pretrained diffusion models have recently achieved significant success. These methods typically require at least a parametric form of the degradation model. However, in real-world scenarios, the degradation may be too complex to define explicitly. To handle this general case, we introduce the Diffusion Image Prior (DIIP). We take inspiration from the Deep Image Prior (DIP)[16], since it can be used to remove artifacts without the need for an explicit degradation model. However, in contrast to DIP, we find that pretrained diffusion models offer a much stronger prior, despite being trained without knowledge from corrupted data. We show that, the optimization process in DIIP first reconstructs a clean version of the image before eventually overfitting to the degraded input, but it does so for a broader range of degradations than DIP. In light of this result, we propose a blind image restoration (IR) method based on early stopping, which does not require prior knowledge of the degradation model. We validate DIIP on various degradation-blind IR tasks, including JPEG artifact removal, waterdrop removal, denoising and super-resolution with state-of-the-art results.
HPGN: Hybrid Priors-Guided Network for Compressed Low-Light Image Enhancement
Apr 03, 2025In practical applications, conventional methods generate large volumes of low-light images that require compression for efficient storage and transmission. However, most existing methods either disregard the removal of potential compression artifacts during the enhancement process or fail to establish a unified framework for joint task enhancement of images with varying compression qualities. To solve this problem, we propose the hybrid priors-guided network (HPGN), which enhances compressed low-light images by integrating both compression and illumination priors. Our approach fully utilizes the JPEG quality factor (QF) and DCT quantization matrix (QM) to guide the design of efficient joint task plug-and-play modules. Additionally, we employ a random QF generation strategy to guide model training, enabling a single model to enhance images across different compression levels. Experimental results confirm the superiority of our proposed method.
OAPT: Offset-Aware Partition Transformer for Double JPEG Artifacts Removal
Aug 21, 2024



Deep learning-based methods have shown remarkable performance in single JPEG artifacts removal task. However, existing methods tend to degrade on double JPEG images, which are prevalent in real-world scenarios. To address this issue, we propose Offset-Aware Partition Transformer for double JPEG artifacts removal, termed as OAPT. We conduct an analysis of double JPEG compression that results in up to four patterns within each 8x8 block and design our model to cluster the similar patterns to remedy the difficulty of restoration. Our OAPT consists of two components: compression offset predictor and image reconstructor. Specifically, the predictor estimates pixel offsets between the first and second compression, which are then utilized to divide different patterns. The reconstructor is mainly based on several Hybrid Partition Attention Blocks (HPAB), combining vanilla window-based self-attention and sparse attention for clustered pattern features. Extensive experiments demonstrate that OAPT outperforms the state-of-the-art method by more than 0.16dB in double JPEG image restoration task. Moreover, without increasing any computation cost, the pattern clustering module in HPAB can serve as a plugin to enhance other transformer-based image restoration methods. The code will be available at https://github.com/QMoQ/OAPT.git .
JDEC: JPEG Decoding via Enhanced Continuous Cosine Coefficients
Apr 03, 2024



We propose a practical approach to JPEG image decoding, utilizing a local implicit neural representation with continuous cosine formulation. The JPEG algorithm significantly quantizes discrete cosine transform (DCT) spectra to achieve a high compression rate, inevitably resulting in quality degradation while encoding an image. We have designed a continuous cosine spectrum estimator to address the quality degradation issue that restores the distorted spectrum. By leveraging local DCT formulations, our network has the privilege to exploit dequantization and upsampling simultaneously. Our proposed model enables decoding compressed images directly across different quality factors using a single pre-trained model without relying on a conventional JPEG decoder. As a result, our proposed network achieves state-of-the-art performance in flexible color image JPEG artifact removal tasks. Our source code is available at https://github.com/WooKyoungHan/JDEC.
Lightweight Adaptive Feature De-drifting for Compressed Image Classification
Jan 03, 2024



JPEG is a widely used compression scheme to efficiently reduce the volume of transmitted images. The artifacts appear among blocks due to the information loss, which not only affects the quality of images but also harms the subsequent high-level tasks in terms of feature drifting. High-level vision models trained on high-quality images will suffer performance degradation when dealing with compressed images, especially on mobile devices. Numerous learning-based JPEG artifact removal methods have been proposed to handle visual artifacts. However, it is not an ideal choice to use these JPEG artifact removal methods as a pre-processing for compressed image classification for the following reasons: 1. These methods are designed for human vision rather than high-level vision models; 2. These methods are not efficient enough to serve as pre-processing on resource-constrained devices. To address these issues, this paper proposes a novel lightweight AFD module to boost the performance of pre-trained image classification models when facing compressed images. First, a FDE-Net is devised to generate the spatial-wise FDM in the DCT domain. Next, the estimated FDM is transmitted to the FE-Net to generate the mapping relationship between degraded features and corresponding high-quality features. A simple but effective RepConv block equipped with structural re-parameterization is utilized in FE-Net, which enriches feature representation in the training phase while maintaining efficiency in the deployment phase. After training on limited compressed images, the AFD-Module can serve as a "plug-and-play" model for pre-trained classification models to improve their performance on compressed images. Experiments demonstrate that our proposed AFD module can comprehensively improve the accuracy of the pre-trained classification models and significantly outperform the existing methods.
JPEG Quantized Coefficient Recovery via DCT Domain Spatial-Frequential Transformer
Aug 17, 2023JPEG compression adopts the quantization of Discrete Cosine Transform (DCT) coefficients for effective bit-rate reduction, whilst the quantization could lead to a significant loss of important image details. Recovering compressed JPEG images in the frequency domain has attracted more and more attention recently, in addition to numerous restoration approaches developed in the pixel domain. However, the current DCT domain methods typically suffer from limited effectiveness in handling a wide range of compression quality factors, or fall short in recovering sparse quantized coefficients and the components across different colorspace. To address these challenges, we propose a DCT domain spatial-frequential Transformer, named as DCTransformer. Specifically, a dual-branch architecture is designed to capture both spatial and frequential correlations within the collocated DCT coefficients. Moreover, we incorporate the operation of quantization matrix embedding, which effectively allows our single model to handle a wide range of quality factors, and a luminance-chrominance alignment head that produces a unified feature map to align different-sized luminance and chrominance components. Our proposed DCTransformer outperforms the current state-of-the-art JPEG artifact removal techniques, as demonstrated by our extensive experiments.
Restore Anything Pipeline: Segment Anything Meets Image Restoration
May 22, 2023
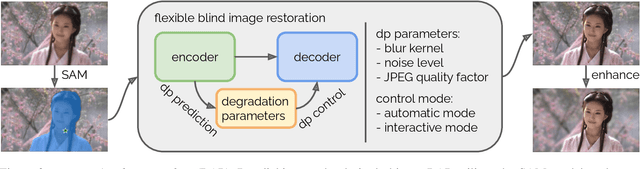


Recent image restoration methods have produced significant advancements using deep learning. However, existing methods tend to treat the whole image as a single entity, failing to account for the distinct objects in the image that exhibit individual texture properties. Existing methods also typically generate a single result, which may not suit the preferences of different users. In this paper, we introduce the Restore Anything Pipeline (RAP), a novel interactive and per-object level image restoration approach that incorporates a controllable model to generate different results that users may choose from. RAP incorporates image segmentation through the recent Segment Anything Model (SAM) into a controllable image restoration model to create a user-friendly pipeline for several image restoration tasks. We demonstrate the versatility of RAP by applying it to three common image restoration tasks: image deblurring, image denoising, and JPEG artifact removal. Our experiments show that RAP produces superior visual results compared to state-of-the-art methods. RAP represents a promising direction for image restoration, providing users with greater control, and enabling image restoration at an object level.
Learning Parallax Transformer Network for Stereo Image JPEG Artifacts Removal
Jul 15, 2022
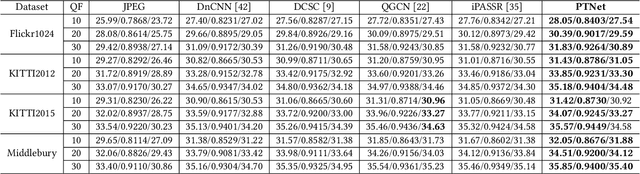
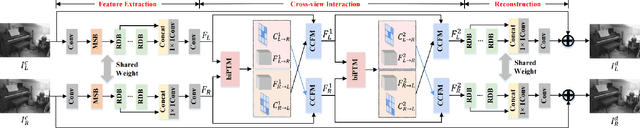
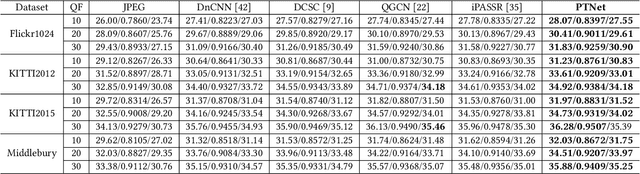
Under stereo settings, the performance of image JPEG artifacts removal can be further improved by exploiting the additional information provided by a second view. However, incorporating this information for stereo image JPEG artifacts removal is a huge challenge, since the existing compression artifacts make pixel-level view alignment difficult. In this paper, we propose a novel parallax transformer network (PTNet) to integrate the information from stereo image pairs for stereo image JPEG artifacts removal. Specifically, a well-designed symmetric bi-directional parallax transformer module is proposed to match features with similar textures between different views instead of pixel-level view alignment. Due to the issues of occlusions and boundaries, a confidence-based cross-view fusion module is proposed to achieve better feature fusion for both views, where the cross-view features are weighted with confidence maps. Especially, we adopt a coarse-to-fine design for the cross-view interaction, leading to better performance. Comprehensive experimental results demonstrate that our PTNet can effectively remove compression artifacts and achieves superior performance than other testing state-of-the-art methods.