 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Detr
Papers and Code
DExTeR: Weakly Semi-Supervised Object Detection with Class and Instance Experts for Medical Imaging
Jan 20, 2026Detecting anatomical landmarks in medical imaging is essential for diagnosis and intervention guidance. However, object detection models rely on costly bounding box annotations, limiting scalability. Weakly Semi-Supervised Object Detection (WSSOD) with point annotations proposes annotating each instance with a single point, minimizing annotation time while preserving localization signals. A Point-to-Box teacher model, trained on a small box-labeled subset, converts these point annotations into pseudo-box labels to train a student detector. Yet, medical imagery presents unique challenges, including overlapping anatomy, variable object sizes, and elusive structures, which hinder accurate bounding box inference. To overcome these challenges, we introduce DExTeR (DETR with Experts), a transformer-based Point-to-Box regressor tailored for medical imaging. Built upon Point-DETR, DExTeR encodes single-point annotations as object queries, refining feature extraction with the proposed class-guided deformable attention, which guides attention sampling using point coordinates and class labels to capture class-specific characteristics. To improve discrimination in complex structures, it introduces CLICK-MoE (CLass, Instance, and Common Knowledge Mixture of Experts), decoupling class and instance representations to reduce confusion among adjacent or overlapping instances. Finally, we implement a multi-point training strategy which promotes prediction consistency across different point placements, improving robustness to annotation variability. DExTeR achieves state-of-the-art performance across three datasets spanning different medical domains (endoscopy, chest X-rays, and endoscopic ultrasound) highlighting its potential to reduce annotation costs while maintaining high detection accuracy.
Nodule-DETR: A Novel DETR Architecture with Frequency-Channel Attention for Ultrasound Thyroid Nodule Detection
Jan 05, 2026Thyroid cancer is the most common endocrine malignancy, and its incidence is rising globally. While ultrasound is the preferred imaging modality for detecting thyroid nodules, its diagnostic accuracy is often limited by challenges such as low image contrast and blurred nodule boundaries. To address these issues, we propose Nodule-DETR, a novel detection transformer (DETR) architecture designed for robust thyroid nodule detection in ultrasound images. Nodule-DETR introduces three key innovations: a Multi-Spectral Frequency-domain Channel Attention (MSFCA) module that leverages frequency analysis to enhance features of low-contrast nodules; a Hierarchical Feature Fusion (HFF) module for efficient multi-scale integration; and Multi-Scale Deformable Attention (MSDA) to flexibly capture small and irregularly shaped nodules. We conducted extensive experiments on a clinical dataset of real-world thyroid ultrasound images. The results demonstrate that Nodule-DETR achieves state-of-the-art performance, outperforming the baseline model by a significant margin of 0.149 in mAP@0.5:0.95. The superior accuracy of Nodule-DETR highlights its significant potential for clinical application as an effective tool in computer-aided thyroid diagnosis. The code of work is available at https://github.com/wjj1wjj/Nodule-DETR.
Prior-Guided DETR for Ultrasound Nodule Detection
Jan 05, 2026Accurate detection of ultrasound nodules is essential for the early diagnosis and treatment of thyroid and breast cancers. However, this task remains challenging due to irregular nodule shapes, indistinct boundaries, substantial scale variations, and the presence of speckle noise that degrades structural visibility. To address these challenges, we propose a prior-guided DETR framework specifically designed for ultrasound nodule detection. Instead of relying on purely data-driven feature learning, the proposed framework progressively incorporates different prior knowledge at multiple stages of the network. First, a Spatially-adaptive Deformable FFN with Prior Regularization (SDFPR) is embedded into the CNN backbone to inject geometric priors into deformable sampling, stabilizing feature extraction for irregular and blurred nodules. Second, a Multi-scale Spatial-Frequency Feature Mixer (MSFFM) is designed to extract multi-scale structural priors, where spatial-domain processing emphasizes contour continuity and boundary cues, while frequency-domain modeling captures global morphology and suppresses speckle noise. Furthermore, a Dense Feature Interaction (DFI) mechanism propagates and exploits these prior-modulated features across all encoder layers, enabling the decoder to enhance query refinement under consistent geometric and structural guidance. Experiments conducted on two clinically collected thyroid ultrasound datasets (Thyroid I and Thyroid II) and two public benchmarks (TN3K and BUSI) for thyroid and breast nodules demonstrate that the proposed method achieves superior accuracy compared with 18 detection methods, particularly in detecting morphologically complex nodules.The source code is publicly available at https://github.com/wjj1wjj/Ultrasound-DETR.
TCLeaf-Net: a transformer-convolution framework with global-local attention for robust in-field lesion-level plant leaf disease detection
Dec 13, 2025Timely and accurate detection of foliar diseases is vital for safeguarding crop growth and reducing yield losses. Yet, in real-field conditions, cluttered backgrounds, domain shifts, and limited lesion-level datasets hinder robust modeling. To address these challenges, we release Daylily-Leaf, a paired lesion-level dataset comprising 1,746 RGB images and 7,839 lesions captured under both ideal and in-field conditions, and propose TCLeaf-Net, a transformer-convolution hybrid detector optimized for real-field use. TCLeaf-Net is designed to tackle three major challenges. To mitigate interference from complex backgrounds, the transformer-convolution module (TCM) couples global context with locality-preserving convolution to suppress non-leaf regions. To reduce information loss during downsampling, the raw-scale feature recalling and sampling (RSFRS) block combines bilinear resampling and convolution to preserve fine spatial detail. To handle variations in lesion scale and feature shifts, the deformable alignment block with FPN (DFPN) employs offset-based alignment and multi-receptive-field perception to strengthen multi-scale fusion. Experimental results show that on the in-field split of the Daylily-Leaf dataset, TCLeaf-Net improves mAP@50 by 5.4 percentage points over the baseline model, reaching 78.2\%, while reducing computation by 7.5 GFLOPs and GPU memory usage by 8.7\%. Moreover, the model outperforms recent YOLO and RT-DETR series in both precision and recall, and demonstrates strong performance on the PlantDoc, Tomato-Leaf, and Rice-Leaf datasets, validating its robustness and generalizability to other plant disease detection scenarios.
QUILL: An Algorithm-Architecture Co-Design for Cache-Local Deformable Attention
Nov 17, 2025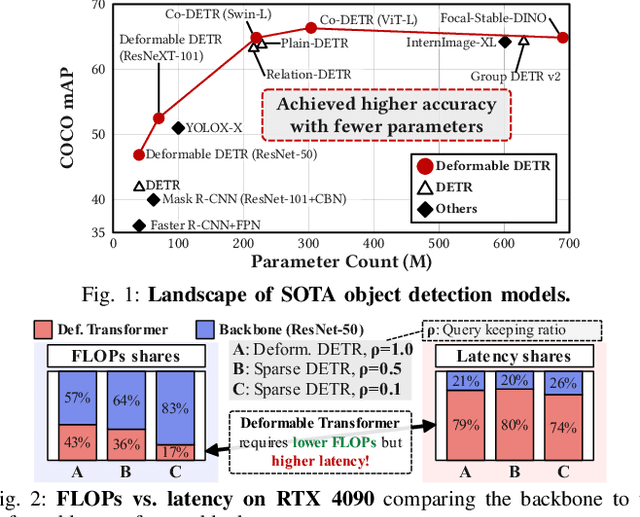
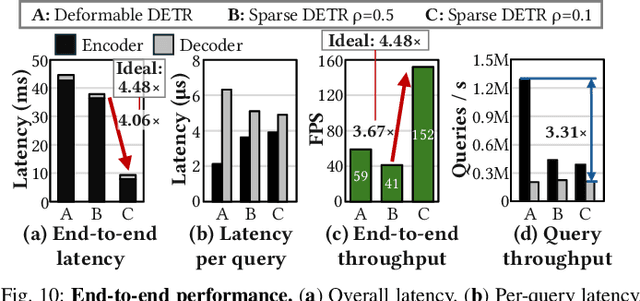
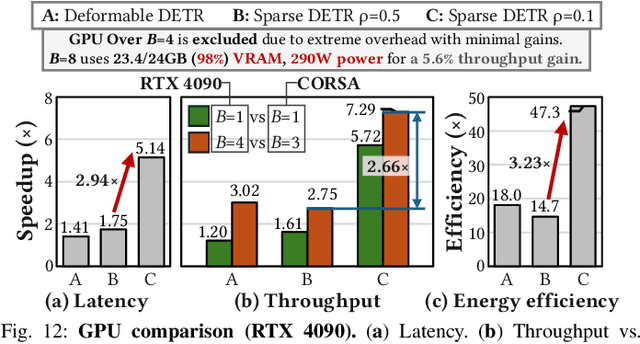
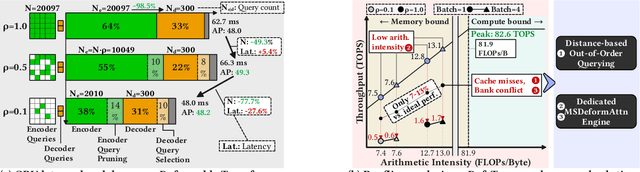
Deformable transformers deliver state-of-the-art detection but map poorly to hardware due to irregular memory access and low arithmetic intensity. We introduce QUILL, a schedule-aware accelerator that turns deformable attention into cache-friendly, single-pass work. At its core, Distance-based Out-of-Order Querying (DOOQ) orders queries by spatial proximity; the look-ahead drives a region prefetch into an alternate buffer--forming a schedule-aware prefetch loop that overlaps memory and compute. A fused MSDeformAttn engine executes interpolation, Softmax, aggregation, and the final projection (W''m) in one pass without spilling intermediates, while small tensors are kept on-chip and surrounding dense layers run on integrated GEMMs. Implemented as RTL and evaluated end-to-end, QUILL achieves up to 7.29x higher throughput and 47.3x better energy efficiency than an RTX 4090, and exceeds prior accelerators by 3.26-9.82x in throughput and 2.01-6.07x in energy efficiency. With mixed-precision quantization, accuracy tracks FP32 within <=0.9 AP across Deformable and Sparse DETR variants. By converting sparsity into locality--and locality into utilization--QUILL delivers consistent, end-to-end speedups.
On Modality Incomplete Infrared-Visible Object Detection: An Architecture Compatibility Perspective
Nov 09, 2025Infrared and visible object detection (IVOD) is essential for numerous around-the-clock applications. Despite notable advancements, current IVOD models exhibit notable performance declines when confronted with incomplete modality data, particularly if the dominant modality is missing. In this paper, we take a thorough investigation on modality incomplete IVOD problem from an architecture compatibility perspective. Specifically, we propose a plug-and-play Scarf Neck module for DETR variants, which introduces a modality-agnostic deformable attention mechanism to enable the IVOD detector to flexibly adapt to any single or double modalities during training and inference. When training Scarf-DETR, we design a pseudo modality dropout strategy to fully utilize the multi-modality information, making the detector compatible and robust to both working modes of single and double modalities. Moreover, we introduce a comprehensive benchmark for the modality-incomplete IVOD task aimed at thoroughly assessing situations where the absent modality is either dominant or secondary. Our proposed Scarf-DETR not only performs excellently in missing modality scenarios but also achieves superior performances on the standard IVOD modality complete benchmarks. Our code will be available at https://github.com/YinghuiXing/Scarf-DETR.
FlowDet: Overcoming Perspective and Scale Challenges in Real-Time End-to-End Traffic Detection
Aug 27, 2025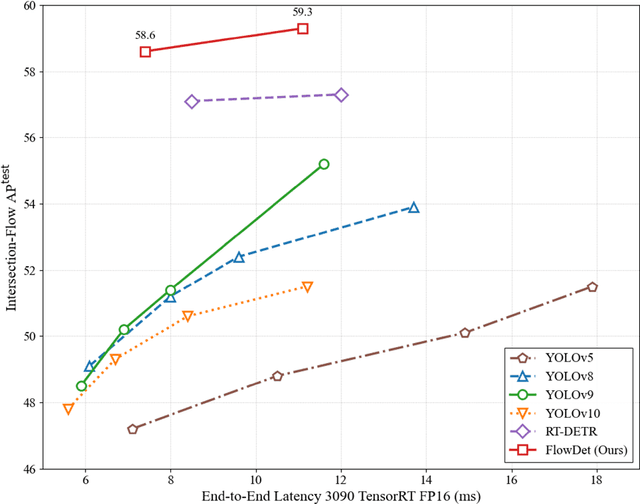
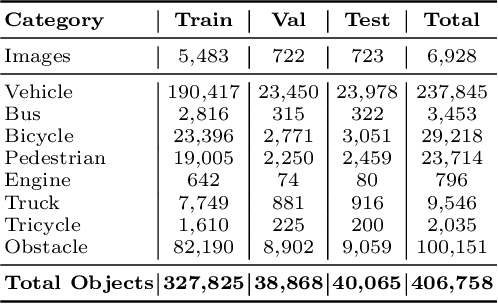
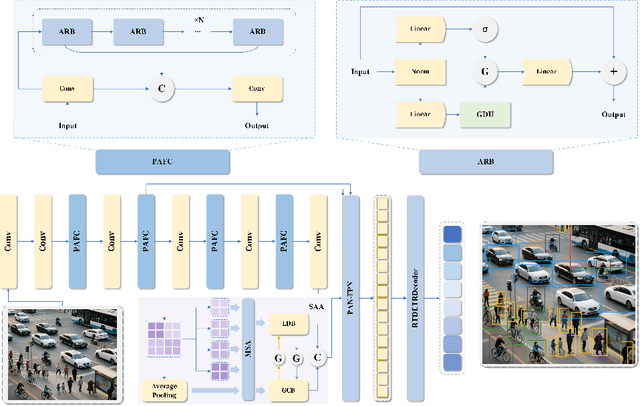
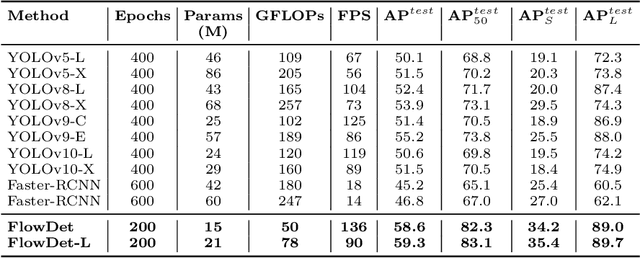
End-to-end object detectors offer a promising NMS-free paradigm for real-time applications, yet their high computational cost remains a significant barrier, particularly for complex scenarios like intersection traffic monitoring. To address this challenge, we propose FlowDet, a high-speed detector featuring a decoupled encoder optimization strategy applied to the DETR architecture. Specifically, FlowDet employs a novel Geometric Deformable Unit (GDU) for traffic-aware geometric modeling and a Scale-Aware Attention (SAA) module to maintain high representational power across extreme scale variations. To rigorously evaluate the model's performance in environments with severe occlusion and high object density, we collected the Intersection-Flow-5k dataset, a new challenging scene for this task. Evaluated on Intersection-Flow-5k, FlowDet establishes a new state-of-the-art. Compared to the strong RT-DETR baseline, it improves AP(test) by 1.5% and AP50(test) by 1.6%, while simultaneously reducing GFLOPs by 63.2% and increasing inference speed by 16.2%. Our work demonstrates a new path towards building highly efficient and accurate detectors for demanding, real-world perception systems. The Intersection-Flow-5k dataset is available at https://github.com/AstronZh/Intersection-Flow-5K.
OD-VIRAT: A Large-Scale Benchmark for Object Detection in Realistic Surveillance Environments
Jul 16, 2025Realistic human surveillance datasets are crucial for training and evaluating computer vision models under real-world conditions, facilitating the development of robust algorithms for human and human-interacting object detection in complex environments. These datasets need to offer diverse and challenging data to enable a comprehensive assessment of model performance and the creation of more reliable surveillance systems for public safety. To this end, we present two visual object detection benchmarks named OD-VIRAT Large and OD-VIRAT Tiny, aiming at advancing visual understanding tasks in surveillance imagery. The video sequences in both benchmarks cover 10 different scenes of human surveillance recorded from significant height and distance. The proposed benchmarks offer rich annotations of bounding boxes and categories, where OD-VIRAT Large has 8.7 million annotated instances in 599,996 images and OD-VIRAT Tiny has 288,901 annotated instances in 19,860 images. This work also focuses on benchmarking state-of-the-art object detection architectures, including RETMDET, YOLOX, RetinaNet, DETR, and Deformable-DETR on this object detection-specific variant of VIRAT dataset. To the best of our knowledge, it is the first work to examine the performance of these recently published state-of-the-art object detection architectures on realistic surveillance imagery under challenging conditions such as complex backgrounds, occluded objects, and small-scale objects. The proposed benchmarking and experimental settings will help in providing insights concerning the performance of selected object detection models and set the base for developing more efficient and robust object detection architectures.
Deformable Attention Mechanisms Applied to Object Detection, case of Remote Sensing
May 30, 2025Object detection has recently seen an interesting trend in terms of the most innovative research work, this task being of particular importance in the field of remote sensing, given the consistency of these images in terms of geographical coverage and the objects present. Furthermore, Deep Learning (DL) models, in particular those based on Transformers, are especially relevant for visual computing tasks in general, and target detection in particular. Thus, the present work proposes an application of Deformable-DETR model, a specific architecture using deformable attention mechanisms, on remote sensing images in two different modes, especially optical and Synthetic Aperture Radar (SAR). To achieve this objective, two datasets are used, one optical, which is Pleiades Aircraft dataset, and the other SAR, in particular SAR Ship Detection Dataset (SSDD). The results of a 10-fold stratified validation showed that the proposed model performed particularly well, obtaining an F1 score of 95.12% for the optical dataset and 94.54% for SSDD, while comparing these results with several models detections, especially those based on CNNs and transformers, as well as those specifically designed to detect different object classes in remote sensing images.
* 10 pages, 5 figures, paper accepted at the 29th International Conference on Knowledge-Based and Intelligent Information and Engineering Systems (KES 2025), Osaka, Japan
Fractional Correspondence Framework in Detection Transformer
Mar 06, 2025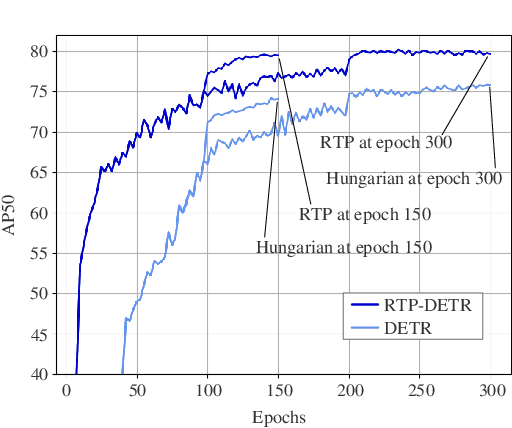
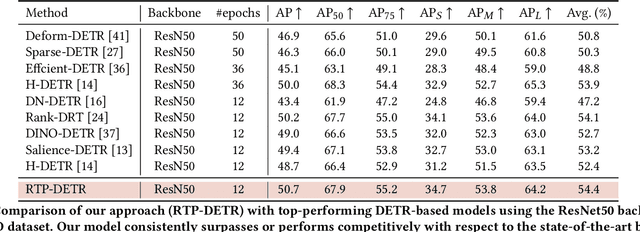
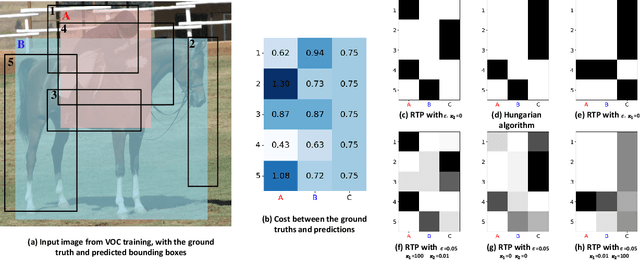
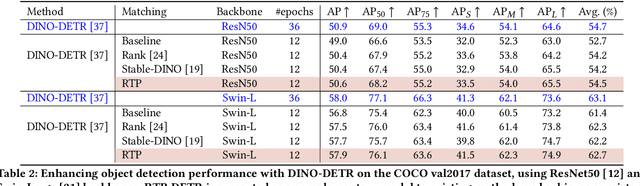
The Detection Transformer (DETR), by incorporating the Hungarian algorithm, has significantly simplified the matching process in object detection tasks. This algorithm facilitates optimal one-to-one matching of predicted bounding boxes to ground-truth annotations during training. While effective, this strict matching process does not inherently account for the varying densities and distributions of objects, leading to suboptimal correspondences such as failing to handle multiple detections of the same object or missing small objects. To address this, we propose the Regularized Transport Plan (RTP). RTP introduces a flexible matching strategy that captures the cost of aligning predictions with ground truths to find the most accurate correspondences between these sets. By utilizing the differentiable Sinkhorn algorithm, RTP allows for soft, fractional matching rather than strict one-to-one assignments. This approach enhances the model's capability to manage varying object densities and distributions effectively. Our extensive evaluations on the MS-COCO and VOC benchmarks demonstrate the effectiveness of our approach. RTP-DETR, surpassing the performance of the Deform-DETR and the recently introduced DINO-DETR, achieving absolute gains in mAP of +3.8% and +1.7%, respectively.