 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Optimal Token Baseline: Variance Reduction for Long-Horizon LLM-RL
Feb 06, 2026Reinforcement Learning (RL) for Large Language Models (LLMs) often suffers from training collapse in long-horizon tasks due to exploding gradient variance. To mitigate this, a baseline is commonly introduced for advantage computation; however, traditional value models remain difficult to optimize, and standard group-based baselines overlook sequence heterogeneity. Although classic optimal baseline theory can achieve global variance reduction, it neglects token heterogeneity and requires prohibitive gradient-based computation. In this work, we derive the Optimal Token Baseline (OTB) from first principles, proving that gradient updates should be weighted inversely to their cumulative gradient norm. To ensure efficiency, we propose the Logit-Gradient Proxy that approximates the gradient norm using only forward-pass probabilities. Our method achieves training stability and matches the performance of large group sizes ($N=32$) with only $N=4$, reducing token consumption by over 65% across single-turn and tool-integrated reasoning tasks.
Trust Region Masking for Long-Horizon LLM Reinforcement Learning
Dec 28, 2025Policy gradient methods for large language models optimize a surrogate objective computed from samples of a rollout policy $π_{\text{roll}}$. When $π_{\text{roll}} \ne π_θ$, there is approximation error between the surrogate and the true objective. Prior work has shown that this off-policy mismatch is unavoidable in modern LLM-RL due to implementation divergence, mixture-of-experts routing discontinuities, and distributed training staleness. Classical trust region bounds on the resulting error scale as $O(T^2)$ with sequence length $T$, rendering them vacuous for long-horizon tasks. We derive two tighter bounds: a Pinsker-Marginal bound scaling as $O(T^{3/2})$ and a Mixed bound scaling as $O(T)$. Crucially, both bounds depend on $D_{kl}^{tok,max}$ -- the maximum token-level KL divergence across all positions in a sequence. This is inherently a sequence-level quantity: it requires examining the entire trajectory to compute, and therefore cannot be controlled by token-independent methods like PPO clipping. We propose Trust Region Masking (TRM), which excludes entire sequences from gradient computation if any token violates the trust region, providing the first non-vacuous monotonic improvement guarantees for long-horizon LLM-RL.
Taming the Tail: Stable LLM Reinforcement Learning via Dynamic Vocabulary Pruning
Dec 28, 2025Reinforcement learning for large language models (LLMs) faces a fundamental tension: high-throughput inference engines and numerically-precise training systems produce different probability distributions from the same parameters, creating a training-inference mismatch. We prove this mismatch has an asymmetric effect: the bound on log-probability mismatch scales as $(1-p)$ where $p$ is the token probability. For high-probability tokens, this bound vanishes, contributing negligibly to sequence-level mismatch. For low-probability tokens in the tail, the bound remains large, and moreover, when sampled, these tokens exhibit systematically biased mismatches that accumulate over sequences, destabilizing gradient estimation. Rather than applying post-hoc corrections, we propose constraining the RL objective to a dynamically-pruned ``safe'' vocabulary that excludes the extreme tail. By pruning such tokens, we trade large, systematically biased mismatches for a small, bounded optimization bias. Empirically, our method achieves stable training; theoretically, we bound the optimization bias introduced by vocabulary pruning.
Laminar: A Scalable Asynchronous RL Post-Training Framework
Oct 14, 2025Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Mar 18, 2025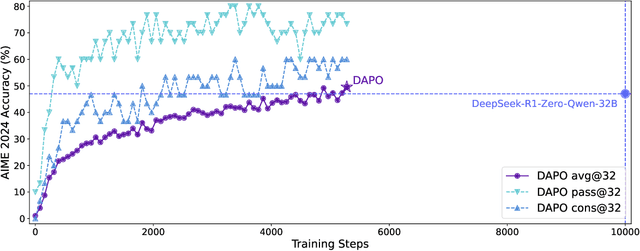

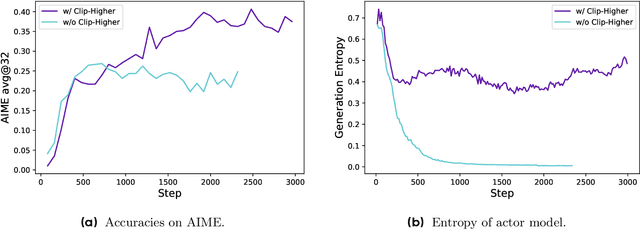

Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.
Demystifying Long Chain-of-Thought Reasoning in LLMs
Feb 05, 2025



Scaling inference compute enhances reasoning in large language models (LLMs), with long chains-of-thought (CoTs) enabling strategies like backtracking and error correction. Reinforcement learning (RL) has emerged as a crucial method for developing these capabilities, yet the conditions under which long CoTs emerge remain unclear, and RL training requires careful design choices. In this study, we systematically investigate the mechanics of long CoT reasoning, identifying the key factors that enable models to generate long CoT trajectories. Through extensive supervised fine-tuning (SFT) and RL experiments, we present four main findings: (1) While SFT is not strictly necessary, it simplifies training and improves efficiency; (2) Reasoning capabilities tend to emerge with increased training compute, but their development is not guaranteed, making reward shaping crucial for stabilizing CoT length growth; (3) Scaling verifiable reward signals is critical for RL. We find that leveraging noisy, web-extracted solutions with filtering mechanisms shows strong potential, particularly for out-of-distribution (OOD) tasks such as STEM reasoning; and (4) Core abilities like error correction are inherently present in base models, but incentivizing these skills effectively for complex tasks via RL demands significant compute, and measuring their emergence requires a nuanced approach. These insights provide practical guidance for optimizing training strategies to enhance long CoT reasoning in LLMs. Our code is available at: https://github.com/eddycmu/demystify-long-cot.
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
Apr 13, 2023
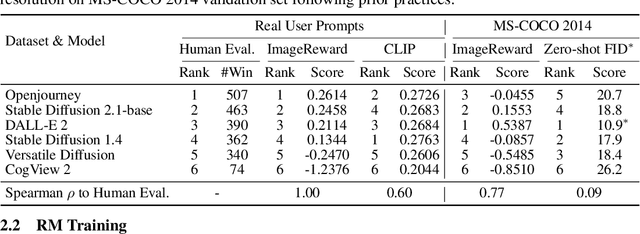
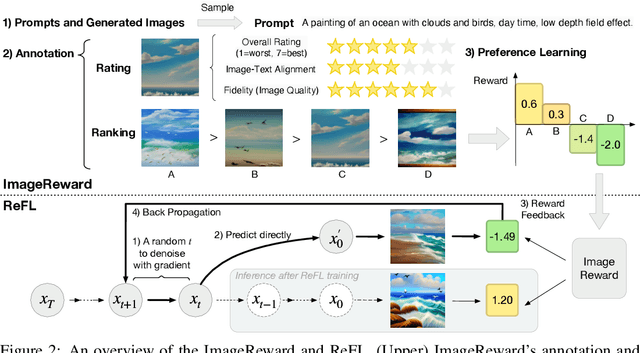

We present ImageReward -- the first general-purpose text-to-image human preference reward model -- to address various prevalent issues in generative models and align them with human values and preferences. Its training is based on our systematic annotation pipeline that covers both the rating and ranking components, collecting a dataset of 137k expert comparisons to date. In human evaluation, ImageReward outperforms existing scoring methods (e.g., CLIP by 38.6\%), making it a promising automatic metric for evaluating and improving text-to-image synthesis. The reward model is publicly available via the \texttt{image-reward} package at \url{https://github.com/THUDM/ImageReward}.