Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
Apr 13, 2023
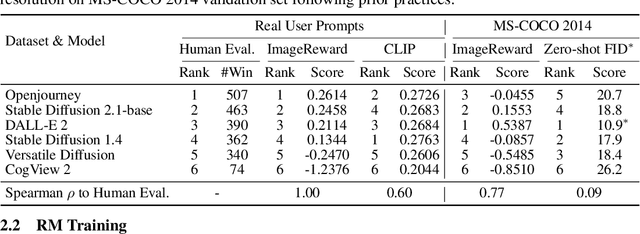
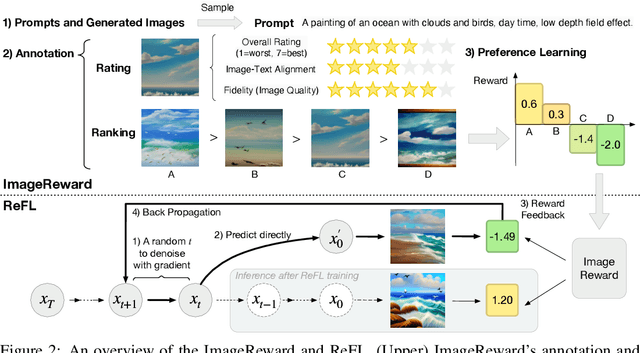

We present ImageReward -- the first general-purpose text-to-image human preference reward model -- to address various prevalent issues in generative models and align them with human values and preferences. Its training is based on our systematic annotation pipeline that covers both the rating and ranking components, collecting a dataset of 137k expert comparisons to date. In human evaluation, ImageReward outperforms existing scoring methods (e.g., CLIP by 38.6\%), making it a promising automatic metric for evaluating and improving text-to-image synthesis. The reward model is publicly available via the \texttt{image-reward} package at \url{https://github.com/THUDM/ImageReward}.
* 24 pages
Via