 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSeDis: A Dataset for Referring-based Object Search across Large-Scale Image Collections
Jun 18, 2025Large-scale visual search engines are expected to solve a dual problem at once: (i) locate every image that truly contains the object described by a sentence and (ii) identify the object's bounding box or exact pixels within each hit. Existing techniques address only one side of this challenge. Visual grounding yields tight boxes and masks but rests on the unrealistic assumption that the object is present in every test image, producing a flood of false alarms when applied to web-scale collections. Text-to-image retrieval excels at sifting through massive databases to rank relevant images, yet it stops at whole-image matches and offers no fine-grained localization. We introduce Referring Search and Discovery (ReSeDis), the first task that unifies corpus-level retrieval with pixel-level grounding. Given a free-form description, a ReSeDis model must decide whether the queried object appears in each image and, if so, where it is, returning bounding boxes or segmentation masks. To enable rigorous study, we curate a benchmark in which every description maps uniquely to object instances scattered across a large, diverse corpus, eliminating unintended matches. We further design a task-specific metric that jointly scores retrieval recall and localization precision. Finally, we provide a straightforward zero-shot baseline using a frozen vision-language model, revealing significant headroom for future study. ReSeDis offers a realistic, end-to-end testbed for building the next generation of robust and scalable multimodal search systems.
Foundation Model Insights and a Multi-Model Approach for Superior Fine-Grained One-shot Subset Selection
Jun 17, 2025



One-shot subset selection serves as an effective tool to reduce deep learning training costs by identifying an informative data subset based on the information extracted by an information extractor (IE). Traditional IEs, typically pre-trained on the target dataset, are inherently dataset-dependent. Foundation models (FMs) offer a promising alternative, potentially mitigating this limitation. This work investigates two key questions: (1) Can FM-based subset selection outperform traditional IE-based methods across diverse datasets? (2) Do all FMs perform equally well as IEs for subset selection? Extensive experiments uncovered surprising insights: FMs consistently outperform traditional IEs on fine-grained datasets, whereas their advantage diminishes on coarse-grained datasets with noisy labels. Motivated by these finding, we propose RAM-APL (RAnking Mean-Accuracy of Pseudo-class Labels), a method tailored for fine-grained image datasets. RAM-APL leverages multiple FMs to enhance subset selection by exploiting their complementary strengths. Our approach achieves state-of-the-art performance on fine-grained datasets, including Oxford-IIIT Pet, Food-101, and Caltech-UCSD Birds-200-2011.
A Culturally-diverse Multilingual Multimodal Video Benchmark & Model
Jun 08, 2025Large multimodal models (LMMs) have recently gained attention due to their effectiveness to understand and generate descriptions of visual content. Most existing LMMs are in English language. While few recent works explore multilingual image LMMs, to the best of our knowledge, moving beyond the English language for cultural and linguistic inclusivity is yet to be investigated in the context of video LMMs. In pursuit of more inclusive video LMMs, we introduce a multilingual Video LMM benchmark, named ViMUL-Bench, to evaluate Video LMMs across 14 languages, including both low- and high-resource languages: English, Chinese, Spanish, French, German, Hindi, Arabic, Russian, Bengali, Urdu, Sinhala, Tamil, Swedish, and Japanese. Our ViMUL-Bench is designed to rigorously test video LMMs across 15 categories including eight culturally diverse categories, ranging from lifestyles and festivals to foods and rituals and from local landmarks to prominent cultural personalities. ViMUL-Bench comprises both open-ended (short and long-form) and multiple-choice questions spanning various video durations (short, medium, and long) with 8k samples that are manually verified by native language speakers. In addition, we also introduce a machine translated multilingual video training set comprising 1.2 million samples and develop a simple multilingual video LMM, named ViMUL, that is shown to provide a better tradeoff between high-and low-resource languages for video understanding. We hope our ViMUL-Bench and multilingual video LMM along with a large-scale multilingual video training set will help ease future research in developing cultural and linguistic inclusive multilingual video LMMs. Our proposed benchmark, video LMM and training data will be publicly released at https://mbzuai-oryx.github.io/ViMUL/.
Matting by Generation
Jul 30, 2024


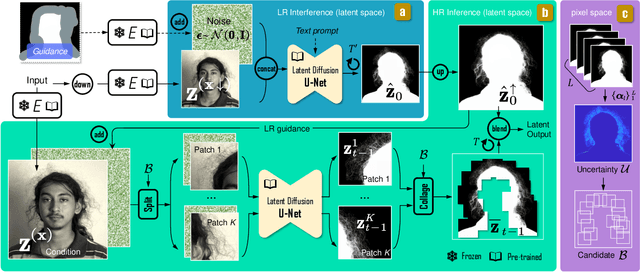
This paper introduces an innovative approach for image matting that redefines the traditional regression-based task as a generative modeling challenge. Our method harnesses the capabilities of latent diffusion models, enriched with extensive pre-trained knowledge, to regularize the matting process. We present novel architectural innovations that empower our model to produce mattes with superior resolution and detail. The proposed method is versatile and can perform both guidance-free and guidance-based image matting, accommodating a variety of additional cues. Our comprehensive evaluation across three benchmark datasets demonstrates the superior performance of our approach, both quantitatively and qualitatively. The results not only reflect our method's robust effectiveness but also highlight its ability to generate visually compelling mattes that approach photorealistic quality. The project page for this paper is available at https://lightchaserx.github.io/matting-by-generation/
The SkatingVerse Workshop & Challenge: Methods and Results
May 27, 2024

The SkatingVerse Workshop & Challenge aims to encourage research in developing novel and accurate methods for human action understanding. The SkatingVerse dataset used for the SkatingVerse Challenge has been publicly released. There are two subsets in the dataset, i.e., the training subset and testing subset. The training subsets consists of 19,993 RGB video sequences, and the testing subsets consists of 8,586 RGB video sequences. Around 10 participating teams from the globe competed in the SkatingVerse Challenge. In this paper, we provide a brief summary of the SkatingVerse Workshop & Challenge including brief introductions to the top three methods. The submission leaderboard will be reopened for researchers that are interested in the human action understanding challenge. The benchmark dataset and other information can be found at: https://skatingverse.github.io/.
TC-OCR: TableCraft OCR for Efficient Detection & Recognition of Table Structure & Content
Apr 19, 2024



The automatic recognition of tabular data in document images presents a significant challenge due to the diverse range of table styles and complex structures. Tables offer valuable content representation, enhancing the predictive capabilities of various systems such as search engines and Knowledge Graphs. Addressing the two main problems, namely table detection (TD) and table structure recognition (TSR), has traditionally been approached independently. In this research, we propose an end-to-end pipeline that integrates deep learning models, including DETR, CascadeTabNet, and PP OCR v2, to achieve comprehensive image-based table recognition. This integrated approach effectively handles diverse table styles, complex structures, and image distortions, resulting in improved accuracy and efficiency compared to existing methods like Table Transformers. Our system achieves simultaneous table detection (TD), table structure recognition (TSR), and table content recognition (TCR), preserving table structures and accurately extracting tabular data from document images. The integration of multiple models addresses the intricacies of table recognition, making our approach a promising solution for image-based table understanding, data extraction, and information retrieval applications. Our proposed approach achieves an IOU of 0.96 and an OCR Accuracy of 78%, showcasing a remarkable improvement of approximately 25% in the OCR Accuracy compared to the previous Table Transformer approach.
RanLayNet: A Dataset for Document Layout Detection used for Domain Adaptation and Generalization
Apr 15, 2024



Large ground-truth datasets and recent advances in deep learning techniques have been useful for layout detection. However, because of the restricted layout diversity of these datasets, training on them requires a sizable number of annotated instances, which is both expensive and time-consuming. As a result, differences between the source and target domains may significantly impact how well these models function. To solve this problem, domain adaptation approaches have been developed that use a small quantity of labeled data to adjust the model to the target domain. In this research, we introduced a synthetic document dataset called RanLayNet, enriched with automatically assigned labels denoting spatial positions, ranges, and types of layout elements. The primary aim of this endeavor is to develop a versatile dataset capable of training models with robustness and adaptability to diverse document formats. Through empirical experimentation, we demonstrate that a deep layout identification model trained on our dataset exhibits enhanced performance compared to a model trained solely on actual documents. Moreover, we conduct a comparative analysis by fine-tuning inference models using both PubLayNet and IIIT-AR-13K datasets on the Doclaynet dataset. Our findings emphasize that models enriched with our dataset are optimal for tasks such as achieving 0.398 and 0.588 mAP95 score in the scientific document domain for the TABLE class.
The Effects of Short Video-Sharing Services on Video Copy Detection
Mar 26, 2024The short video-sharing services that allow users to post 10-30 second videos (e.g., YouTube Shorts and TikTok) have attracted a lot of attention in recent years. However, conventional video copy detection (VCD) methods mainly focus on general video-sharing services (e.g., YouTube and Bilibili), and the effects of short video-sharing services on video copy detection are still unclear. Considering that illegally copied videos in short video-sharing services have service-distinctive characteristics, especially in those time lengths, the pros and cons of VCD in those services are required to be analyzed. In this paper, we examine the effects of short video-sharing services on VCD by constructing a dataset that has short video-sharing service characteristics. Our novel dataset is automatically constructed from the publicly available dataset to have reference videos and fixed short-time-length query videos, and such automation procedures assure the reproducibility and data privacy preservation of this paper. From the experimental results focusing on segment-level and video-level situations, we can see that three effects: "Segment-level VCD in short video-sharing services is more difficult than those in general video-sharing services", "Video-level VCD in short video-sharing services is easier than those in general video-sharing services", "The video alignment component mainly suppress the detection performance in short video-sharing services".
Contributing Dimension Structure of Deep Feature for Coreset Selection
Jan 29, 2024



Coreset selection seeks to choose a subset of crucial training samples for efficient learning. It has gained traction in deep learning, particularly with the surge in training dataset sizes. Sample selection hinges on two main aspects: a sample's representation in enhancing performance and the role of sample diversity in averting overfitting. Existing methods typically measure both the representation and diversity of data based on similarity metrics, such as L2-norm. They have capably tackled representation via distribution matching guided by the similarities of features, gradients, or other information between data. However, the results of effectively diverse sample selection are mired in sub-optimality. This is because the similarity metrics usually simply aggregate dimension similarities without acknowledging disparities among the dimensions that significantly contribute to the final similarity. As a result, they fall short of adequately capturing diversity. To address this, we propose a feature-based diversity constraint, compelling the chosen subset to exhibit maximum diversity. Our key lies in the introduction of a novel Contributing Dimension Structure (CDS) metric. Different from similarity metrics that measure the overall similarity of high-dimensional features, our CDS metric considers not only the reduction of redundancy in feature dimensions, but also the difference between dimensions that contribute significantly to the final similarity. We reveal that existing methods tend to favor samples with similar CDS, leading to a reduced variety of CDS types within the coreset and subsequently hindering model performance. In response, we enhance the performance of five classical selection methods by integrating the CDS constraint. Our experiments on three datasets demonstrate the general effectiveness of the proposed method in boosting existing methods.
Beyond Domain Gap: Exploiting Subjectivity in Sketch-Based Person Retrieval
Sep 15, 2023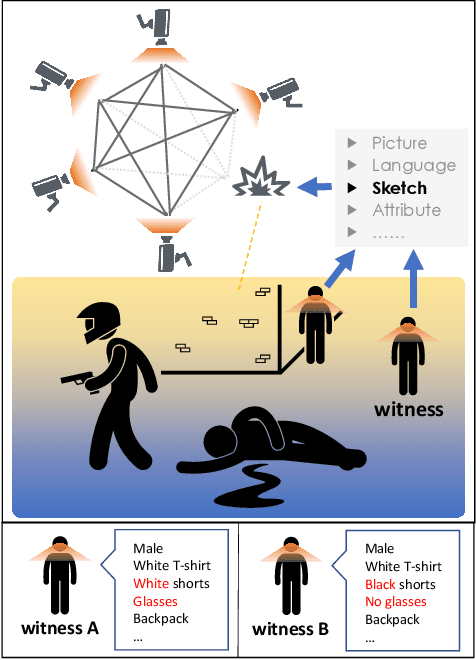

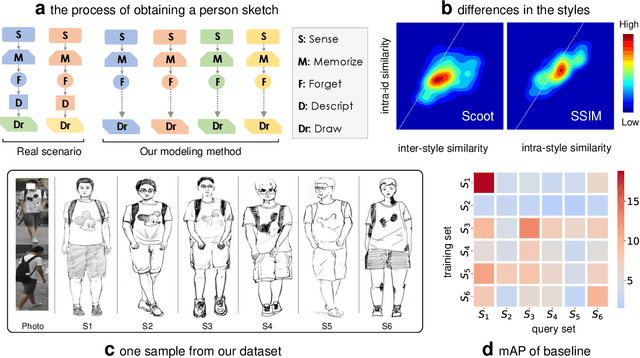
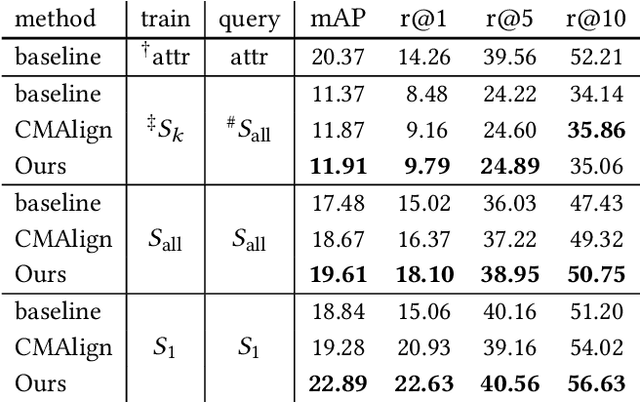
Person re-identification (re-ID) requires densely distributed cameras. In practice, the person of interest may not be captured by cameras and, therefore, needs to be retrieved using subjective information (e.g., sketches from witnesses). Previous research defines this case using the sketch as sketch re-identification (Sketch re-ID) and focuses on eliminating the domain gap. Actually, subjectivity is another significant challenge. We model and investigate it by posing a new dataset with multi-witness descriptions. It features two aspects. 1) Large-scale. It contains over 4,763 sketches and 32,668 photos, making it the largest Sketch re-ID dataset. 2) Multi-perspective and multi-style. Our dataset offers multiple sketches for each identity. Witnesses' subjective cognition provides multiple perspectives on the same individual, while different artists' drawing styles provide variation in sketch styles. We further have two novel designs to alleviate the challenge of subjectivity. 1) Fusing subjectivity. We propose a non-local (NL) fusion module that gathers sketches from different witnesses for the same identity. 2) Introducing objectivity. An AttrAlign module utilizes attributes as an implicit mask to align cross-domain features. To push forward the advance of Sketch re-ID, we set three benchmarks (large-scale, multi-style, cross-style). Extensive experiments demonstrate our leading performance in these benchmarks. Dataset and Codes are publicly available at: https://github.com/Lin-Kayla/subjectivity-sketch-reid