 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Explore in Diverse Reward Settings via Temporal-Difference-Error Maximization
Jun 16, 2025Numerous heuristics and advanced approaches have been proposed for exploration in different settings for deep reinforcement learning. Noise-based exploration generally fares well with dense-shaped rewards and bonus-based exploration with sparse rewards. However, these methods usually require additional tuning to deal with undesirable reward settings by adjusting hyperparameters and noise distributions. Rewards that actively discourage exploration, i.e., with an action cost and no other dense signal to follow, can pose a major challenge. We propose a novel exploration method, Stable Error-seeking Exploration (SEE), that is robust across dense, sparse, and exploration-adverse reward settings. To this endeavor, we revisit the idea of maximizing the TD-error as a separate objective. Our method introduces three design choices to mitigate instability caused by far-off-policy learning, the conflict of interest of maximizing the cumulative TD-error in an episodic setting, and the non-stationary nature of TD-errors. SEE can be combined with off-policy algorithms without modifying the optimization pipeline of the original objective. In our experimental analysis, we show that a Soft-Actor Critic agent with the addition of SEE performs robustly across three diverse reward settings in a variety of tasks without hyperparameter adjustments.
Bridging the Performance Gap Between Target-Free and Target-Based Reinforcement Learning With Iterated Q-Learning
Jun 04, 2025In value-based reinforcement learning, removing the target network is tempting as the boostrapped target would be built from up-to-date estimates, and the spared memory occupied by the target network could be reallocated to expand the capacity of the online network. However, eliminating the target network introduces instability, leading to a decline in performance. Removing the target network also means we cannot leverage the literature developed around target networks. In this work, we propose to use a copy of the last linear layer of the online network as a target network, while sharing the remaining parameters with the up-to-date online network, hence stepping out of the binary choice between target-based and target-free methods. It enables us to leverage the concept of iterated Q-learning, which consists of learning consecutive Bellman iterations in parallel, to reduce the performance gap between target-free and target-based approaches. Our findings demonstrate that this novel method, termed iterated Shared Q-Learning (iS-QL), improves the sample efficiency of target-free approaches across various settings. Importantly, iS-QL requires a smaller memory footprint and comparable training time to classical target-based algorithms, highlighting its potential to scale reinforcement learning research.
Dynamic Obstacle Avoidance with Bounded Rationality Adversarial Reinforcement Learning
Mar 14, 2025Reinforcement Learning (RL) has proven largely effective in obtaining stable locomotion gaits for legged robots. However, designing control algorithms which can robustly navigate unseen environments with obstacles remains an ongoing problem within quadruped locomotion. To tackle this, it is convenient to solve navigation tasks by means of a hierarchical approach with a low-level locomotion policy and a high-level navigation policy. Crucially, the high-level policy needs to be robust to dynamic obstacles along the path of the agent. In this work, we propose a novel way to endow navigation policies with robustness by a training process that models obstacles as adversarial agents, following the adversarial RL paradigm. Importantly, to improve the reliability of the training process, we bound the rationality of the adversarial agent resorting to quantal response equilibria, and place a curriculum over its rationality. We called this method Hierarchical policies via Quantal response Adversarial Reinforcement Learning (Hi-QARL). We demonstrate the robustness of our method by benchmarking it in unseen randomized mazes with multiple obstacles. To prove its applicability in real scenarios, our method is applied on a Unitree GO1 robot in simulation.
Eau De $Q$-Network: Adaptive Distillation of Neural Networks in Deep Reinforcement Learning
Mar 03, 2025Recent works have successfully demonstrated that sparse deep reinforcement learning agents can be competitive against their dense counterparts. This opens up opportunities for reinforcement learning applications in fields where inference time and memory requirements are cost-sensitive or limited by hardware. Until now, dense-to-sparse methods have relied on hand-designed sparsity schedules that are not synchronized with the agent's learning pace. Crucially, the final sparsity level is chosen as a hyperparameter, which requires careful tuning as setting it too high might lead to poor performances. In this work, we address these shortcomings by crafting a dense-to-sparse algorithm that we name Eau De $Q$-Network (EauDeQN). To increase sparsity at the agent's learning pace, we consider multiple online networks with different sparsity levels, where each online network is trained from a shared target network. At each target update, the online network with the smallest loss is chosen as the next target network, while the other networks are replaced by a pruned version of the chosen network. We evaluate the proposed approach on the Atari $2600$ benchmark and the MuJoCo physics simulator, showing that EauDeQN reaches high sparsity levels while keeping performances high.
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
Deterministic Exploration via Stationary Bellman Error Maximization
Oct 31, 2024

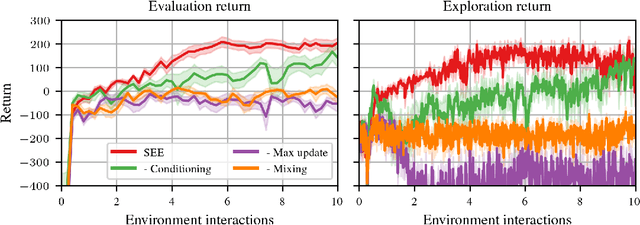
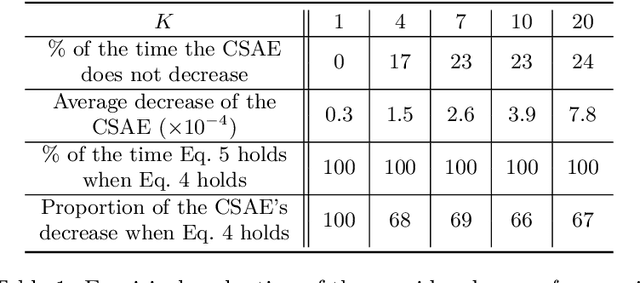
Exploration is a crucial and distinctive aspect of reinforcement learning (RL) that remains a fundamental open problem. Several methods have been proposed to tackle this challenge. Commonly used methods inject random noise directly into the actions, indirectly via entropy maximization, or add intrinsic rewards that encourage the agent to steer to novel regions of the state space. Another previously seen idea is to use the Bellman error as a separate optimization objective for exploration. In this paper, we introduce three modifications to stabilize the latter and arrive at a deterministic exploration policy. Our separate exploration agent is informed about the state of the exploitation, thus enabling it to account for previous experiences. Further components are introduced to make the exploration objective agnostic toward the episode length and to mitigate instability introduced by far-off-policy learning. Our experimental results show that our approach can outperform $\varepsilon$-greedy in dense and sparse reward settings.
Machine Learning with Physics Knowledge for Prediction: A Survey
Aug 19, 2024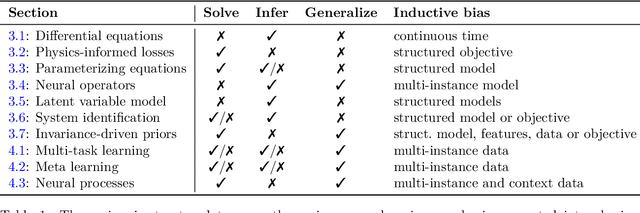
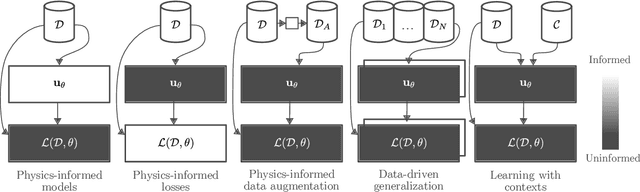
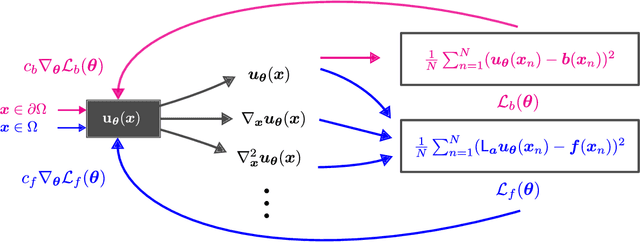
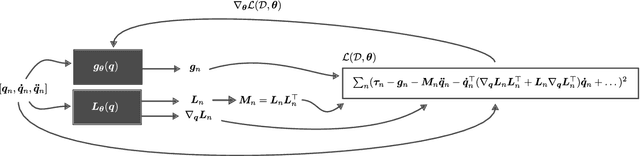
This survey examines the broad suite of methods and models for combining machine learning with physics knowledge for prediction and forecast, with a focus on partial differential equations. These methods have attracted significant interest due to their potential impact on advancing scientific research and industrial practices by improving predictive models with small- or large-scale datasets and expressive predictive models with useful inductive biases. The survey has two parts. The first considers incorporating physics knowledge on an architectural level through objective functions, structured predictive models, and data augmentation. The second considers data as physics knowledge, which motivates looking at multi-task, meta, and contextual learning as an alternative approach to incorporating physics knowledge in a data-driven fashion. Finally, we also provide an industrial perspective on the application of these methods and a survey of the open-source ecosystem for physics-informed machine learning.
Augmented Bayesian Policy Search
Jul 05, 2024



Deterministic policies are often preferred over stochastic ones when implemented on physical systems. They can prevent erratic and harmful behaviors while being easier to implement and interpret. However, in practice, exploration is largely performed by stochastic policies. First-order Bayesian Optimization (BO) methods offer a principled way of performing exploration using deterministic policies. This is done through a learned probabilistic model of the objective function and its gradient. Nonetheless, such approaches treat policy search as a black-box problem, and thus, neglect the reinforcement learning nature of the problem. In this work, we leverage the performance difference lemma to introduce a novel mean function for the probabilistic model. This results in augmenting BO methods with the action-value function. Hence, we call our method Augmented Bayesian Search~(ABS). Interestingly, this new mean function enhances the posterior gradient with the deterministic policy gradient, effectively bridging the gap between BO and policy gradient methods. The resulting algorithm combines the convenience of the direct policy search with the scalability of reinforcement learning. We validate ABS on high-dimensional locomotion problems and demonstrate competitive performance compared to existing direct policy search schemes.
Adaptive $Q$-Network: On-the-fly Target Selection for Deep Reinforcement Learning
May 25, 2024
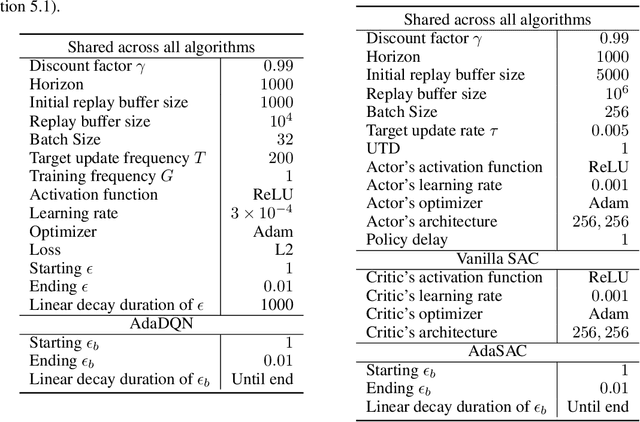

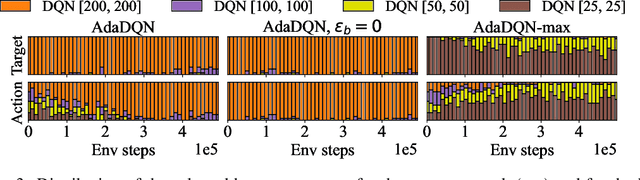
Deep Reinforcement Learning (RL) is well known for being highly sensitive to hyperparameters, requiring practitioners substantial efforts to optimize them for the problem at hand. In recent years, the field of automated Reinforcement Learning (AutoRL) has grown in popularity by trying to address this issue. However, these approaches typically hinge on additional samples to select well-performing hyperparameters, hindering sample-efficiency and practicality in RL. Furthermore, most AutoRL methods are heavily based on already existing AutoML methods, which were originally developed neglecting the additional challenges inherent to RL due to its non-stationarities. In this work, we propose a new approach for AutoRL, called Adaptive $Q$-Network (AdaQN), that is tailored to RL to take into account the non-stationarity of the optimization procedure without requiring additional samples. AdaQN learns several $Q$-functions, each one trained with different hyperparameters, which are updated online using the $Q$-function with the smallest approximation error as a shared target. Our selection scheme simultaneously handles different hyperparameters while coping with the non-stationarity induced by the RL optimization procedure and being orthogonal to any critic-based RL algorithm. We demonstrate that AdaQN is theoretically sound and empirically validate it in MuJoCo control problems, showing benefits in sample-efficiency, overall performance, training stability, and robustness to stochasticity.
Iterated $Q$-Network: Beyond the One-Step Bellman Operator
Mar 04, 2024


Value-based Reinforcement Learning (RL) methods rely on the application of the Bellman operator, which needs to be approximated from samples. Most approaches consist of an iterative scheme alternating the application of the Bellman operator and a subsequent projection step onto a considered function space. However, we observe that these algorithms can be improved by considering multiple iterations of the Bellman operator at once. Thus, we introduce iterated $Q$-Networks (iQN), a novel approach that learns a sequence of $Q$-function approximations where each $Q$-function serves as the target for the next one in a chain of consecutive Bellman iterations. We demonstrate that iQN is theoretically sound and show how it can be seamlessly used in value-based and actor-critic methods. We empirically demonstrate its advantages on Atari $2600$ games and in continuous-control MuJoCo environments.