 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeterministic Exploration via Stationary Bellman Error Maximization
Paper and Code
Oct 31, 2024

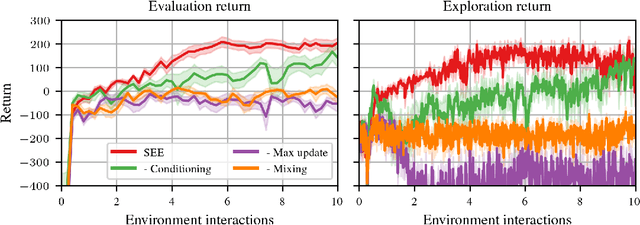
Exploration is a crucial and distinctive aspect of reinforcement learning (RL) that remains a fundamental open problem. Several methods have been proposed to tackle this challenge. Commonly used methods inject random noise directly into the actions, indirectly via entropy maximization, or add intrinsic rewards that encourage the agent to steer to novel regions of the state space. Another previously seen idea is to use the Bellman error as a separate optimization objective for exploration. In this paper, we introduce three modifications to stabilize the latter and arrive at a deterministic exploration policy. Our separate exploration agent is informed about the state of the exploitation, thus enabling it to account for previous experiences. Further components are introduced to make the exploration objective agnostic toward the episode length and to mitigate instability introduced by far-off-policy learning. Our experimental results show that our approach can outperform $\varepsilon$-greedy in dense and sparse reward settings.